参考:
https://blog.csdn.net/qq_41664845/article/details/84245520#t5
https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
论文题目:Neural Machine Translation by Jointly Learning to Align and Translate
论文地址:http://pdfs.semanticscholar.org/071b/16f25117fb6133480c6259227d54fc2a5ea0.pdf
这篇论文在传统的encoder-decoder的NMT上加了attention机制。
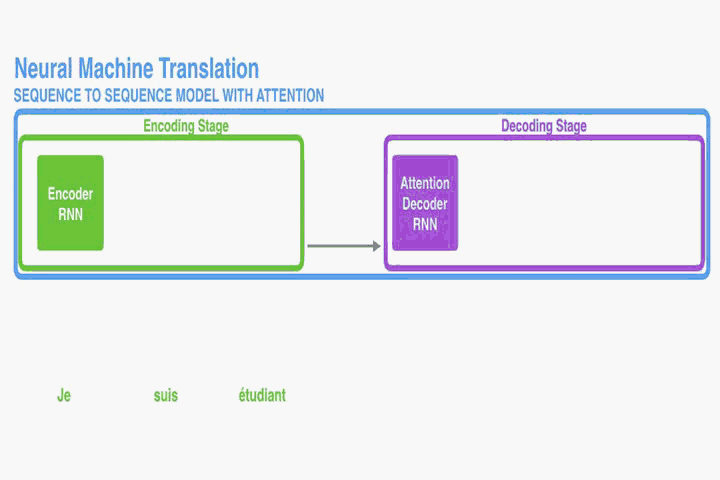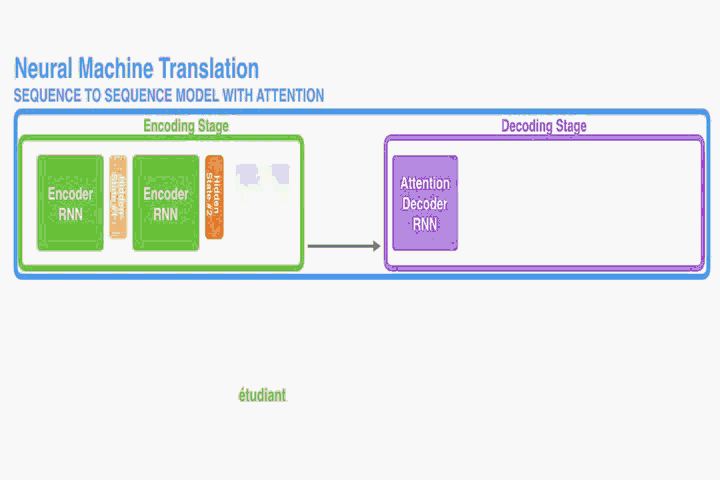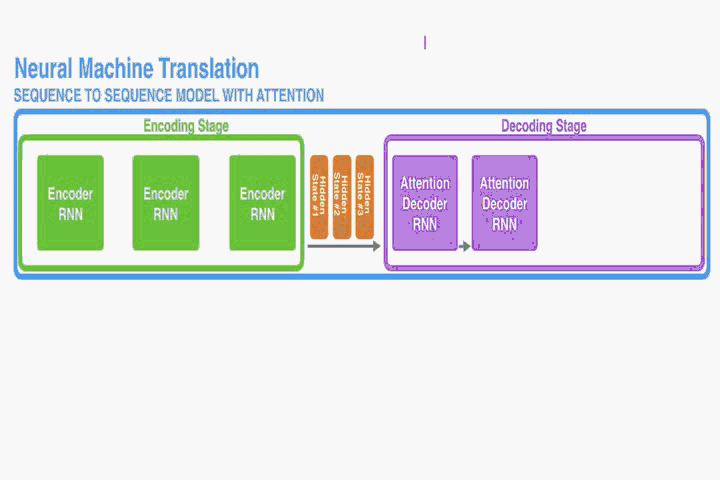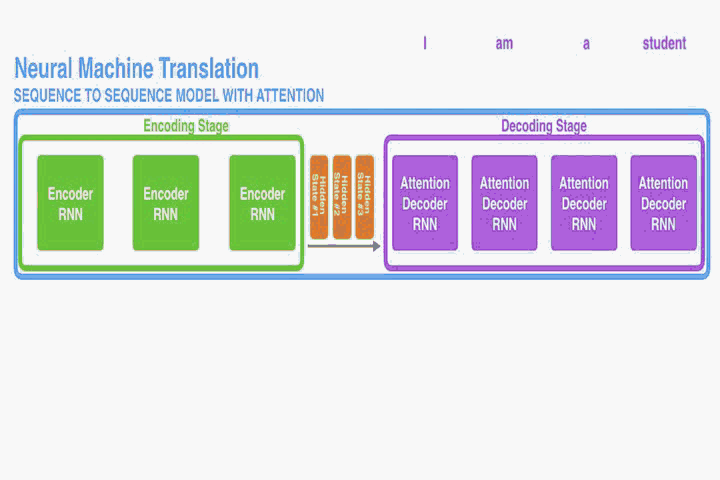
encoder-decoder for NMT:
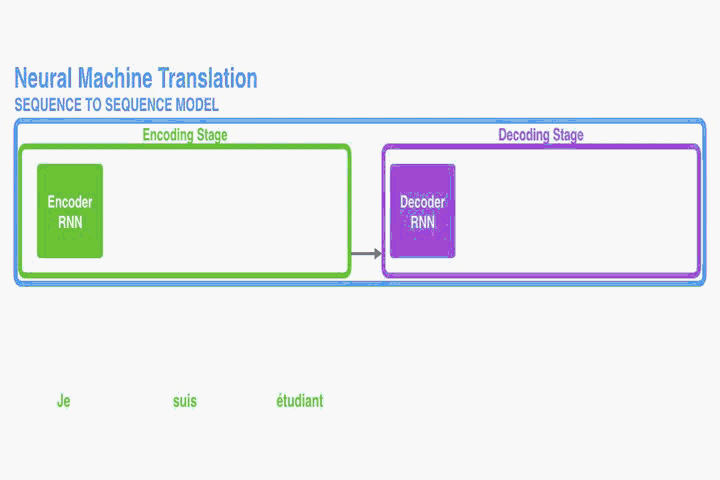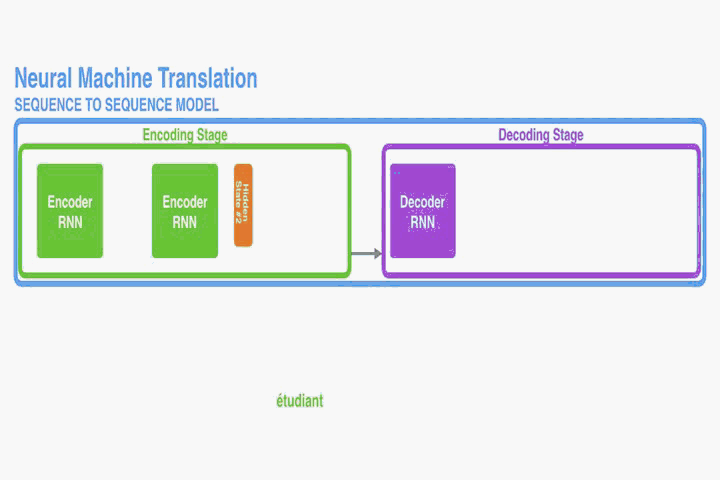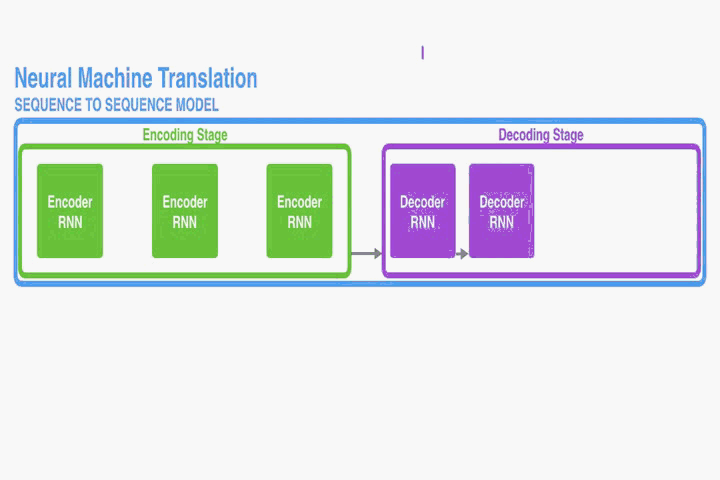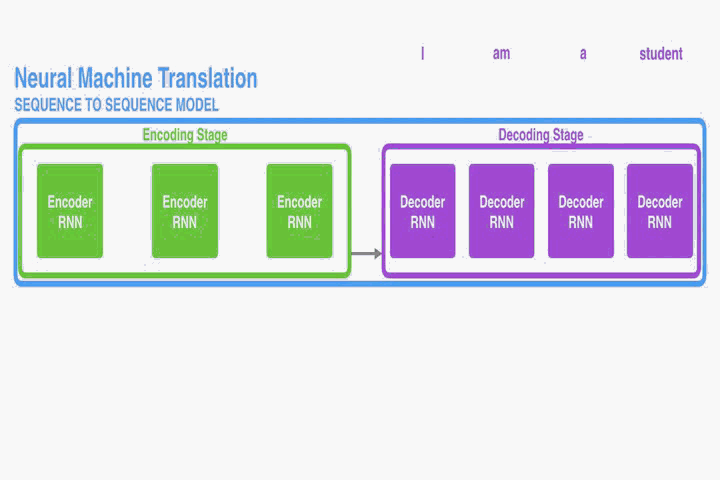
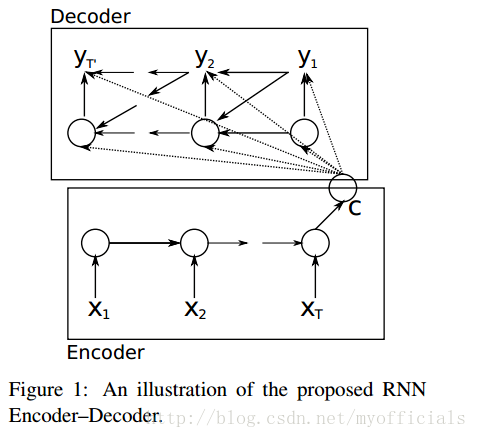
在encoder中,只有单层RNN。每个time step t,
ht = f(xt, ht-1) 其中xt是输入语句中的第t个word,ht是第t时刻的隐藏状态。
所以time step的数量和输入语句的长度应该相同,都是T。
最后输出给decoder的context(c),就是第T时刻的隐藏状态hT。
所以hT很容易成为瓶颈。
在decode(也是单层RNN)r中,每个time step的输入是context(c)和上一个time step的隐藏状态。
我们就主要来讲一讲加上的attention。
改动一:The encoder passes all the hidden states to the decoder
context的size是T*nums_units_of_RNN
从而规避了hT瓶颈的问题
改动二:在decoder上加了attention
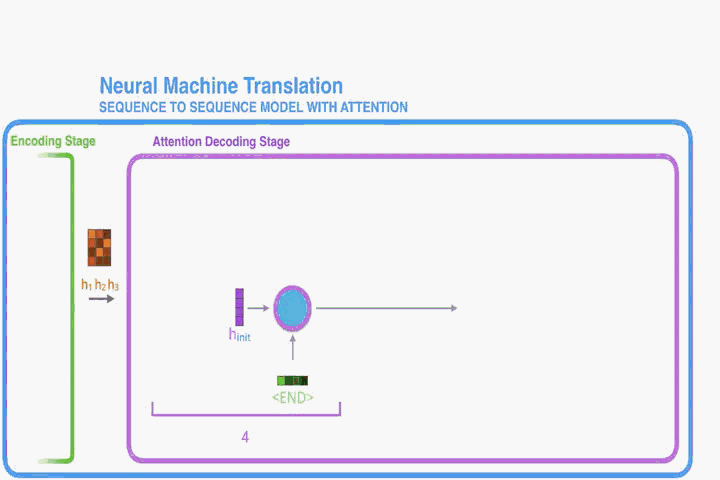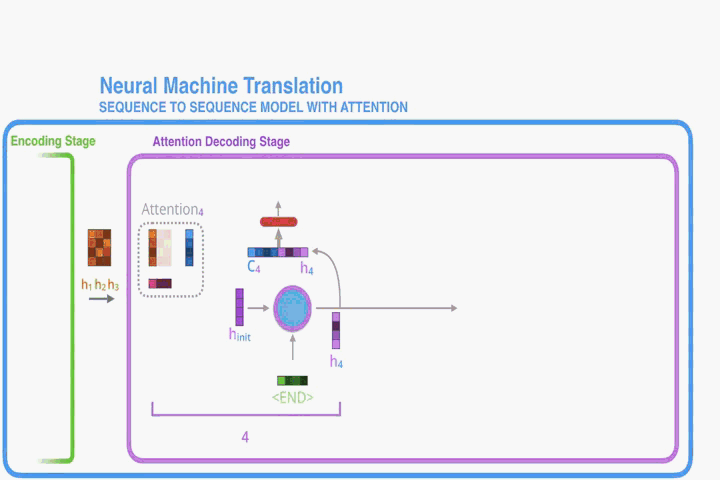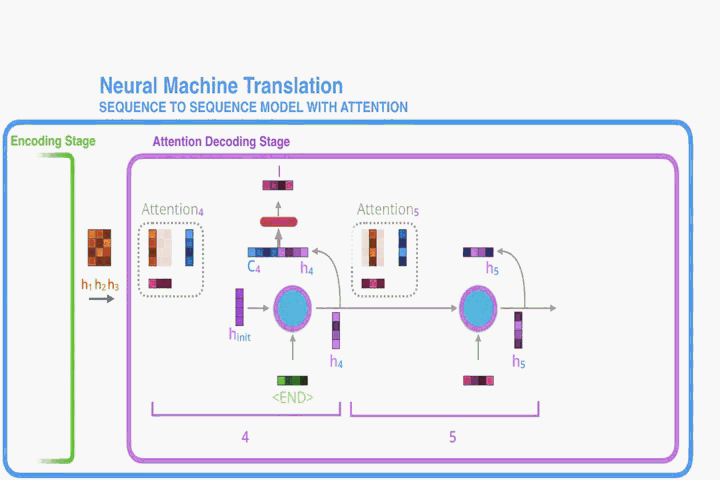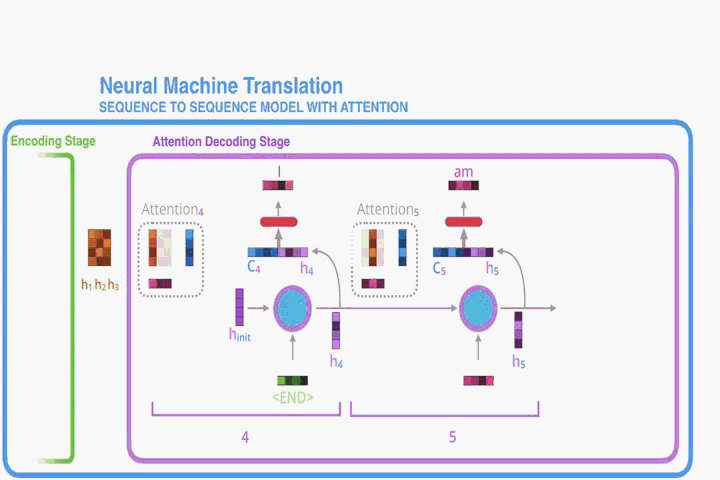
Let us now bring the whole thing together in the follows:
- The attention decoder RNN takes in the embedding of the
- The RNN processes its inputs, producing an output and a new hidden state vector (h4). The output is discarded.
- Attention Step: We use the encoder hidden states and the h4 vector to calculate a context vector (C4) for this time step.
- We concatenate h4 and C4 into one vector.
- We pass this vector through a feedforward neural network (one trained jointly with the model).
- The output of the feedforward neural networks indicates the output word of this time step.
- Repeat 2~6
其中除了第一个time step,其余time step都接受上个time step的隐藏状态以及输出结果。
其中3.Attention Step是:
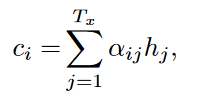

attention就是加权平均,相关度eij(aij)大的,αij*hj也大,让更相关的hj有更大的“发言权”。
eij作为衡量ci和hj的相关系数,也是通过NN计算得来的,给与了很大的自由权衡的“便宜行事权”,所以能形成下图中的局部倒序的对应关系(European Economic Area)。

可见这里的attention计算复杂度达到了3次方,相比原来增大了很多计算量。
改进三:Encoder中使用Bi-RNN代替RNN。