一. UML中几种类间关系:继承、实现、依赖、关联、聚合、组合的联系与区别(转自http://blog.csdn.net/hjfjoy/archive/2009/04/07/4053700.aspx)
UML中的关系
1、 关联关系
关联关系连接元素和链接实例,它用连接两个模型元素的实线表示,在关联的两端可以标注关联双方的角色和多重性标记。
2、 依赖关系
依赖关系描述一个元素对另一个元素的依附。依赖关系用源模型指向目标模型的带箭头的虚线表示。

3、 泛化关系
泛化关系也称为继承关系,泛化用一条带空心三角箭头的实线表示,从子类指向父类。

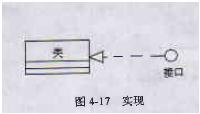
4、 实现关系
实现关系描述一个元素实现另一个元素。
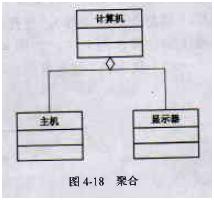
5、 聚合关系
聚合关系描述元素之间部分和整体的关系,即一个表示整体的模型元素可能由几个表示部分的模型元素聚合而成。即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;
6. 组合
组合也是关联关系的一种特例,他体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合;他同样体现整体与部分间的关系,但此时整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束;比如你和你的大脑;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;
>>>>>>>>>>>>>>>>>>>>>>>>>>>美好的分割线<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
二、读写文件
C语言方式
FILE* m_pFile;
if( (m_pFile = fopen( strFileName.c_str(), "wb" )) == NULL )
return false;
int l=m_strFileHeadString.length();
fwrite(m_strFileHeadString.c_str(), sizeof(char), l+1, m_pFile);
fclose(m_pFile);
MFC方式
CFile m_file;
if(!m_file.Open(strFileName.c_str(),CFile::modeCreate|CFile::modeWrite))
return false;
int l=m_strFileHeadString.length();
m_file.Write(m_strFileHeadString.c_str(), l+1);
m_file.Close();
C++方式
std::fstream m_stream;
m_stream.open(strFileName.c_str(), std::ios_base::out|std::ios_base::app);
if (m_stream.bad()){
std::cout << "打开输出文件出错!";
return false;
}
m_stream.write(m_strFileHeadString.c_str(), m_strFileHeadString.size() + 1);
m_stream.close();
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>hehe<<<<<<<<<<<<<<<<<<<<<<<<<<<<
三、ASCI码表
|
ASCII值 |
控制字符 |
ASCII值 |
控制字符 |
ASCII值 |
控制字符 |
ASCII值 |
控制字符 |
|
0 |
NUT |
32 |
(space) |
64 |
@ |
96 |
、 |
|
1 |
SOH |
33 |
! |
65 |
A |
97 |
a |
|
2 |
STX |
34 |
” |
66 |
B |
98 |
b |
|
3 |
ETX |
35 |
# |
67 |
C |
99 |
c |
|
4 |
EOT |
36 |
$ |
68 |
D |
100 |
d |
|
5 |
ENQ |
37 |
% |
69 |
E |
101 |
e |
|
6 |
ACK |
38 |
& |
70 |
F |
102 |
f |
|
7 |
BEL |
39 |
, |
71 |
G |
103 |
g |
|
8 |
BS |
40 |
( |
72 |
H |
104 |
h |
|
9 |
HT |
41 |
) |
73 |
I |
105 |
i |
|
10 |
LF |
42 |
* |
74 |
J |
106 |
j |
|
11 |
VT |
43 |
+ |
75 |
K |
107 |
k |
|
12 |
FF |
44 |
, |
76 |
L |
108 |
l |
|
13 |
CR |
45 |
- |
77 |
M |
109 |
m |
|
14 |
SO |
46 |
. |
78 |
N |
110 |
n |
|
15 |
SI |
47 |
/ |
79 |
O |
111 |
o |
|
16 |
DLE |
48 |
0 |
80 |
P |
112 |
p |
|
17 |
DCI |
49 |
1 |
81 |
Q |
113 |
q |
|
18 |
DC2 |
50 |
2 |
82 |
R |
114 |
r |
|
19 |
DC3 |
51 |
3 |
83 |
X |
115 |
s |
|
20 |
DC4 |
52 |
4 |
84 |
T |
116 |
t |
|
21 |
NAK |
53 |
5 |
85 |
U |
117 |
u |
|
22 |
SYN |
54 |
6 |
86 |
V |
118 |
v |
|
23 |
TB |
55 |
7 |
87 |
W |
119 |
w |
|
24 |
CAN |
56 |
8 |
88 |
X |
120 |
x |
|
25 |
EM |
57 |
9 |
89 |
Y |
121 |
y |
|
26 |
SUB |
58 |
: |
90 |
Z |
122 |
z |
|
27 |
ESC |
59 |
; |
91 |
[ |
123 |
{ |
|
28 |
FS |
60 |
< |
92 |
/ |
124 |
| |
|
29 |
GS |
61 |
= |
93 |
] |
125 |
} |
|
30 |
RS |
62 |
> |
94 |
^ |
126 |
~ |
|
31 |
US |
63 |
? |
95 |
— |
127 |
DEL |
|
NUL 空 |
VT 垂直制表 |
SYN 空转同步 |
|
SOH 标题开始 |
FF 走纸控制 |
ETB 信息组传送结束 |
|
STX 正文开始 |
CR 回车 |
CAN 作废 |
|
ETX 正文结束 |
SO 移位输出 |
EM 纸尽 |
|
EOY 传输结束 |
SI 移位输入 |
SUB 换置 |
|
ENQ 询问字符 |
DLE 空格 |
ESC 换码 |
|
ACK 承认 |
DC1 设备控制1 |
FS 文字分隔符 |
|
BEL 报警 |
DC2 设备控制2 |
GS 组分隔符 |
|
BS 退一格 |
DC3 设备控制3 |
RS 记录分隔符 |
|
HT 横向列表 |
DC4 设备控制4 |
US 单元分隔符 |
|
LF 换行 |
NAK 否定 |
DEL 删除 |
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>漂亮吗?<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
四、C语言控制格式
C语言专题——格式化I/O详解
1 格式化I/O函数族
函数族 用途 可用于所有的流 只用于stdin和stdout 内存中的字符串
scanf 格式化输入 fscanf scanf sscanf
printf 格式化输出 fprintf printf sprintf
2 scanf函数族
int fscanf (FILE *stream, const char *format, ...);
int scanf (const char *format, ...);
int sscanf (const char *string, const char *format, ...);
当格式化字符串到达末尾或者读取的输入不再匹配格式字符串所指定的类型时,输入就停止。
被转换的输入值的个数作为返回值返回。
如果在任何输入值被转换之前,输入流就已到达尾部,函数就返回EOF。
scanf族中的format字符串参数可能包含下列内容:
空白字符——它们与输入中的零个或多个空白字符匹配,在处理过程中将被忽略。
格式代码——它们指定函数如何解释接下来的输入字符。
其他字符——当任何其他字符出现在格式字符串时,下一个输入字符必须与它匹配。
如果匹配,该输入字符随后就被丢弃。如果不匹配,函数就不再读取直接返回。
3 scanf格式代码
格式:%
其中,[]表示可选项。
1> *
星号表示将使转换后的值被丢弃而不是进行存储。
2> 宽度
宽度以一个非负的整数给出,它限制将被读取用于转换的输入字符的个数。
如果未给出宽度,函数就连续读入字符直到遇见输入中的下一个空白字符。
3> 限定符
限定符用于修改有些格式代码的含义:
格式码 h l L
d,i,n short long
o,u,x unsigned short unsigned long
e,f,g double long double
4> 格式码
格式码用于指定字符如何被解释:
代码 c
参数 char *
含义 读取和存储单个字符。前导空白字符并不跳过。如果给出宽度,就读取和存储这个数目的字符。字符后面不会添加一个NUL字节。参数必
须指向一个足够大的字符数组。
代码 i,d
参数 int *
含义 一个可选的有符号整数被转换。d把输入解释为十进制数;i根据它的第一个字符决定值的基数,就像整型字面值常量的表示形式一样。
代码 u,o,x
参数 unsigned *
含义 一个可选的有符号整数被转换,但它按照无符号数存储。如果使用u,值被解释为十进制数;如果使用o,值被解释为八进制数;如果使用
x,值被解释为十六进制数。X和x同义。
代码 e,f,g
参数 float *
含义 期待一个浮点值。它的形式必须像一个浮点型字面常量,但小数点并非必须。E和G分别与e和g同义。
代码 s
参数 char *
含义 读取一串非空白字符。参数必须指向一个足够大的字符数组。当发现空白时输入就停止,字符串后面会自动加上NUL终止符。
代码 [xxx]
参数 char *
含义 根据给定组合的字符从输入中读取一串字符。参数必须指向一个足够大的字符数组。当遇到第一个不在给定组合中出现的字符时,输入就
停止。字符串后面会自动加上NUL终止符。代码%[abc]表示字符组合包括a、b和c。如果列表以一个^字符开头,表示字符组合是所列字符的补集
,所以%[^abc]表示字符组合为a、b、c之外的所有字符。右方括号也可以出现在字符列表中,但它必须是列表的第一个字符。至于横杠是否用
于指定某个范围的字符(例如%[a-z]),则因编译器而异。
代码 p
参数 void *
含义 输入预期为一串字符,诸如那些由printf函数的%p格式代码所产生的输出。它的转换方式因编译器而异,但转换结果将和按照上面描述的
进行打印所产生的字符的值是相同的。
代码 n
参数 int *
含义 到目前为止通过这个scanf函数的调用从输入读取的字符数被返回。%n转换的字符并不计算在scanf函数的返回值之内。它本身并不消耗任
何输入。
代码 %
参数 (无)
含义 这个代码与输入中的一个%相匹配,该%符号被丢弃。
4 printf函数族
int fprintf (FILE *stream, const char *format, ...);
int printf (const char *format, ...);
int sprintf (char *buffer, const char *format, ...);
函数的返回值是实际打印或存储的字符数。
5 printf格式代码
格式:%[零个或多个标志][最小字段宽度][精度][修改符]格式码
1> 格式码
代码 c
参数 int
含义 参数被裁剪为unsigned char类型并作为字符进行打印。
代码 i,d
参数 int
含义 参数作为一个十进制整数打印。如果给出了精度而且值的位数小于精度位数,前面就用0填充。
代码 u,o,x,X
参数 unsigned int
含义 参数作为一个无符号值打印,u使用十进制,o使用八进制,x或X使用十六进制,两者的区别是x约定使用abcdef,而X约定使用ABCDEF。
代码 e,E
参数 double
含义 参数根据指数形式打印。例如,6.023000e23是使用代码e,6.023000E23是使用代码E。小数点后面的位数由精度字段决定,缺省值是6。
代码 f
参数 double
含义 参数按照的常规浮点格式打印。精度字段决定小数点后面的位数,缺省值是6。
代码 g,G
参数 double
含义 参数以%f或%e(如G则%E)的格式打印,取决于它的值。如果指数大于等于-4但小于精度字段就使用%f格式,否则使用指数格式。
代码 s
参数 char *
含义 打印一个字符串。
代码 p
参数 void *
含义 指针值被转换为一串因编译器而异的可打印字符。这个代码主要是和scanf中的%p代码组合使用。
代码 n
参数 int *
含义 这个代码是独特的,因为它并不产生任何输出。相反,到目前为止函数所产生的输出字符数目将被保存到对应的参数中。
代码 %
参数 (无)
含义 打印一个%字符。
2> 标志
标志 -
含义 值在字段中做对齐,缺省情况下是右对齐。
标志 0
含义 当数值为右对齐时,缺省情况下是使用空格填充值左边未使用的列。这个标志表示用零填充,它可用于d,i,u,o,x,X,e,E,f,g和G代码。
使用d,i,u,o,x和X代码时,如果给出了精度字段,零标志就被忽略。如果格式代码中出现了负号,零标志也没有效果。
标志 +
含义 当用于一个格式化某个有符号值代码时,如果值非负,正号标志就会给它加上一个正号。如果该值为负,就像往常一样显示一个负号。在
缺省情况下,正号并不会显示。
标志 空格
含义 只用于转换有符号值的代码。当值非负时,这个标志把一个空格添加到它开始的位置。注意这个标志和正号标志是相互排斥的,如果两个
同时给出,空格标志便被忽略。
标志 #
含义 选择某些代码的另一种转换形式:
用于... #标志...
o 保证产生的值以一个零开头
x,X 在非零值前面加0x前缀(%X则为0X)
e,E,f 确保结果始终包含一个小数点,即使它后面没有数字
g,G 和上面的e,E和f代码相同。另外,缀尾的0并不从小数中去除
3> 字段宽度
字段宽度是一个十进制整数,用于指定将出现在结果中的最小字符数。如果值的字符数少于字段宽度,就对它进行填充以增加长度。
4> 精度
精度以一个句点开头,后面跟一个可选的十进制数。如果未给出整数,精度的缺省值为零。
对于d,i,u,o,x和X类型的转换,精度字段指定将出现在结果中的最小的数字个数并覆盖零标志。如果转换后的值的位数小于宽度,就在它的前
面插入零。如果值为零且精度也为零,则转换结果就不会产生数字。
对于e,E和f类型的转换,精度决定将出现在小数点之后的数字位数。
对于g和G类型的转换,它指定将出现在结果中的最大有效位数。
当使用s类型的转换时,精度指定将被转换的最多的字符数。
如果用于表示字段宽度和/或精度的十进制整数由一个星号代替,那么printf的下一个参数(必须是个整数)就提供宽度和(或)精度。因此,
这些值可以通过计算获得而不必预先指定。
5> 修改符
修改符 用于...时 表示参数是...
h d,i,u,o,x,X 一个(可能是无符号)short型整数
h n 一个指向short型整数的指针
l d,i,u,o,x,X 一个(可能是无符号)long型整数
l n 一个指向long型整数的指针
L e,E,f,g,G 一个long double型值
6 代码举例
1> 使用扫描集,使scanf能够读取一整行:
#include <stdio.h>
int main()
{
char string[50];
scanf("%[^\n]", string);
printf("%s\n", string);
return 0;
}
2> 使用*号,从参数表获取printf所需的字段宽度和精度参数:
#include <stdio.h>
#include <math.h>
int main()
{
double pi = acos(-1);
int width = 12;
int precision = 8;
printf("%*.*f\n", width, precision, pi);
return 0;
}
<<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
std::string的工具函数http://blog.csdn.net/sunningPig
如果使用STL中的std::string,它已经提供了如下一些比较有用的方法:
length(),取得字符串的长度。
substr(),从字符串中取出一个子串。
at()/operator [],取得字符串中指定位置的字符。
find/rfind(),从前往后/从后往前在字符串中查找一个子串的位置。
find_first_of(),在字符串中找到第一个在指定字符集中的字符位置。
find_first_not_of(),在字符串中找到第一次人不在指定字符集中的字符位置。
find_last_of(),在字符串中找到最后一个在指定字符集中的字符位置。
find_last_not_of(),在字符串中找到最后一个不在字符集中的字符位置。
关于std::string的其它方法,请参阅它的文档(在MSDN中可以找到)。
很容易发现,std::string并没有提供所有需要方法。所以,需要用STL提供了算法库、字符串流以及现存的std::string的方法来实现它们。
※ 将字符串转换为大写/小写
std::transform(str.begin(), str.end(), str.begin(), toupper);
※ 去掉字符串两端的空格
1) 去掉左边的空格
2) 去掉右边的空格
3) 去掉两边的空格
※ 忽略大小写比较字符串
这一功能的实现比较简单,只需要先将用于比较的两个字符串各自拷贝一个复本,并将这两个复本转换为小写,然后比较转换为小写之后的两个字符串即可。
※ StartsWith和EndsWith
1) StartsWith
如果返回值为true,则str是以substr开始的
2) EndsWith
如果返回值为true,则str是以substr结束的
还有另一个方法可以实现这两个函数。就是将str从头/尾截取substr长度的子串,再将这个子串也substr进行比较。不过这种方法需要判断str的长度是否足够,所以建议用find和rfind来实现。
※ 从字符串解析出int和bool等类型的值
说到将字符串解析成int,首先想到的一定是atoi、atol等C函数。如果用C++来完成这些工具函数,那就要用到std::istringstream。
除了解析bool值之外,下面这个函数可以解析大部分的类型的数值:
T value;
std::istringstream iss(str);
iss >> value;
return value;
}
上面这个模板可以将0解析成bool值false,将非0解析成treu。但它不能将字符串"false"解析成false,将"true"解析成true。因此要用一个特别的函数来解析bool型的值:
bool parseString(const std::string& str) {
bool value;
std::istringstream iss(str);
iss >> boolalpha >> value;
return value;
}
上面的函数中,向输入流传入一个std::boolalpha标记,输入流就能认识字符形式的"true"和"false"了。
使用与之类似的办法解析十六进制字符串,需要传入的标记是std::hex:
T value;
std::istringstream iss(str);
iss >> hex >> value;
return value;
}
※ 将各种数值类型转换成字符串(toString)
与解析字符串类似,使用std::ostringstream来将各种数值类型的数值转换成字符串,与上面对应的3个函数如下:
std::ostringstream oss;
oss << value;
return oss.str();
}
string toString(const bool& value) {
ostringstream oss;
oss << boolalpha << value;
return oss.str();
}
template<class T> std::string toHexString(const T& value, int width) {
std::ostringstream oss;
oss << hex;
if (width > 0) {
oss << setw(width) << setfill('0');
}
oss << value;
return oss.str();
}
注意到上面函数中用到的setw和setfill没有?它们也是一种标记,使用的时候需要一个参数。std::setw规定了向流输出的内容占用的宽 度,如果输出内容的宽度不够,默认就用空格填位。std::setfill则是用来设置占位符。如果还需要控制输出内容的对齐方式,可以使用std:: left和std::right来实现。
※ 拆分字符串和Tokenizer
拆分字符串恐怕得用Tokenizer来实现。C提供了strtok来实现Tokenizer,在STL中,用std::string的find_first_of和find_first_not_of来实现。下面就是Tokenizer类的nextToken方法:
// find the start character of the next token.
size_t i = m_String.find_first_not_of(delimiters, m_Offset);
if (i == string::npos) {
m_Offset = m_String.length();
return false;
} // find the end of the token.
size_t j = m_String.find_first_of(delimiters, i);
if (j == string::npos) {
m_Token = m_String.substr(i);
m_Offset = m_String.length();
return true;
} // to intercept the token and save current position
m_Token = m_String.substr(i, j - i);
m_Offset = j;
return true;
}
※ 源代码
最后,关于上述的一些方法,都已经实现在strutil.h和strutil.cpp中,所以现在附上这两个文件的内容:
√Header file: strutil.h
//
// Utilities for std::string
// defined in namespace strutil
// by James Fancy
//
////////////////////////////////////////////////////////////////////////////////
#pragma once
#include
<string>#include <vector>
#include <sstream>
#include <iomanip> // declaration
namespace strutil {
std::
string trimLeft(const std::string& str);std::string trimRight(const std::string& str);
std::string trim(const std::string& str);
std::
string toLower(const std::string& str);std::string toUpper(const std::string& str); bool startsWith(const std::string& str, const std::string& substr);
bool endsWith(const std::string& str, const std::string& substr);
bool equalsIgnoreCase(const std::string& str1, const std::string& str2);
template
<class T> T parseString(const std::string& str);template<class T> T parseHexString(const std::string& str);
template<bool> bool parseString(const std::string& str);
template
<class T> std::string toString(const T& value);template<class T> std::string toHexString(const T& value, int width = 0);
std::string toString(const bool& value);
std::vector
<std::string> split(const std::string& str, const std::string& delimiters);} // Tokenizer class
namespace strutil {
class Tokenizer
{
public:
static const std::string DEFAULT_DELIMITERS;
Tokenizer(const std::string& str);
Tokenizer(const std::string& str, const std::string& delimiters); bool nextToken();
bool nextToken(const std::string& delimiters);
const std::string getToken() const; /**
* to reset the tokenizer. After reset it, the tokenizer can get
* the tokens from the first token.
*/
void reset(); protected:
size_t m_Offset;
const std::string m_String;
std::string m_Token;
std::string m_Delimiters;
};
}
// implementation of template functionsnamespace strutil {
template
<class T> T parseString(const std::string& str) {T value;
std::istringstream iss(str);
iss >> value;
return value;
}
template
<class T> T parseHexString(const std::string& str) {T value;
std::istringstream iss(str);
iss >> hex >> value;
return value;
}
template
<class T> std::string toString(const T& value) {std::ostringstream oss;
oss << value;
return oss.str();
}
template
<class T> std::string toHexString(const T& value, int width) {std::ostringstream oss;
oss << hex;
if (width > 0) {
oss << setw(width) << setfill('0');
}
oss << value;
return oss.str();
}
}
√Source file: strutil.cpp
//
// Utilities for std::string
// defined in namespace strutil
// by James Fancy
//
////////////////////////////////////////////////////////////////////////////////
#include "strutil.h"
#include
<algorithm> namespace strutil { using namespace std; string trimLeft(const string& str) {string t = str;
t.erase(0, t.find_first_not_of(" \t\n\r"));
return t;
} string trimRight(const string& str) {
string t = str;
t.erase(t.find_last_not_of(" \t\n\r") + 1);
return t;
} string trim(const string& str) {
string t = str;
t.erase(0, t.find_first_not_of(" \t\n\r"));
t.erase(t.find_last_not_of(" \t\n\r") + 1);
return t;
} string toLower(const string& str) {
string t = str;
transform(t.begin(), t.end(), t.begin(), tolower);
return t;
} string toUpper(const string& str) {
string t = str;
transform(t.begin(), t.end(), t.begin(), toupper);
return t;
} bool startsWith(const string& str, const string& substr) {
return str.find(substr) == 0;
} bool endsWith(const string& str, const string& substr) {
return str.rfind(substr) == (str.length() - substr.length());
} bool equalsIgnoreCase(const string& str1, const string& str2) {
return toLower(str1) == toLower(str2);
}
template
<bool>bool parseString(const std::string& str) {
bool value;
std::istringstream iss(str);
iss >> boolalpha >> value;
return value;
} string toString(const bool& value) {
ostringstream oss;
oss << boolalpha << value;
return oss.str();
}
vector
<string> split(const string& str, const string& delimiters) {vector<string> ss;
Tokenizer tokenizer(str, delimiters);
while (tokenizer.nextToken()) {ss.push_back(tokenizer.getToken());
} return ss;
}
}
namespace strutil { const string Tokenizer::DEFAULT_DELIMITERS(" ");Tokenizer::Tokenizer(
const std::string& str): m_String(str), m_Offset(0), m_Delimiters(DEFAULT_DELIMITERS) {}
Tokenizer::Tokenizer(
const std::string& str, const std::string& delimiters): m_String(str), m_Offset(0), m_Delimiters(delimiters) {} bool Tokenizer::nextToken() {
return nextToken(m_Delimiters);
} bool Tokenizer::nextToken(const std::string& delimiters) {
// find the start charater of the next token.
size_t i = m_String.find_first_not_of(delimiters, m_Offset);
if (i == string::npos) {
m_Offset = m_String.length();
return false;
} // find the end of the token.
size_t j = m_String.find_first_of(delimiters, i);
if (j == string::npos) {
m_Token = m_String.substr(i);
m_Offset = m_String.length();
return true;
} // to intercept the token and save current position
m_Token = m_String.substr(i, j - i);
m_Offset = j;
return true;
} const string Tokenizer::getToken() const {
return m_Token;
} void Tokenizer::reset() {
m_Offset = 0;
}
}