下载剧本
下载后会在给定目录生成多pdf文件,文件名为每一节的名称
#!/usr/bin/env python3.5
# -*- coding: utf-8 -*-
# @Time : 2019/11/18 下午10:48
# @Author : yon
# @Email : 2012@qq.com
# @File : day1.py
import os
import re
import time
import logging
import pdfkit
from bs4 import BeautifulSoup
import requests
def gethtml(url):
targeturl = url
filepath = '/home/yon/Desktop/pdf/'
headers = {
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
'Cache-Control': 'no-cache',
'accept-encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'https://www.google.com/'
}
resp = requests.get(targeturl, headers=headers)
soup = BeautifulSoup(resp.content, "html.parser")
txt = soup.find("article")
title = filepath + txt.h1.text.replace(" ", "") + ".pdf"
# print(title)
pdfkit.from_string(str(txt), title)
if __name__ == '__main__':
# gethtml("https://www.thisamericanlife.org/664/transcript")
for number in range(665, 687):
urltoget = "https://www.thisamericanlife.org/" + str(number) + "/transcript"
gethtml(urltoget)
time.sleep(10)
下载MP3
对于不提供下载的剧集,可以先播放,然后打开工具看源代码,搜索MP3 ,对该地址右键打开新标签下载
翻译
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 12/31/19 11:06 AM
# @Author : yon
# @Email : @qq.com
# @File : tt.py
from selenium import webdriver
import random
import os
import re
import time
import logging
from bs4 import BeautifulSoup
import requests
import pdfkit
def translate(html):
url = "https://fanyi.baidu.com"
driver = webdriver.Chrome()
dr = driver.get(url)
driver.refresh()
jj = []
jj[0] = '<head><meta charset="UTF-8"></head>'
rr = ''
try:
for gg in html:
inputtext = driver.find_element_by_class_name("textarea")
inputtext.clear()
inputtext.send_keys(gg)
time.sleep(random.uniform(2, 3))
outtext = driver.find_element_by_class_name("target-output")
jj.append(str(gg))
jj.append(outtext.text)
except Exception as e:
print("出错了")
finally:
driver.close()
with open("/home/baixiaoxu/桌面/pdf/tt.html", mode='w') as filename:
for l in jj:
filename.write(str(l))
filename.write("
")
def gethtml(url):
targeturl = url
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
'Cache-Control': 'no-cache',
'accept-encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'https://www.google.com/'
}
resp = requests.get(targeturl, headers=headers)
soup = BeautifulSoup(resp.content, "html.parser")
txt = soup.find("article")
ss = BeautifulSoup(str(txt), "html.parser")
title1 = txt.h1.text.replace(" ", "")
ll = ss.findAll("p")
temp = []
temp_h4 = ''
for x in ll:
h4_temp = x.find_previous_sibling("h4")
if h4_temp != temp_h4 and h4_temp is not None:
temp.append(str(h4_temp))
temp.append(str(x))
temp_h4 = h4_temp
else:
temp.append(str(x))
body1 = {"title": title1, "content": temp}
return body1
def createpdf(title1):
filepath = "/home/baixiaoxu/桌面/pdf/"
# cc = BeautifulSoup(html, "html.parser")
pdfkit.from_file("/home/baixiaoxu/桌面/pdf/tt.html", filepath + title1 + ".pdf")
if __name__ == '__main__':
# url1 ="https://www.thisamericanlife.org/687/transcript"
# contentdic = gethtml(url1)
# title = contentdic["title"]
# body = contentdic["content"]
# translate(body)
createpdf("ttttt")
正式版
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 12/31/19 11:06 AM
# @Author : yon
# @Email : 2012@qq.com
# @File : tt.py
from selenium import webdriver
import random
import os
import re
import time
import logging
from bs4 import BeautifulSoup
import requests
import pdfkit
def translate(html):
url = "https://fanyi.baidu.com"
driver = webdriver.Chrome()
dr = driver.get(url)
driver.refresh()
jj = []
jj.append('<head><meta charset="UTF-8"></head>')
rr = ''
try:
for gg in html:
inputtext = driver.find_element_by_class_name("textarea")
inputtext.clear()
inputtext.send_keys(gg)
time.sleep(random.uniform(2, 3))
outtext = driver.find_element_by_class_name("target-output")
jj.append(str(gg))
jj.append(outtext.text)
except Exception as e:
print("出错了")
finally:
driver.close()
for i in jj:
rr = rr + str(i) + "
"
return rr
# with open("/home/baixiaoxu/桌面/pdf/tt.html", mode='w') as filename:
# for l in jj:
# filename.write(str(l))
# filename.write("
")
def gethtml(url):
targeturl = url
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
'Cache-Control': 'no-cache',
'accept-encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'https://www.google.com/'
}
resp = requests.get(targeturl, headers=headers)
soup = BeautifulSoup(resp.content, "html.parser")
txt = soup.find("article")
ss = BeautifulSoup(str(txt), "html.parser")
title1 = txt.h1.text.replace(" ", "")
ll = ss.findAll("p")
temp = []
temp_h4 = ''
for x in ll:
h4_temp = x.find_previous_sibling("h4")
if h4_temp != temp_h4 and h4_temp is not None:
temp.append(str(h4_temp))
temp.append(str(x))
temp_h4 = h4_temp
else:
temp.append(str(x))
body1 = {"title": title1, "content": temp}
return body1
def createpdf(pdfhtml1, pdftitle):
filepath = "/home/baixiaoxu/桌面/pdf/"
pdfkit.from_string(pdfhtml1, filepath + pdftitle + ".pdf")
if __name__ == '__main__':
url1 ="https://www.thisamericanlife.org/689/transcript"
contentdic = gethtml(url1)
title = contentdic["title"]
body = contentdic["content"]
xx = translate(body)
createpdf(xx, title)
腾讯翻译
腾讯翻译没有百度翻译好用,会有报错二退出,根据错误调整了try 位置
from selenium import webdriver
import random
import time
from bs4 import BeautifulSoup
import requests
import pdfkit
def translate(html):
url = "https://fanyi.qq.com/"
driver = webdriver.Chrome()
dr = driver.get(url)
driver.refresh()
html_translate_list = []
html_translate_list.append('<head><meta charset="UTF-8"></head>')
translated_string = ''
# try:
# for gg in html:
# inputtext = driver.find_elements_by_class_name("textinput")[0]
# inputtext.clear()
# inputtext.send_keys(gg)
# time.sleep(random.uniform(4, 6))
# outtext = driver.find_element_by_class_name("text-dst")
# html_translate_list.append(str(gg))
# html_translate_list.append(outtext.text)
# except Exception as e:
# print("翻译出错了")
# finally:
# driver.close()
for gg in html:
try:
inputtext = driver.find_elements_by_class_name("textinput")[0]
inputtext.clear()
inputtext.send_keys(gg)
time.sleep(random.uniform(4, 6))
outtext = driver.find_element_by_class_name("text-dst")
html_translate_list.append(str(gg))
html_translate_list.append(outtext.text)
except Exception as e:
html_translate_list.append(str(gg))
html_translate_list.append("not translated")
driver.close()
for i in html_translate_list:
translated_string = translated_string + str(i) + "
"
return translated_string
def gethtml(url):
targeturl = url
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
'Cache-Control': 'no-cache',
'accept-encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'https://www.google.com/'
}
resp = requests.get(targeturl, headers=headers)
soup = BeautifulSoup(resp.content, "html.parser")
txt = soup.find("article")
ss = BeautifulSoup(str(txt), "html.parser")
title1 = txt.find_all_next("h1")[0].text.replace(" ","")
ll = ss.findAll("p")
temp = []
temp_h4 = ''
for x in ll:
h4_temp = x.find_previous_sibling("h4")
if h4_temp != temp_h4 and h4_temp is not None:
temp.append(str(h4_temp))
temp.append(str(x))
temp_h4 = h4_temp
else:
temp.append(str(x))
body1 = {"title": title1, "content": temp}
return body1
def createpdf(pdfhtml1, pdftitle):
filepath = "/home/yon/Desktop/"
pdfkit.from_string(pdfhtml1, filepath + pdftitle + ".pdf")
if __name__ == '__main__':
url1 ="https://www.thisamericanlife.org/691/transcript"
contentdic = gethtml(url1)
title = contentdic["title"]
body = contentdic["content"]
xx = translate(body)
createpdf(xx, title)
翻译api
pycharm license
K6IXATEF43-eyJsaWNlbnNlSWQiOiJLNklYQVRFRjQzIiwibGljZW5zZWVOYW1lIjoi5o6I5p2D5Luj55CG5ZWGOiBodHRwOi8vaWRlYS5oay5jbiIsImFzc2lnbmVlTmFtZSI6IiIsImFzc2lnbmVlRW1haWwiOiIiLCJsaWNlbnNlUmVzdHJpY3Rpb24iOiIiLCJjaGVja0NvbmN1cnJlbnRVc2UiOmZhbHNlLCJwcm9kdWN0cyI6W3siY29kZSI6IklJIiwiZmFsbGJhY2tEYXRlIjoiMjAxOS0wNi0wNSIsInBhaWRVcFRvIjoiMjAyMC0wNi0wNCJ9LHsiY29kZSI6IkFDIiwiZmFsbGJhY2tEYXRlIjoiMjAxOS0wNi0wNSIsInBhaWRVcFRvIjoiMjAyMC0wNi0wNCJ9LHsiY29kZSI6IkRQTiIsImZhbGxiYWNrRGF0ZSI6IjIwMTktMDYtMDUiLCJwYWlkVXBUbyI6IjIwMjAtMDYtMDQifSx7ImNvZGUiOiJQUyIsImZhbGxiYWNrRGF0ZSI6IjIwMTktMDYtMDUiLCJwYWlkVXBUbyI6IjIwMjAtMDYtMDQifSx7ImNvZGUiOiJHTyIsImZhbGxiYWNrRGF0ZSI6IjIwMTktMDYtMDUiLCJwYWlkVXBUbyI6IjIwMjAtMDYtMDQifSx7ImNvZGUiOiJETSIsImZhbGxiYWNrRGF0ZSI6IjIwMTktMDYtMDUiLCJwYWlkVXBUbyI6IjIwMjAtMDYtMDQifSx7ImNvZGUiOiJDTCIsImZhbGxiYWNrRGF0ZSI6IjIwMTktMDYtMDUiLCJwYWlkVXBUbyI6IjIwMjAtMDYtMDQifSx7ImNvZGUiOiJSUzAiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiUkMiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiUkQiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiUEMiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiUk0iLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiV1MiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiREIiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiREMiLCJmYWxsYmFja0RhdGUiOiIyMDE5LTA2LTA1IiwicGFpZFVwVG8iOiIyMDIwLTA2LTA0In0seyJjb2RlIjoiUlNVIiwiZmFsbGJhY2tEYXRlIjoiMjAxOS0wNi0wNSIsInBhaWRVcFRvIjoiMjAyMC0wNi0wNCJ9XSwiaGFzaCI6IjEzMjkyMzQwLzAiLCJncmFjZVBlcmlvZERheXMiOjcsImF1dG9Qcm9sb25nYXRlZCI6ZmFsc2UsImlzQXV0b1Byb2xvbmdhdGVkIjpmYWxzZX0=-f8GvMiFGxAImRG8KKudyJDmZkDYD5fQiMOSFnBEMuAkeHjkq3rcj19hqQ1OS9nLCO4RvhRMINgYtKi3jVeZADAf6HKMnzDisWECB7ms8EgZoWOzTdKi3vw2pCpck5k6U6RXJmFlebIIbjA/KrzlPCPt9BfMZQ9NN5OdXDYXN9ZCvgG3vt5S0ZShPDNMQllSJt8OSerE1daj+nOP8f6WiUpgrYkHwydzF/NBlejdjvkMZp3iCk+ylKhYW5OgfnChCwWEyEmmIaNj4xYyeL3WMLqHm82Uo3bQnKkUU8eO0WOmJPfO2NGrVIeM5SEl1iu8odKX4fes5u+duTRCKjbDLAg==-MIIElTCCAn2gAwIBAgIBCTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTE4MTEwMTEyMjk0NloXDTIwMTEwMjEyMjk0NlowaDELMAkGA1UEBhMCQ1oxDjAMBgNVBAgMBU51c2xlMQ8wDQYDVQQHDAZQcmFndWUxGTAXBgNVBAoMEEpldEJyYWlucyBzLnIuby4xHTAbBgNVBAMMFHByb2QzeS1mcm9tLTIwMTgxMTAxMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAxcQkq+zdxlR2mmRYBPzGbUNdMN6OaXiXzxIWtMEkrJMO/5oUfQJbLLuMSMK0QHFmaI37WShyxZcfRCidwXjot4zmNBKnlyHodDij/78TmVqFl8nOeD5+07B8VEaIu7c3E1N+e1doC6wht4I4+IEmtsPAdoaj5WCQVQbrI8KeT8M9VcBIWX7fD0fhexfg3ZRt0xqwMcXGNp3DdJHiO0rCdU+Itv7EmtnSVq9jBG1usMSFvMowR25mju2JcPFp1+I4ZI+FqgR8gyG8oiNDyNEoAbsR3lOpI7grUYSvkB/xVy/VoklPCK2h0f0GJxFjnye8NT1PAywoyl7RmiAVRE/EKwIDAQABo4GZMIGWMAkGA1UdEwQCMAAwHQYDVR0OBBYEFGEpG9oZGcfLMGNBkY7SgHiMGgTcMEgGA1UdIwRBMD+AFKOetkhnQhI2Qb1t4Lm0oFKLl/GzoRykGjAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBggkA0myxg7KDeeEwEwYDVR0lBAwwCgYIKwYBBQUHAwEwCwYDVR0PBAQDAgWgMA0GCSqGSIb3DQEBCwUAA4ICAQAF8uc+YJOHHwOFcPzmbjcxNDuGoOUIP+2h1R75Lecswb7ru2LWWSUMtXVKQzChLNPn/72W0k+oI056tgiwuG7M49LXp4zQVlQnFmWU1wwGvVhq5R63Rpjx1zjGUhcXgayu7+9zMUW596Lbomsg8qVve6euqsrFicYkIIuUu4zYPndJwfe0YkS5nY72SHnNdbPhEnN8wcB2Kz+OIG0lih3yz5EqFhld03bGp222ZQCIghCTVL6QBNadGsiN/lWLl4JdR3lJkZzlpFdiHijoVRdWeSWqM4y0t23c92HXKrgppoSV18XMxrWVdoSM3nuMHwxGhFyde05OdDtLpCv+jlWf5REAHHA201pAU6bJSZINyHDUTB+Beo28rRXSwSh3OUIvYwKNVeoBY+KwOJ7WnuTCUq1meE6GkKc4D/cXmgpOyW/1SmBz3XjVIi/zprZ0zf3qH5mkphtg6ksjKgKjmx1cXfZAAX6wcDBNaCL+Ortep1Dh8xDUbqbBVNBL4jbiL3i3xsfNiyJgaZ5sX7i8tmStEpLbPwvHcByuf59qJhV/bZOl8KqJBETCDJcY6O2aqhTUy+9x93ThKs1GKrRPePrWPluud7ttlgtRveit/pcBrnQcXOl1rHq7ByB8CFAxNotRUYL9IF5n3wJOgkPojMy6jetQA5Ogc8Sm7RG6vg1yow==
baidu api翻译正式
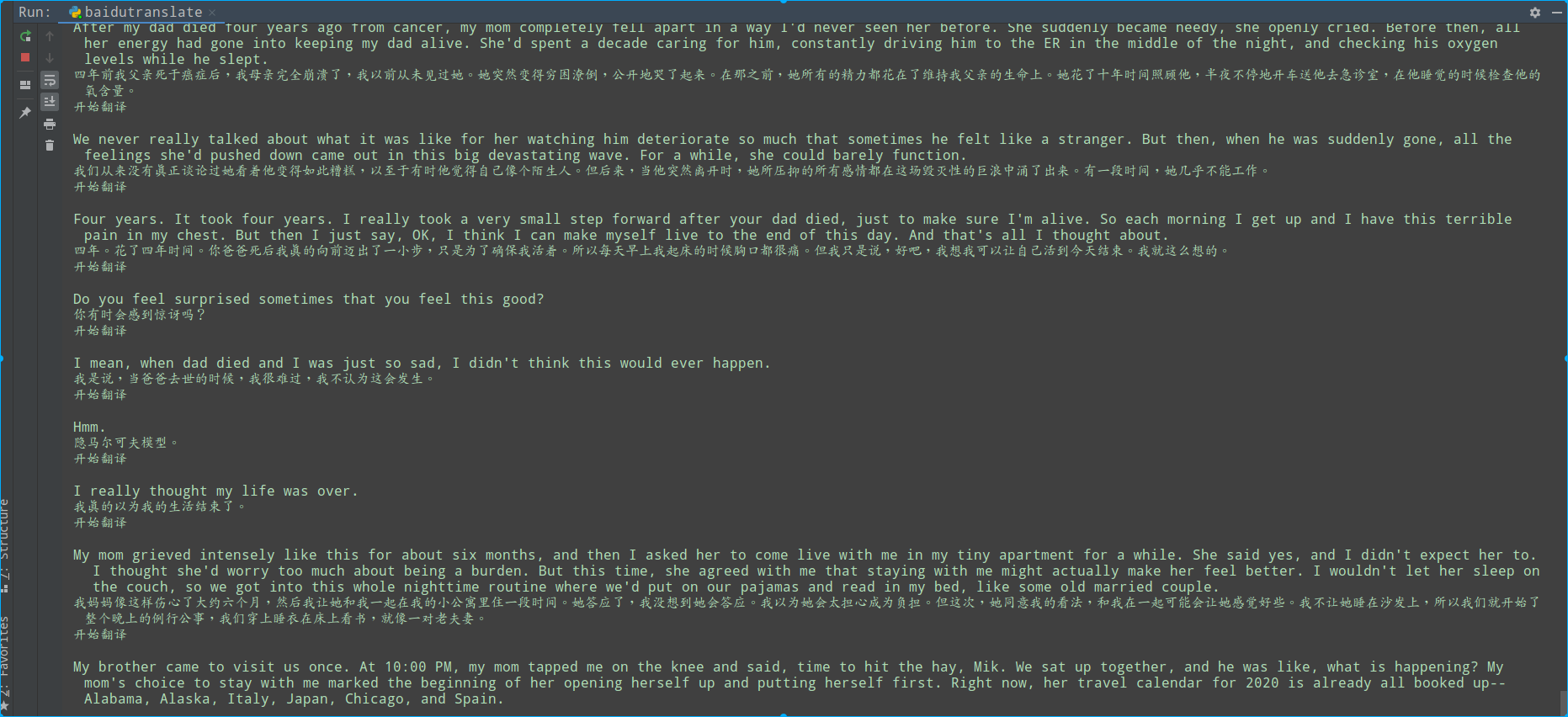
python 模块:
aiohttp==3.6.2
async-timeout==3.0.1
attrs==19.3.0
beautifulsoup4==4.8.2
bs4==0.0.1
certifi==2019.11.28
chardet==3.0.4
cssselect==1.1.0
idna==2.8
idna-ssl==1.1.0
lxml==4.4.2
multidict==4.7.5
pdfkit==0.6.1
Pillow==7.0.0
pymongo==3.10.1
PyPDF2==1.26.0
pyquery==1.4.1
redis==3.4.1
requests==2.22.0
selenium==3.141.0
soupsieve==1.9.5
typing-extensions==3.7.4.1
urllib3==1.25.7
yarl==1.4.2
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 5:44 PM 3月/13日/2020年
# @Author : yon
# @Email : xx@qq.com
# @File : baidutranslate
import http.client
import hashlib
import urllib
import random
import json
from pyquery import PyQuery as pq
import time
import pdfkit
class baidu_Trans:
def __init__(self):
self.httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
def __del__(self):
if self.httpClient:
self.httpClient.close()
def baidu_translate(self, word):
appid = '' # 填写你的appid
secretKey = '' # 填写你的密钥
myurl = '/api/trans/vip/translate'
fromLang = 'auto' # 原文语种
toLang = 'zh' # 译文语种
salt = random.randint(32768, 65536)
sign = appid + word + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(
word) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(salt) + '&sign=' + sign
try:
time.sleep(1)
self.httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = self.httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
return result.get('trans_result')[0].get('dst')
except Exception as e:
return False
def destory(self):
if self.httpClient:
self.httpClient.close()
def american_life(url):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer': 'https://cn.bing.com/',
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
doc = pq(url=url, headers=headers)
article = doc('article')
title = doc('h1').text().strip().replace(" ", "-")
sb_baidu = baidu_Trans()
for i in range(len(article('p'))):
# print("开始翻译
")
text = article('p').eq(i).text()
print(text)
translate = sb_baidu.baidu_translate(text)
taged_text = '<pre style="word-wrap:break-word;white-space: pre-wrap;">{}</pre>'.format(translate)
print(translate)
article('p').eq(i).append(taged_text)
sb_baidu.destory()
dic = {
"title": title,
"html": doc('article').html()
}
return dic
def create_to_pdf(url):
html_to_pdf = american_life(url)
ddoc = '<head><meta charset="UTF-8"></head>{}'.format(html_to_pdf['html'])
pdfkit.from_string(str(ddoc), "/home/baixiaoxu/desk/{}.pdf".format(html_to_pdf['title']))
if __name__ == '__main__':
create_to_pdf("https://www.thisamericanlife.org/688/transcript")
获取剧本时间
通过网站可以获取剧本的时间,但是导入成功后发现时间节点不对,脚本记录下来
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 11:25 PM 5月/30日/2020年
# @Author : yon
# @Email : xxxx@qq.com
# @File : tal
from bs4 import BeautifulSoup
import re
import requests
def get_html(url):
targeturl = url
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
'Cache-Control': 'no-cache',
'accept-encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'https://www.google.com/'
}
resp = requests.get(targeturl, headers=headers)
soup = BeautifulSoup(resp.content, "html.parser")
find_ps = soup.findAll("p")
generations_to_lrc(find_ps)
def generations_to_lrc(ps):
pattern = re.compile(r'.*(d+:d+:d+.d+)">(.*)</p>')
for p in ps:
p_match = pattern.match(str(p))
if p_match:
result = "[{}] {}".format(p_match.groups()[0], p_match.groups()[1])
last_result = re.sub(r'<.?w>', '', result)
print(last_result)
print("
")
if __name__ == '__main__':
url1 = "https://www.thisamericanlife.org/703/transcript"
get_html(url1)