Spark权威指南读书笔记(四) 聚合与连接
一、聚合函数
大多数聚合函数位于org.apache.spark.sql.functions。当给定多个输入值时,聚合函数给每个分组计算出一个结果。
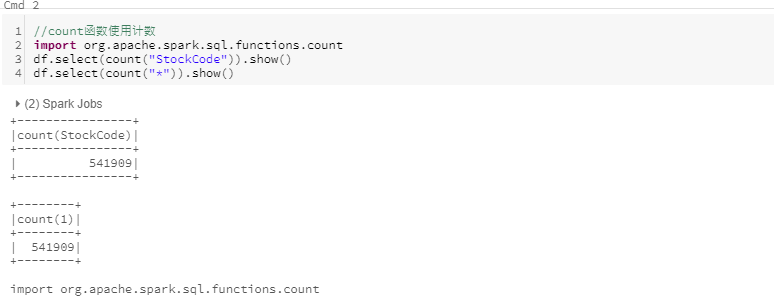
count
使用count对指定列进行计数或者使用count(*)或count(1)对所有列进行计数。需要注意的是,当执行count(*)时,Spark会对null值进行计数;而当对某指定列计数时,则不会对null值进行计数。
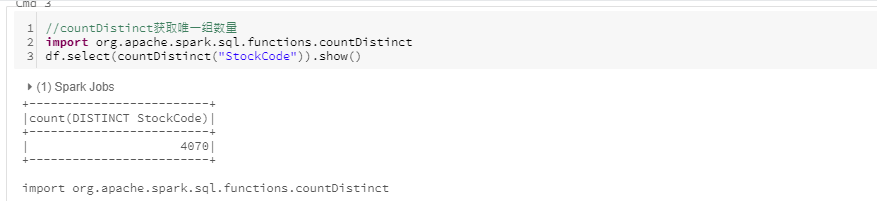
countDistinct
获取某列的唯一值数量计数
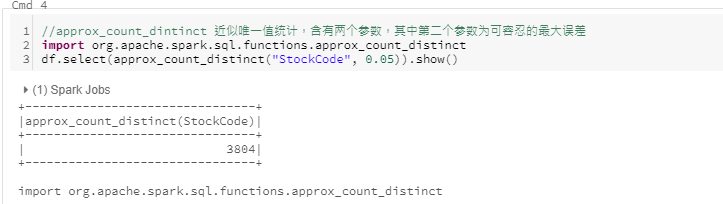
approx_count_distinct
在处理大数据计算时,获得 一个精确的结果开销会很大,但是计算一个近似结果相对容易很多。此时可使用approx_count_distinct。approx_count_distinct具有两个参数,第一个为列,第二个参数指定可容忍的最大误差。
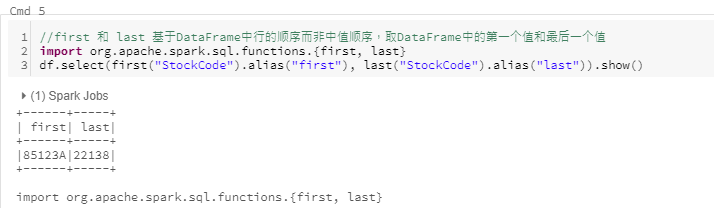
**first 和 last **
基于DataFrame行的顺序而非中值顺序,获取DataFrame的第一个值和最后一个值。
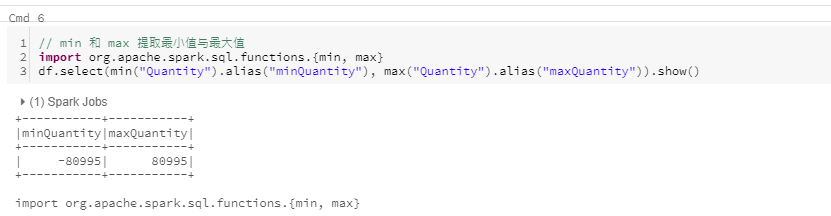
min 和 max
从DataFrame中获取最小值和最大值
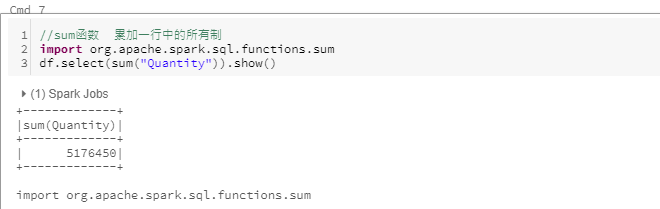
sum
累加一行中的所有值
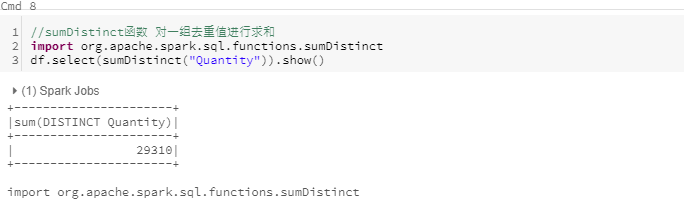
sumDistinct
对一组去重值进行求和
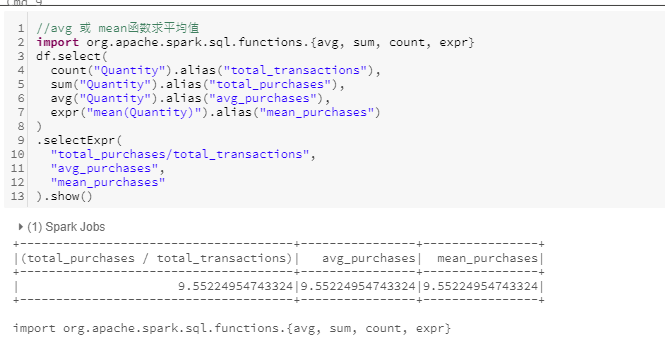
avg
使用avg或mean方法获取平均值
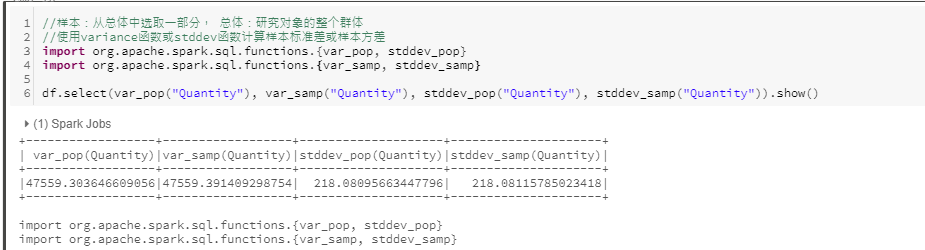
方差与标准差
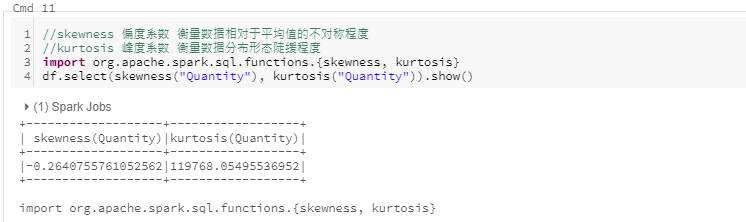
偏度系数(skewness)与峰度系数(kurtosis)
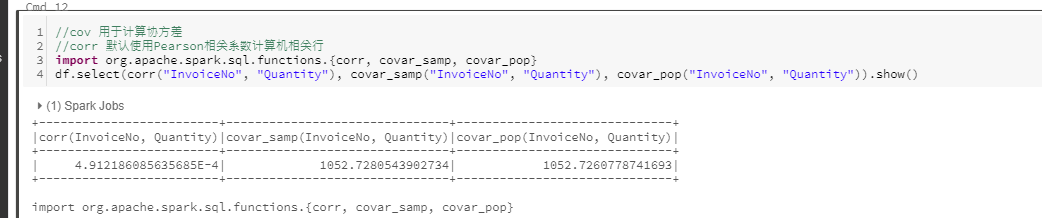
协方差与相关性
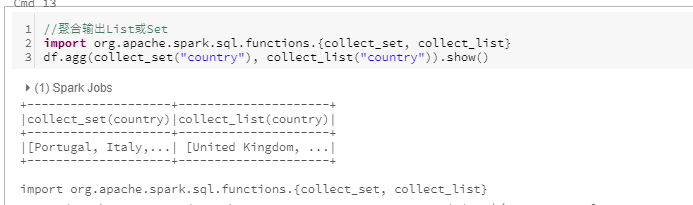
聚合输出复杂类型
二、分组
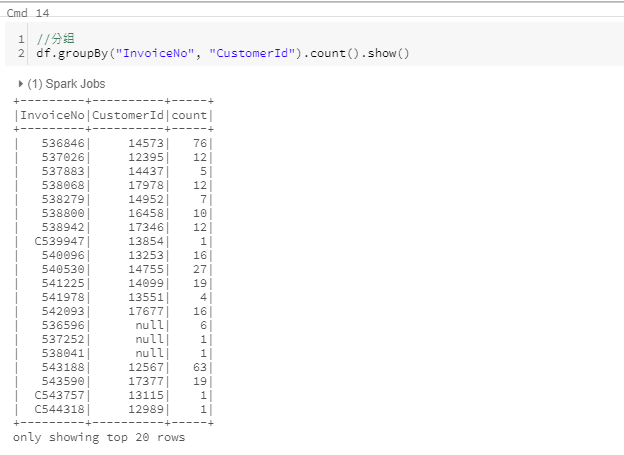
分组 groupBy
分两个阶段进行分组,首先指定要对其分组的一列或多列,然后指定一个或多个聚合操作。第一步返回一个RelationalGroupedDataset,第二步返回 DataFrame。
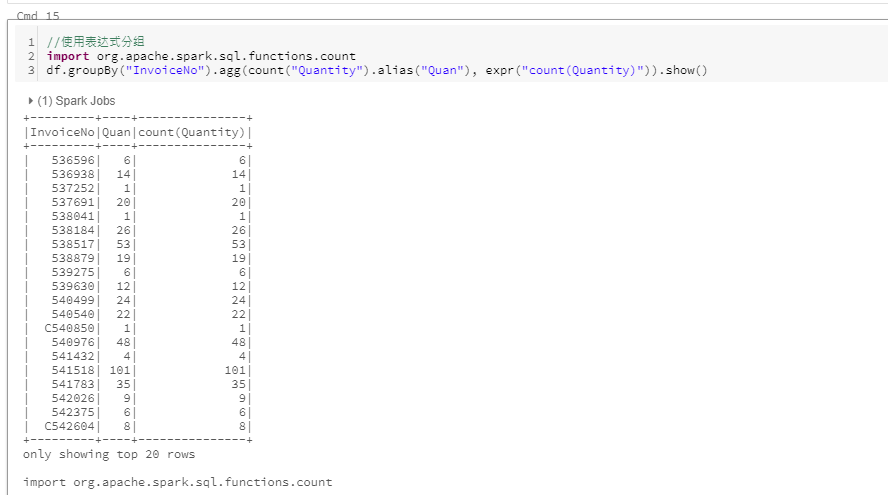
使用表达式分组
使用Map进行分组
转换操作指定一系列Map更方便,其中键为列,值为要执行的字符串形式的聚合函数。若以inline方式指定可重用多个列名。
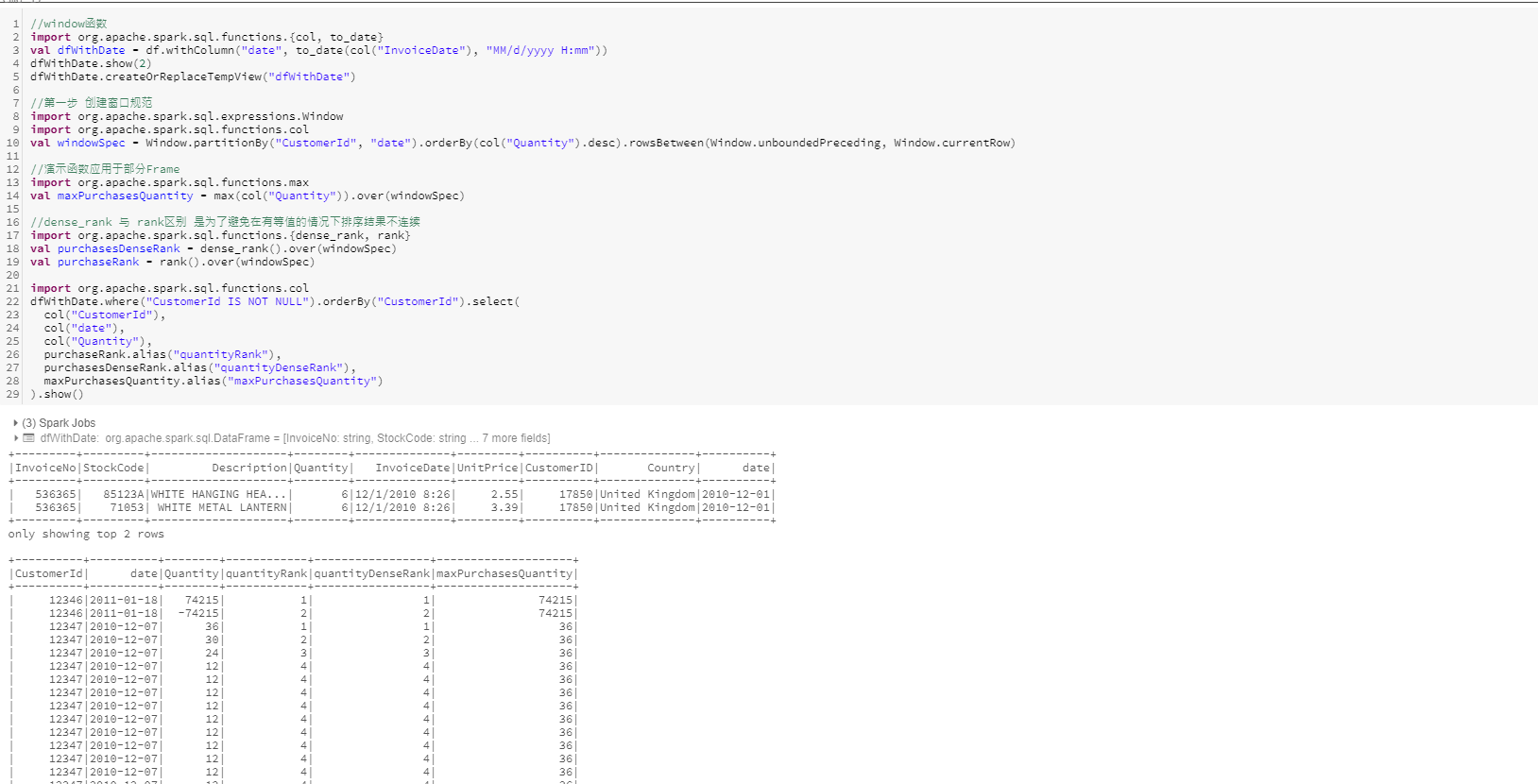
window函数
window函数具体是指在指定数据窗口上执行聚合操作,并使用对当前数据的引用来定义它,此窗口指定将哪些行传递给此函数。不同于groupBy处理数据分组的方式 每一行只能进入一个分组,窗口函数基于Frame的一组行,计算表中的每一输入行的返回值,每一行属于一个或多个Frame。
配置窗口函数第一步是创建一个窗口规范。
rowsBetween参数说明
rowBetween含有两参数,第一个参数指定操作起始位置,第二个参数指定操作的最后位置。
Window.unboundPreceding 分区开始位置
Window.currentRow 分区计算当前位置
Window.unboundedFollowing 分区的最后位置
负数 — 前有元素的情况下向前追加
0 — 等价于currentRow
正数 — 后有元素的情况下向后追加
分组集
分组集用于多组聚合操作组合在一起的底层工具,使得能够在group-by语句中创建任意得聚合操作。
注:分组集取决于聚合级别的null值,如果不过滤空值,则会得到不正确的结果。
rollup
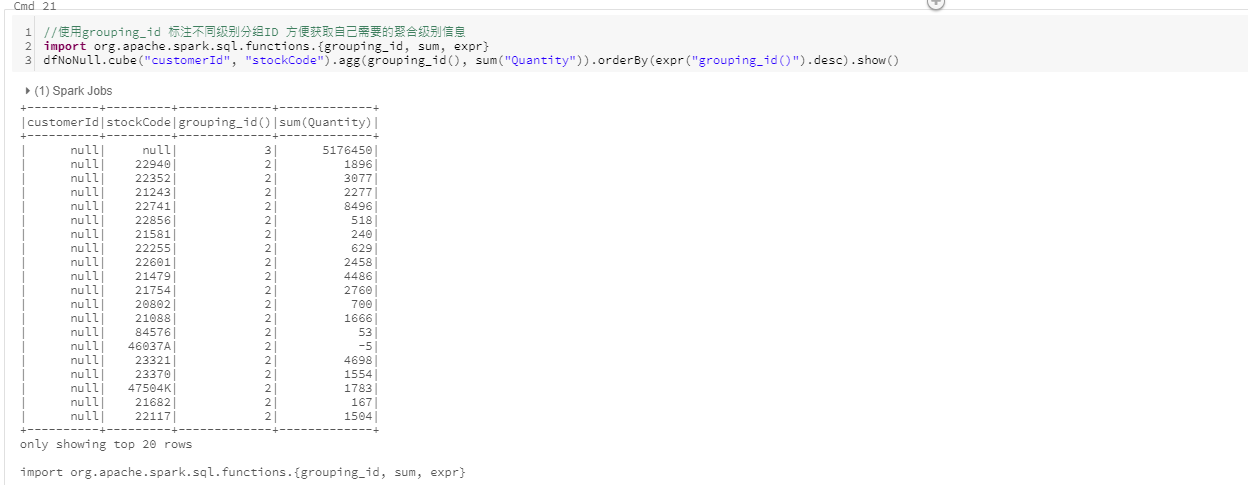
cube
使用grouping_id对元数据分组
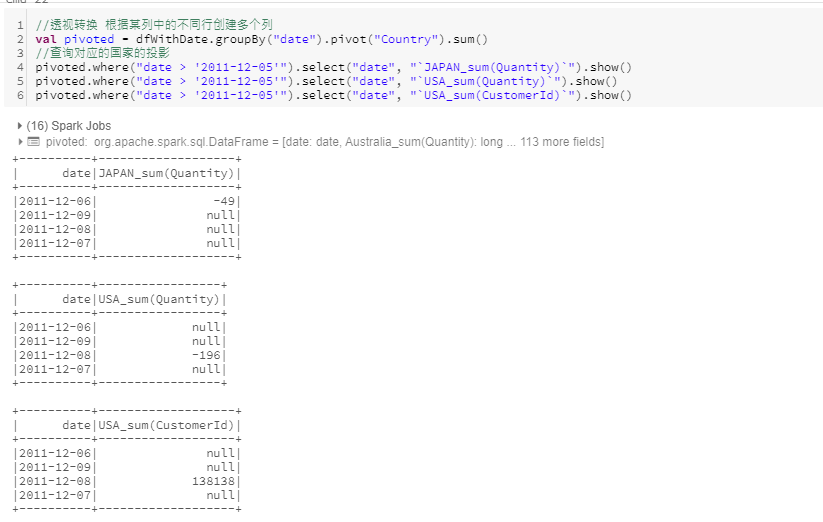
透视转换
使用透视转换后,DataFrame会为每一个Country和数值类型列组合产生一个新列。




三、用户自定义聚合函数UDAF
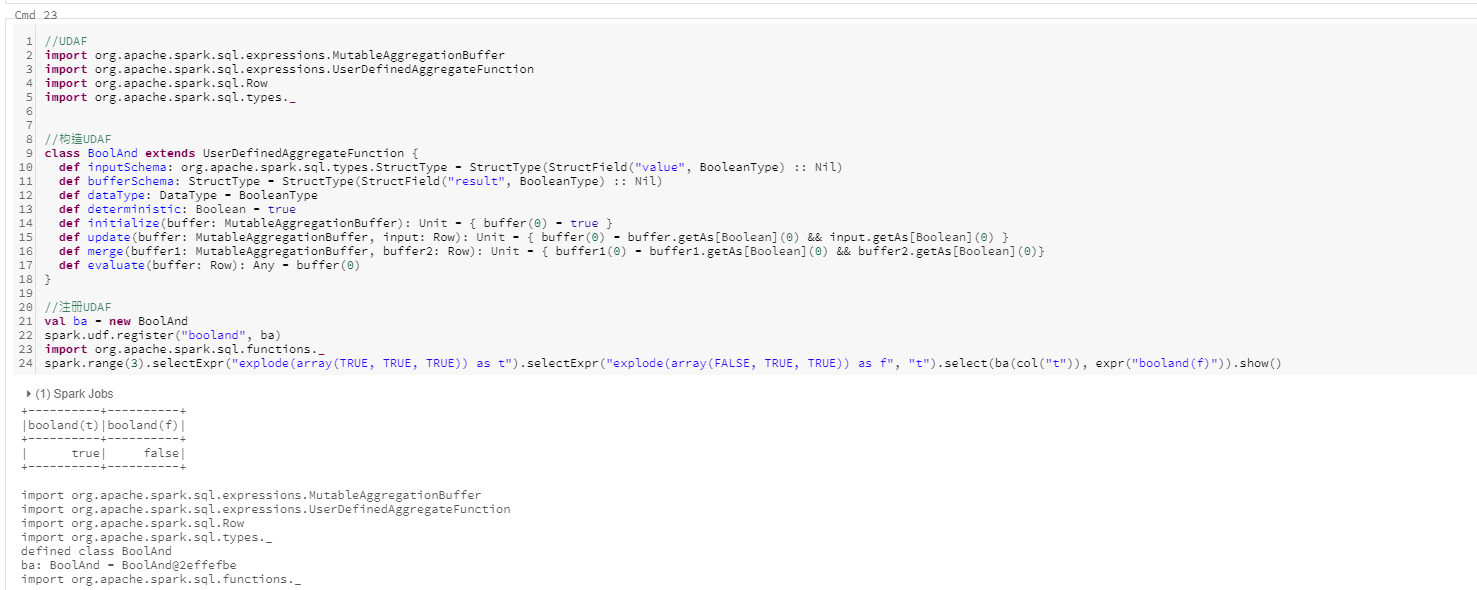
UDAF是用户根据自定义公式或业务逻辑定义自己的聚合函数的一种。可以使用UDAF计算输入数据组(与单行相对)的自定义计算。Spark维护单个AggregateBuffer,用于存储每组输入数据的中间结果。
若要创建UDAF,必须继承UserDefineAggregateFunction基类实现以下方法:
- inputSchema用于指定输入参数,输入参数类型为StructType
- bufferSchema用于指定UDAF中间结果,中间结果类型为StructType
- dataType用于指定返回结果,返回结果类型为DataType
- deterministic是一个布尔值,它指定此UDAF对于某个输入是否会返回相同的结果
- initialize初始化聚合缓冲区的初始值
- update描述应如何根据给定行更新内部缓冲区
- merge描述应如何合并两个聚合缓冲区
- evaluate将生成聚合最终结果
四、连接
连接类型
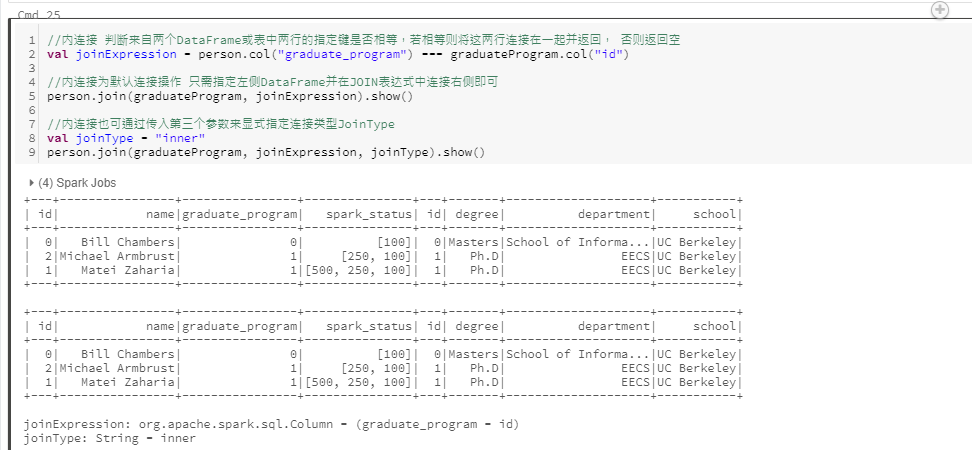
- inner join: 内部连接,保留左、右数据集内某个键都存在的行
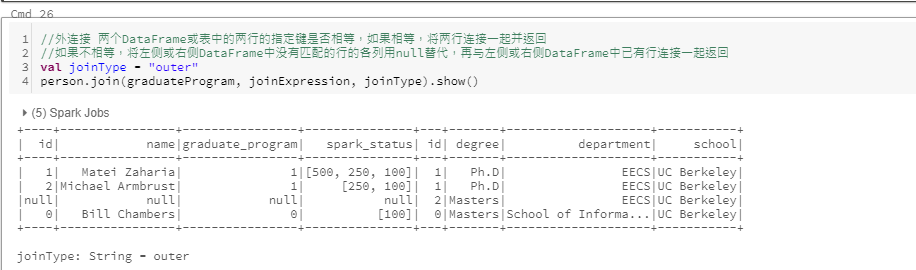
- outer join:外部连接, 保留左侧或右侧数据集中具有某个键的行
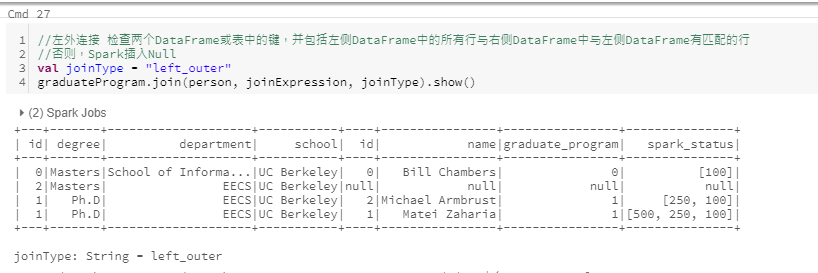
- left outer join:左外部连接, 保留左侧数据集中具有某个键的行
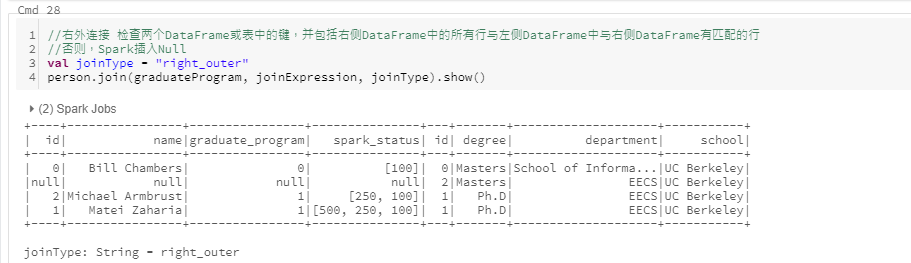
- right outer join: 右外部连接, 保留右侧数据集中具有某个键的行
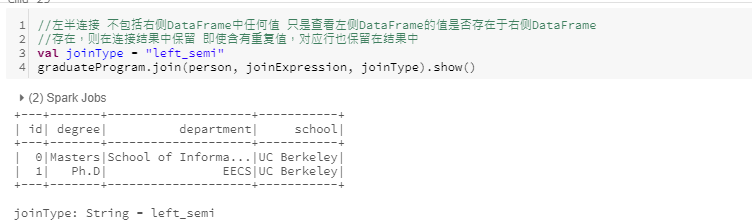
- left semi join: 左半连接,如果某键在右侧数据行中出现,则保留且仅保留左侧数据行
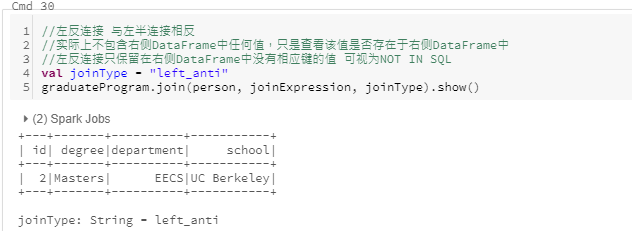
- left anti join:左反连接, 如果某键在右侧数据行中没出现,则保留且仅保留左侧数据行
- natural join: 自然连接, 通过隐式匹配两个数据集之间具有相同名称的列来执行连接
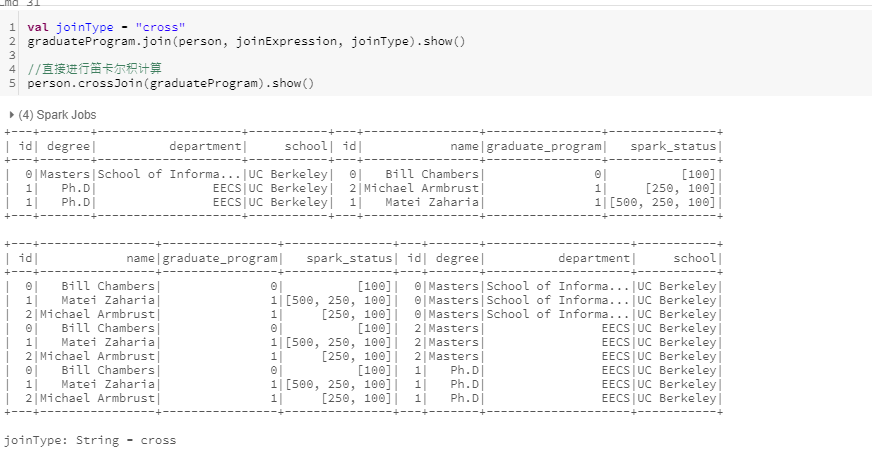
- cross join:笛卡尔连接,又称为交叉连接,将左侧数据集中的每一行与右侧数据集中每一行匹配
内连接
外连接
左外连接
右外连接
左半连接
左反连接
笛卡尔连接
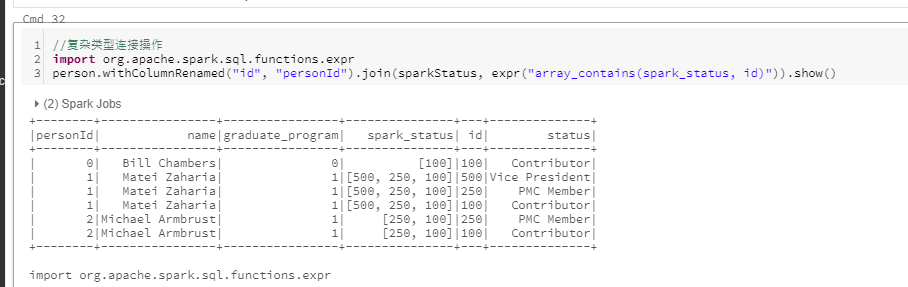
复杂类型连接操作
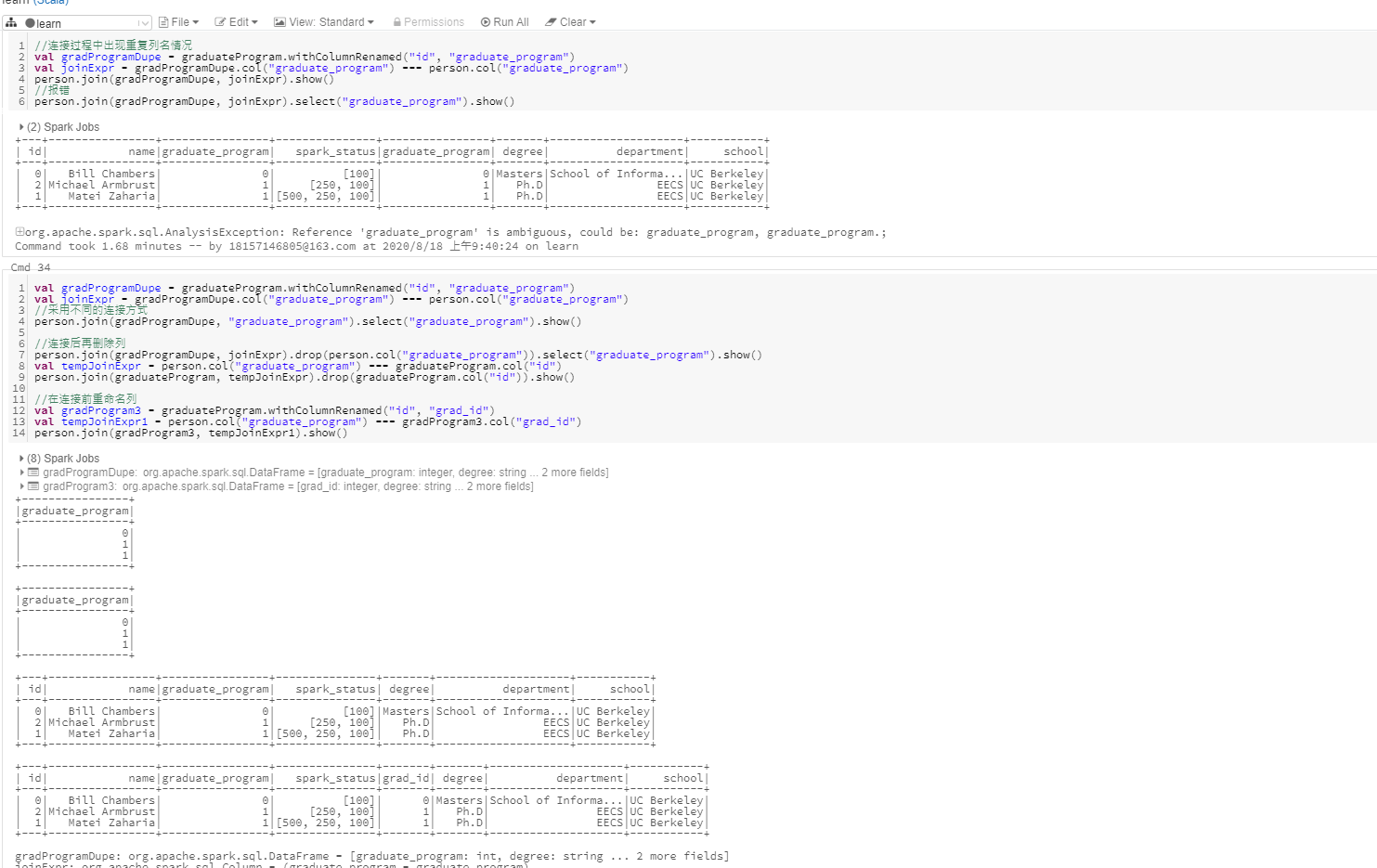
处理连接中的重复列
五、Spark通信策略
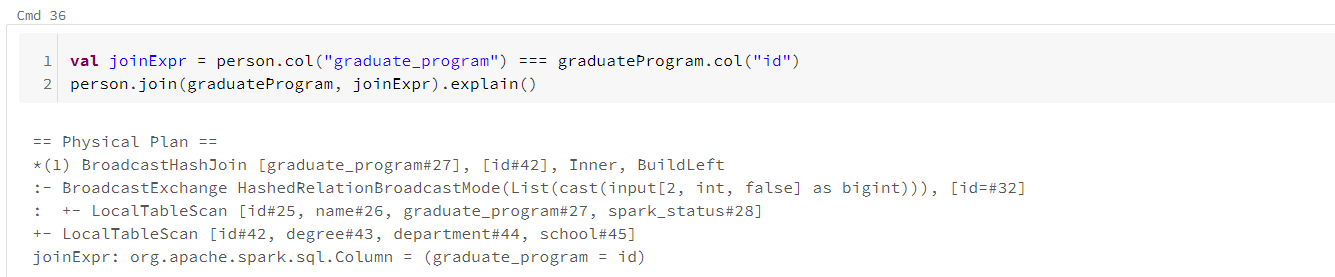
在连接过程中,Spark以两种不同方式处理集群通信问题。要么执行导致all-to-all通信的shuffle join, 要么采用broadcast join。
大表与大表连接(shuffle join)
大表连接大表时,执行shuffle join。则每个结点都与所有其他结点进行通信,并根据哪个结点具有用于连接的某个键或某一组键来共享数据。由于网络会因通信量而阻塞,所以这种方式很耗时,特别是如果数据没有合理分区的情况下
大表与小表连接(broadcast join)
通过将数据量较小的DataFrame复制到集群中的所有工作结点上,只需开始时执行一次,然后让每个工作节点独立执行作业,无需等待其他工作节点,无需与其他工作结点通信。
通过DataFrame API可以显式告知优化器,使用broadcast函数作用于较小的DataFrame上,并执行广播通信模式的连接操作。
小表与小表连接
最好让Spark自行决定
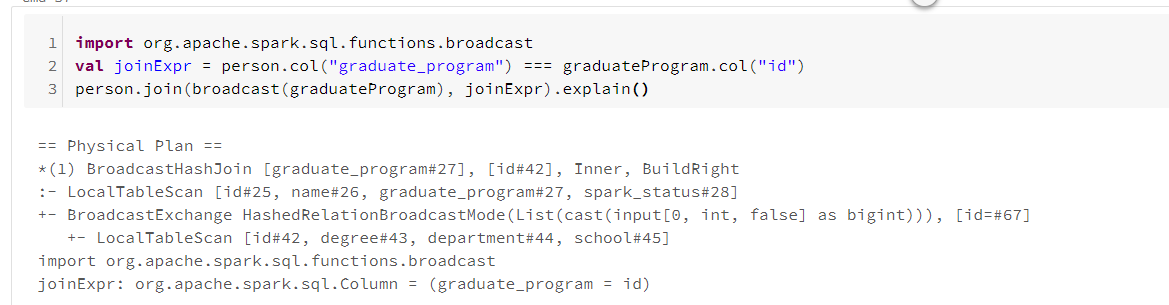
六、补充 SparkSQL join的三种实现
这部分内容参考博客:https://www.linkedin.com/pulse/spark-sql-3-common-joins-explained-ram-ghadiyaram
http://hbasefly.com/2017/03/19/sparksql-basic-join/
先说结论:
- Broadcast Hash Join 适合一张较小的表与一张大表进行join
- Shuffle Hash Join 适合一张小表和一张大表进行join,或者两张小表之间的join
- Sort Merge Join: 适合两张较大的表进行join
注:前两者基于Hash Join, 不同点在于优先进行Shuffle或Broadcast。
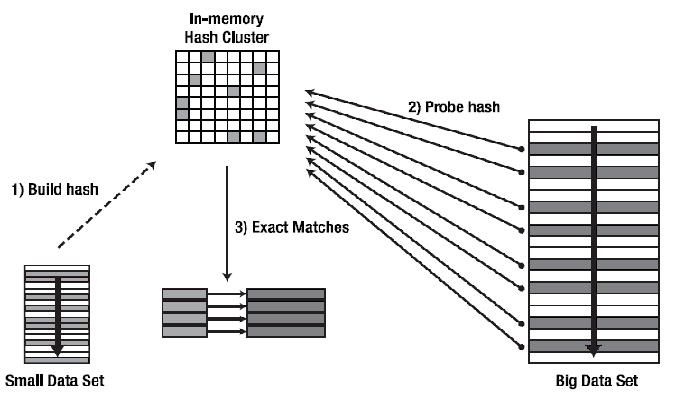
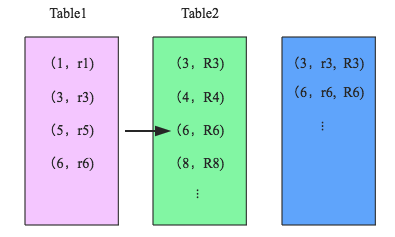
Hash Join
整个过程分为三步:
- 确定BuildTable,ProbeTable。BuildTable使用join key构建Hash Table,Probe Table使用join key进行探测,探测成功则可Join。通常情况下,小表为BuildTable, 大表为ProbeTable。
- 构建HashTable。依次读取BuildTable的数据,对于每一行数据根据join key进行hash,hash到对应的Bucket,生成HashTable中的一条记录,数据缓存在内存中,若内存放不下需要dump到外存。
- 探测。再依次扫描ProbeTable数据,使用相同的hash函数映射HashTable中记录。映射成功后再检测Join条件,若匹配成功,则将二者进行Join。
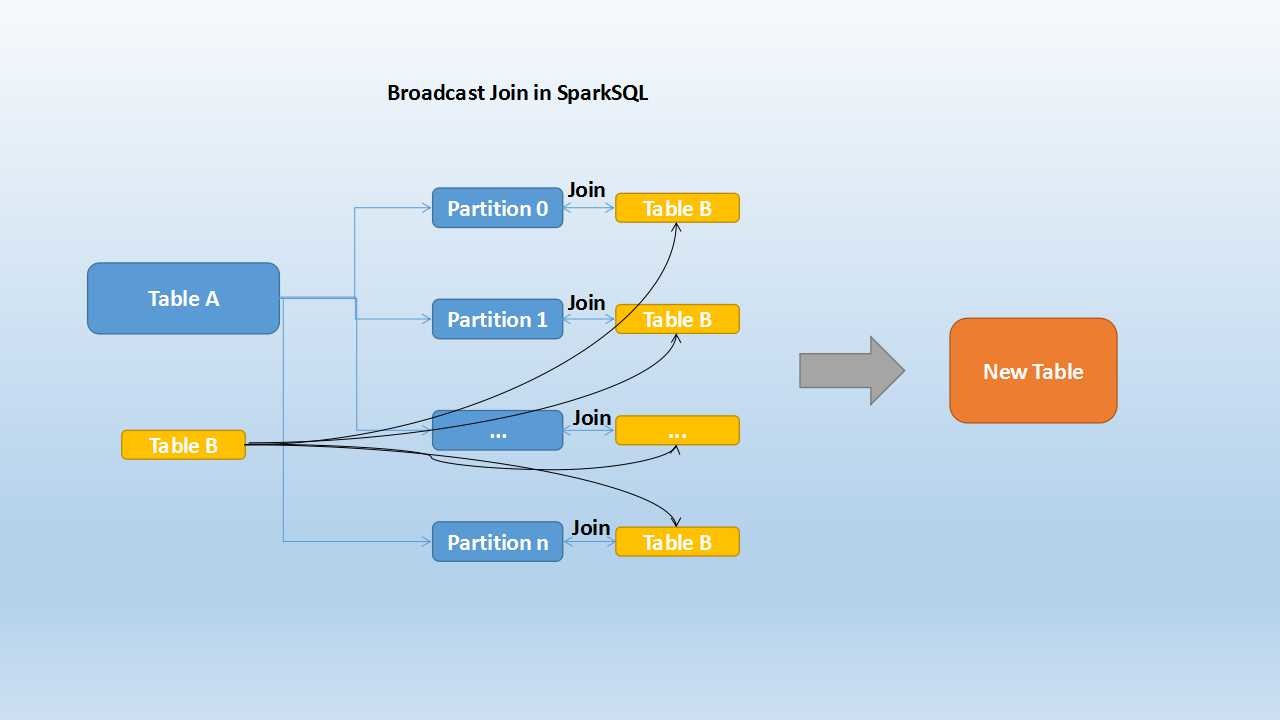
broadcast join(广播表要足够小)
broadcast Join的条件:
- 被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
- 基表不能被广播,如left outer join,只能广播右表
broadcast join步骤:
- broadcast阶段:将小表广播分发到大表所在的所有结点。
- hash join阶段:在每个executor上执行单机版hash join,小表映射,大表试探
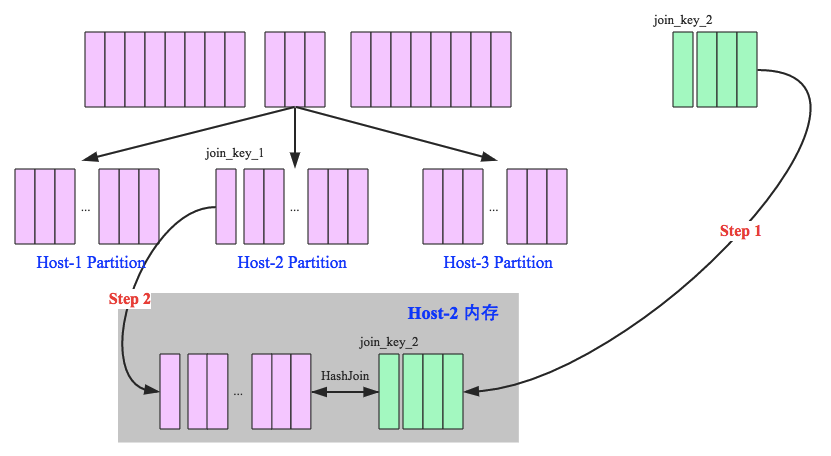
shuffle hash join
shuffle hash join的条件:
- 分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
- 基表不能被广播,比如left outer join时,只能广播右表
- 一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小,此处为经验值)
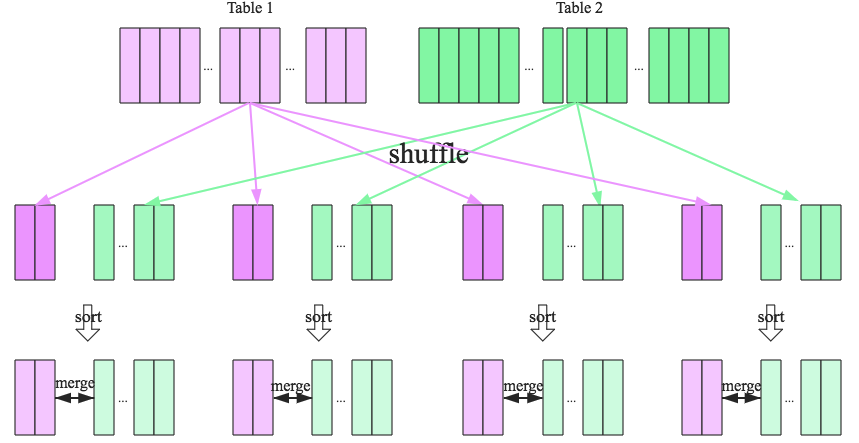
shuffle hash join步骤:
- 对两张表分别按照join keys进行重分区,即shuffle,目的是为了让有相同join keys值的记录分到对应的分区中
- 对对应分区中的数据进行join,对各个分区内先将小表分区构造为一张hash表,然后根据大表分区中记录的join keys值拿出来进行匹配
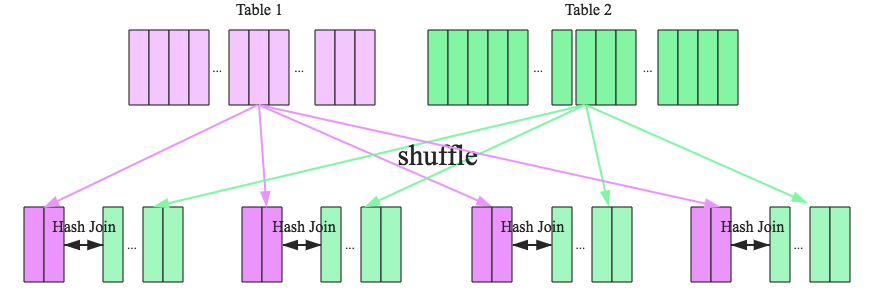
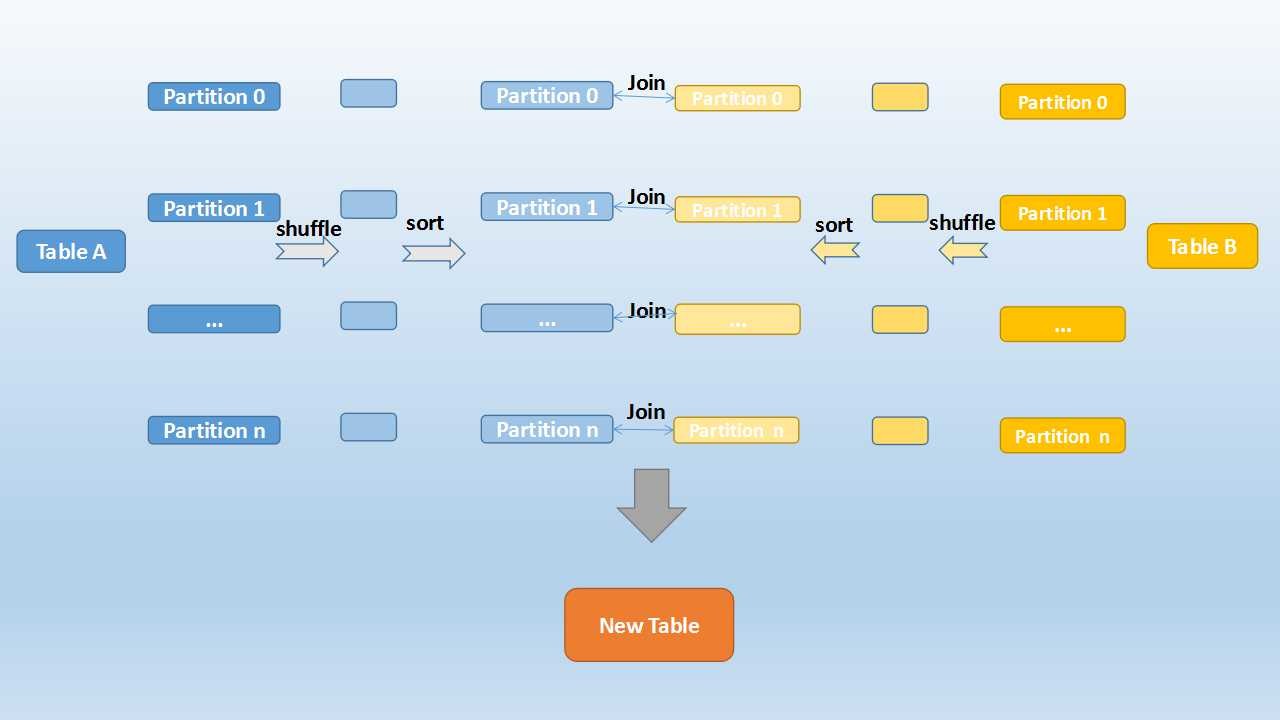
sort merge join
sort merge join步骤:
- shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理
- sort阶段:对单个分区节点的两表数据,分别进行排序
- merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边