SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
pip3 install sqlalchemy
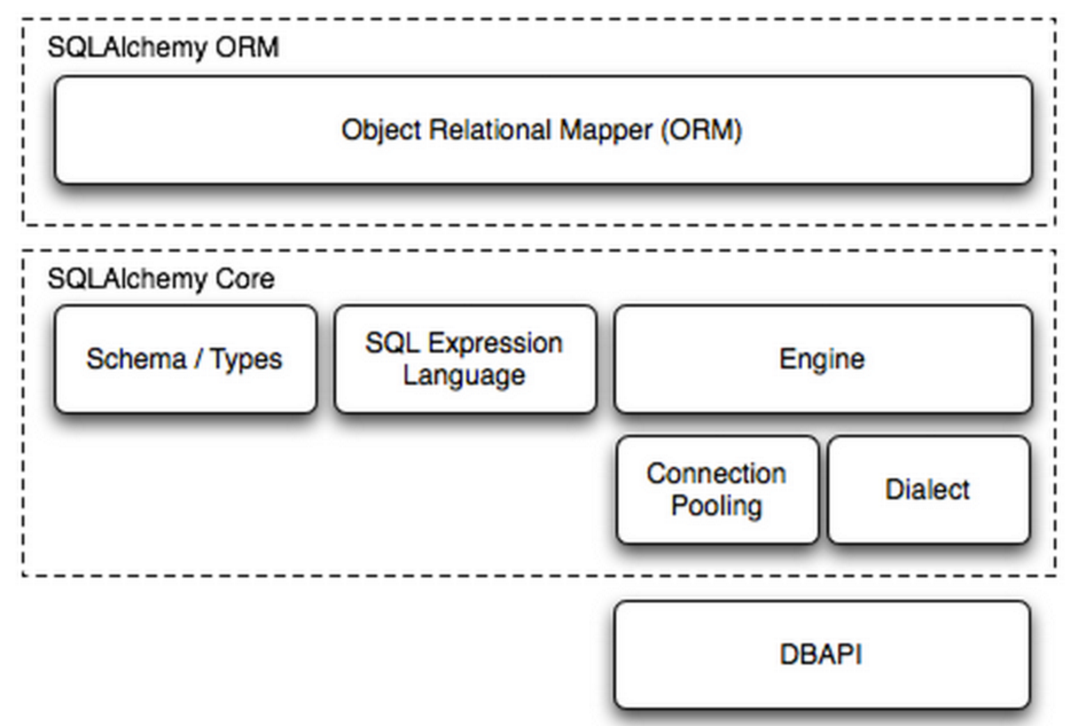
组成部分:
- Engine,框架的引擎
- Connection Pooling ,数据库连接池
- Dialect,选择连接数据库的DB API种类
- Schema/Types,架构和类型
- SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
1. 执行原生SQL语句


1 import time 2 import threading 3 import sqlalchemy 4 from sqlalchemy import create_engine 5 from sqlalchemy.engine.base import Engine 6 7 engine = create_engine( 8 "mysql+pymysql://root:123@127.0.0.1:3306/t1?charset=utf8", 9 max_overflow=0, # 超过连接池大小外最多创建的连接 10 pool_size=5, # 连接池大小 11 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 12 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 13 ) 14 15 16 def task(arg): 17 conn = engine.raw_connection() 18 cursor = conn.cursor() 19 cursor.execute( 20 "select * from t1" 21 ) 22 result = cursor.fetchall() 23 cursor.close() 24 conn.close() 25 26 27 for i in range(20): 28 t = threading.Thread(target=task, args=(i,)) 29 t.start()
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import time 4 import threading 5 import sqlalchemy 6 from sqlalchemy import create_engine 7 from sqlalchemy.engine.base import Engine 8 9 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=0, pool_size=5) 10 11 12 def task(arg): 13 conn = engine.contextual_connect() 14 with conn: 15 cur = conn.execute( 16 "select * from t1" 17 ) 18 result = cur.fetchall() 19 print(result) 20 21 22 for i in range(20): 23 t = threading.Thread(target=task, args=(i,)) 24 t.start()
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import time 4 import threading 5 import sqlalchemy 6 from sqlalchemy import create_engine 7 from sqlalchemy.engine.base import Engine 8 from sqlalchemy.engine.result import ResultProxy 9 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=0, pool_size=5) 10 11 12 def task(arg): 13 cur = engine.execute("select * from t1") 14 result = cur.fetchall() 15 cur.close() 16 print(result) 17 18 19 for i in range(20): 20 t = threading.Thread(target=task, args=(i,)) 21 t.start()
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import time 4 import threading 5 6 from sqlalchemy.ext.declarative import declarative_base 7 from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index 8 from sqlalchemy.orm import sessionmaker, relationship 9 from sqlalchemy import create_engine 10 from db import Users 11 12 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5) 13 Session = sessionmaker(bind=engine) 14 15 16 def task(arg): 17 session = Session() 18 19 obj1 = Users(name="alex1") 20 session.add(obj1) 21 22 session.commit() 23 24 25 for i in range(10): 26 t = threading.Thread(target=task, args=(i,)) 27 t.start() 28 29 多线程执行示例
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import time 4 import threading 5 6 from sqlalchemy.ext.declarative import declarative_base 7 from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index 8 from sqlalchemy.orm import sessionmaker, relationship 9 from sqlalchemy import create_engine 10 from db import Users 11 12 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5) 13 Session = sessionmaker(bind=engine) 14 15 16 def task(arg): 17 session = Session() 18 19 obj1 = Users(name="alex1") 20 session.add(obj1) 21 22 session.commit() 23 24 25 for i in range(10): 26 t = threading.Thread(target=task, args=(i,)) 27 t.start() 28 29 多线程执行示例
增
1 #新增一条数据 2 #原生sql:insert into mysql.hello_word(name,password) values("test2","1234"); 3 obj = User(name="test", password="1234") #生成你要创建的数据对象 4 session.add(obj) #把要创建的数据对象添加到这个session里, 一会统一创建 5 session.commit() #统一提交,创建数据,在此之前数据库是不会有新增数据的 6 7 #新增多条数据 8 #原生sql:insert into mysql.hello_word(name,password) values("test2","1234"),("test3","123"); 9 obj = User(name="test", password="1234") 10 obj1 = User(name="test", password="1234") 11 session.add_all([obj,obj1]) 12 session.commit()<br><br>#回滚,在session.add()之后,在session.commit()之前,想把添加至session缓存中的数据清除,使用rollback()函数回滚即可<br>Session.rollback()
删
1 #原生sql:mysql.hello_word where id > 5; 2 session.query(User).filter(User.id > 5).delete() #通过session查询User类,然后过滤出id>5的进行删除 3 session.commit() #提交
改
1 #①第一种方式 2 data = Session.query(User).filter_by(name="test1").first() #获取数据 3 data.name = "test" #修改数据 4 Session.commit() #提交 5 6 #②第二种方式,通过查找表,过滤条件,然后更新对应参数 7 session.query(User).filter(User.id > 15).update({"name": "test"}) 8 session.query(User).filter(User.id == 18).update({User.name: "hello"}, synchronize_session=False) 9 session.query(User).filter_by(name="test1").update({User.password: User.name}, synchronize_session="evaluate") 10 session.commit() 11 12 #③synchronize_session解释,用于query在进行delete or update操作时,对session的同步策略: 13 #1、synchronize_session=False,不对session进行同步,直接进行delete or update操作。 14 #2、synchronize_session="evaluate",在delete or update操作之前,用query中的条件直接对session的identity_map中的objects进行eval操作,将符合条件的记录下来, 在delete or update操作之后,将符合条件的记录删除或更新。
查
1 #原生sql:select * from mysql.hello_word; 2 ret = session.query(User).all() #查询所有 3 #也可以这样写: 4 ret = Session.query(User.name,User.id).all() 5 6 #原生slq:select name,password from mysql.hello_word; 7 ret = session.query(User.name, User.extra).all() #只查询name和extra字段所以所有数据 8 9 #原生sql:select * from mysql.hello_word where name="test1"; 10 ret = session.query(User).filter_by(name='test1').all() #查询name='alex'的所有数据 11 ret = session.query(User).filter_by(name='test1').first()#查询name='alex'的第一条数据 12 13 #查询id>5的name字段内容,且以id大小排序 14 #原生sql;select name from mysql.hello_word where id >5 order by id; 15 ret = session.query(User).filter(text("id>:value and name=:name")).params(value=5, name='test2').order_by(User.id).all() 16 17 #根据原生sql查询数据 18 ret = session.query(User).from_statement(text("SELECT * FROM hello_word where name=:name")).params(name='test1').all()
filter和filter_by使用的区别
1 #filter用于sql表达式查询过滤,如>,<, ==,等表达式 2 session.query(MyClass).filter(MyClass.name == 'some name') 3 #filter_by用于关键字查询过滤,如id=value,name=value 4 session.query(MyClass).filter_by(name = 'some name')
重构__repr__方法,将5.1 中ret内存对象按__repr__方法中定义的格式进行打印显示
1 class User(Base): 2 __tablename__ = "hello_word" # 表名 3 id = Column(Integer, primary_key=True) 4 name = Column(String(32)) 5 password = Column(String(64)) 6 7 def __repr__(self): # 使返回的内存对象变的可读 8 return "<id:{0} name:{1} password:{2}>".format(self.id, self.name, self.password) 9 10 #Base.metadata.create_all(connect) # 创建标结构 11 12 session_class = sessionmaker(bind=connect) # 创建与数据库的会话session class ,这里返回给session的是个class,不是实例 13 session = session_class() # 生成session实例 14 15 user = session.query(User).all() #查询全部 16 print(user) 17 18 #输出 19 [<id:1 name:test1 password:1234>, <id:2 name:test1 password:1234>, <id:8 name:test2 password:1234>, <id:9 name:test3 password:123>, <id:10 name:test4 password:123>, <id:11 name:test5 password:123>, <id:12 name:test2 password:1234>, <id:13 name:test3 password:123>, <id:14 name:test4 password:123>, <id:15 name:test5 password:123>, <id:16 name:test2 password:1234>, <id:17 name:test3 password:123>, <id:18 name:test4 password:123>, <id:19 name:test5 password:123>]
其他操作
1 #多条件查询 2 #原生sql:select * from mysql.hello_word where id >2 and id < 19 3 data = session.query(User).filter(Use.id>2).filter(Use.id<19).all() 4 5 #通配符 6 7 #原生sql:select * from mysql.hello_word where name like "test%" #"test_"、%test% 8 data = session.query(User).filter(User.name.like('test%')).all() #匹配以test开头,而后跟多个字符 9 data = session.query(User).filter(User.name.like('test_')).all() #匹配以test开头,而后跟一个字符 10 data = session.query(User).filter(~User.name.like('e%')).all() #加~后,忽略like(),直接匹配所有 11 #原生sql select count(name) from mysql.hello_word where name like "%test%" 12 data = session.query(User).filter(User.name.like("%qigao%")).count() # 模糊匹配并计数 13 14 #分组 15 16 from sqlalchemy import func #导入func 进行函数操作 17 #原生sql:select count(name),name from mysql.hello_word group by name 18 data =session.query(func.count(User.name),User.name).group_by(User.name).all() #根据User.name分组 19 #原生sql:select max(id),sum(id),min(id) from mysql.hello_word group by name #根据name 分组 20 data =session.query(func.max(User.id),func.sum(User.id),func.min(User.id)).group_by(User.name).all() 21 #原生sql:select max(id),sum(id),min(id) from mysql.hello_word group by name having min(id > 2) # 根据name分组且id>2 22 data = session.query(func.max(User.id),func.sum(User.id),func.min(User.id)).group_by(User.name).having(func.min(User.id) >2).all() 23 24 #排序 25 26 #原生sql:select * from mysql.hello_word order by id asc 27 data = session.query(User).order_by(User.id.asc()).all() #将所有数据根据 “列” 从小到大排列 28 #原生sql:select * from mysql.hello_word order by id desc, id asc 29 data = session.query(User).order_by(User.id.desc(), User.id.asc()).all()#将所有数据根据 “列1” 从大到小排列,如果相同则按照“列2”由小到大排列 30 31 32 #条件表达式 in、between、 and 、or 33 data = session.query(User).filter_by(name='test').all() 34 data = session.query(User).filter(User.id > 1, Users.name == 'test').all() 35 data = session.query(User).filter(User.id.between(1, 3), Users.name == 'test').all() 36 data = session.query(User).filter(User.id.in_([1,3,4])).all() 37 data = session.query(User).filter(~User.id.in_([1,3,4])).all() 38 data = session.query(User).filter(Users.id.in_(session.query(User.id).filter_by(name='test'))).all() 39 40 from sqlalchemy import and_, or_ 41 data = session.query(User).filter(and_(User.id > 3, Users.name == 'test')).all() 42 data = session.query(User).filter(or_(User.id < 2, Users.name == 'test')).all() 43 data = session.query(User).filter(or_(User.id < 2,and_(User.name == 'test',User.id > 3),User.password != "")).all()
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import time 4 import threading 5 6 from sqlalchemy.ext.declarative import declarative_base 7 from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index 8 from sqlalchemy.orm import sessionmaker, relationship 9 from sqlalchemy import create_engine 10 from sqlalchemy.sql import text 11 from sqlalchemy.engine.result import ResultProxy 12 from db import Users, Hosts, Hobby, Person 13 14 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5) 15 Session = sessionmaker(bind=engine) 16 session = Session() 17 # 添加 18 """ 19 session.add_all([ 20 Hobby(caption='乒乓球'), 21 Hobby(caption='羽毛球'), 22 Person(name='张三', hobby_id=3), 23 Person(name='李四', hobby_id=4), 24 ]) 25 26 person = Person(name='张九', hobby=Hobby(caption='姑娘')) 27 session.add(person) 28 29 hb = Hobby(caption='人妖') 30 hb.pers = [Person(name='文飞'), Person(name='博雅')] 31 session.add(hb) 32 33 session.commit() 34 """ 35 36 # 使用relationship正向查询 37 """ 38 v = session.query(Person).first() 39 print(v.name) 40 print(v.hobby.caption) 41 """ 42 43 # 使用relationship反向查询 44 """ 45 v = session.query(Hobby).first() 46 print(v.caption) 47 print(v.pers) 48 """ 49 50 session.close() 51 52 基于relationship操作ForeignKey
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import time 4 import threading 5 6 from sqlalchemy.ext.declarative import declarative_base 7 from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index 8 from sqlalchemy.orm import sessionmaker, relationship 9 from sqlalchemy import create_engine 10 from sqlalchemy.sql import text 11 from sqlalchemy.engine.result import ResultProxy 12 from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group 13 14 engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5) 15 Session = sessionmaker(bind=engine) 16 session = Session() 17 # 添加 18 """ 19 session.add_all([ 20 Server(hostname='c1.com'), 21 Server(hostname='c2.com'), 22 Group(name='A组'), 23 Group(name='B组'), 24 ]) 25 session.commit() 26 27 s2g = Server2Group(server_id=1, group_id=1) 28 session.add(s2g) 29 session.commit() 30 31 32 gp = Group(name='C组') 33 gp.servers = [Server(hostname='c3.com'),Server(hostname='c4.com')] 34 session.add(gp) 35 session.commit() 36 37 38 ser = Server(hostname='c6.com') 39 ser.groups = [Group(name='F组'),Group(name='G组')] 40 session.add(ser) 41 session.commit() 42 """ 43 44 45 # 使用relationship正向查询 46 """ 47 v = session.query(Group).first() 48 print(v.name) 49 print(v.servers) 50 """ 51 52 # 使用relationship反向查询 53 """ 54 v = session.query(Server).first() 55 print(v.hostname) 56 print(v.groups) 57 """ 58 59 60 session.close() 61 62 基于relationship操作m2m