JVM中有哪几块内存区域?Java8之后对内存分代做了什么改进?
Tomcat自己就是基于java开发的,是一个JVM进程,我们写的代码,放在tomcat目录,tomcat会加载我们的代码到JVM里去。

Java 8以后的内存分代的改进,永久代里放了一些常量池+类信息,常量池 -> 堆里面,类信息 -> metaspace(元区域)。
你知道JVM是如何运行起来的吗?我们的对象是如何分配的?

有一个类里面包含了一个main方法,你去执行这个main方法,此时会启动一个jvm进程,他会默认就会有一个main线程,这个main线程就负责执行这个main方法的代码,进而创建各种对象。
一般tomcat,类都会加载到jvm里去,spring容器而言都会对我们的类进行实例化成bean,有工作线程会来执行我们的bean实例对象里的方法和代码,进而也会创建其他的各种对象,实现业务逻辑。
public void doRequest() { MyService myService = new MyService(); myService.doService(); }
说说JVM在哪些情况下会触发垃圾回收可以吗?
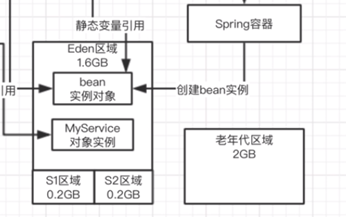
JVM的内存其实是有限制的,不可能是无限的,昂贵的资源,2核4G的机器,堆内存也就2GB左右,4核8G的机器,堆内存可能也就4G左右,栈内存也需要空间,metaspace区域放类信息也需要空间。
在jvm里必然是有一个内存分代模型,年轻代和老年代。给年轻代一共是2GB内存,给老年代是2GB内存,默认情况下eden和2个s的比例:8:1:1,eden是1.6GB,S是0.2GB。
如果说eden区域满了,此时必然触发垃圾回收,young gc(ygc),没有人引用的对象就是垃圾对象。
说说JVM的年轻代垃圾回收算法?对象什么时候转移到老年代?

年轻代,大部分情况下,对象生存周期是很短的,可能在0.01ms之内,线程执行了3个方法,创建了几个对象,0.01ms之后就方法都执行结束了,此时那几个对象就会在0.01ms之内变成垃圾,可以回收的100个对象,可能90个对象都是垃圾对象,10个对象是存活的对象,5个复制算法,一次young gc,年轻代的垃圾回收。
有的对象在年轻代里熬过了很多次垃圾回收,15次垃圾回收,此时会认为这个对象是要长期存活的对象,移到老年代。
说说老年代的垃圾回收算法?常用的垃圾回收器都有什么?
对老年代而言,他里面垃圾对象可能是没有那么多的,
标记-清理:找出来那些垃圾对象,然后直接把垃圾对象在老年代里清理掉;
标记-整理:把老年代里的存活对象标记出来,移动到一起,存活对象压缩到一片内存空间里去。剩余的空间都是垃圾对象整个给清理掉,剩余的都是连续的可用的内存空间,解决了内存碎片的一个问题。
parnew+cms的组合,g1直接分代回收,新版本,慢慢的就是主推g1垃圾回收器了,以后会淘汰掉parnew+cms的组合,jdk 8~jdk 9比较居多一些,parnew+cms的组合比较多一些。
CMS:分成好几个阶段,刚开始用标记-清理,标记出垃圾对象,并发清理一些垃圾对象,整理,把存活的对象压缩到一起,避免内存碎片的产生。
执行一个比较慢的垃圾回收,会stop the world,需要100mb,此时会导致系统停顿100ms,不能处理任何请求,应该尽可能垃圾回收和工作线程的运行,并发执行。
你们生产环境中的Tomat是如何设置JVM参数的?如何检查JVM运行情况?
你们线上系统jvm参数是怎么配置的,为什么要这样配置,在这个配置参数之下,线上系统jvm运行情况如何?
一般web系统部署到tomcat,系统仅仅在tomcat的jvm进程来执行。tomcat有一个配置脚本,catalina对应有启动的一些jvm参数设置。
主要是内存区域大小的分配,每个线程的栈大小,metaspace的大小,堆内存大小,年轻代和老年代分别大小,eden和survivor区域的大小分别是多少,如果没有设置,会有一个默认值。
垃圾回收器,年轻代,老年代分别使用哪种垃圾回收器,每种垃圾回收器是否有对应的一些特殊参数设置,这些设置都是用来干什么的。
为什么要这样设置?jvm表现如何?
在一定业务背景下,进行系统运行时的对象数量的预估,对内存压力进行预估,对整个jvm运行状况进行预估,预估完毕之后,根据预估情况,可以去设置一些jvm参数,然后进行压测,压测时候,需要观察Jvm运行情况,jstat工具去分析jvm运行情况,年轻代的eden区域的对象增长情况,ygc的频率,每次ygc过后多少对象存活,survivor区能否放的下,老年代对象增加速率,老年代多久会触发一次fgc。
可以根据压测的情况进行一定的jvm参数的调优。
压测主要两点:一个系统QPS,一个是系统的接口性能。
压测到一定程度时,了解机器的cpu, 内存,io, 磁盘的负载情况,jvm的表现等,由此需要对一些代码进行优化,比如优化性能,或减轻cpu, io磁盘负担等,如果发现jvm的gc过于频繁,内存泄漏,需要对jvm各内存区域的大小以及一些参数进行调优。
在线上生产环境时,也需要基于一些监控工具,或者jstat,观察系统的QPS和性能,接口可用性,调用成功率,机器负载,jvm表现,gc频率,耗时,内存消耗等等。
你在实际项目中是否做过JVM GC优化,怎么做的?
上一讲是如何通过预估+压测,做一份生产环境的jvm参数,去观察jvm运行情况。
如果jvm出频繁full gc,有没有尝试过生产环境的系统去进行gc优化,对于这个问题,需要结合具体业务来分析。
如何一步一步去分析系统的jvm的性能问题,如何去进行jvm gc调优?
分不同情况:
1. 自己做过jvm gc的生产调优,恭喜你了,直接实话实说,你当时怎么调优,你们的问题如何暴露出来的,你如何一步一步定位问题的,如何进行调优,最后的结果是什么?
2. 你看了jvm专栏,在过程中,或者看完以后,在自己生产环境中根据专栏学习到的知识,去调优过jvm,这个时候,你可以专栏里学习到的知识,去讲。最好对自己系统的生产环境的jvm,进行一个分析,gc频繁的问题,尽可能的去调优一下参数。
3. 发现分析了一下生产环境的jvm的运行情况,非常好,并发量很低,几十分钟才一次young gc,存活的对象特别少,几乎都在s区域,老年代几乎没什么对象,几天或者几周才发生一次full gc,在自己本地单机部署,测试环境里,去压测,每秒单机有500并发请求,去观察jvm的运行情况,这个时候他会不会存在频繁gc的问题,你就去调优一下,你就可以基于这个压测的例子去讲解。
你知道发生OOM之后,应该如何排查和处理线上系统的OOM问题?
思考oom可能发生在哪几个区域。解决思路,在jvm里设置几个参数,一旦发生oom之后,就会导出一份内存快照,就会有当时线上内存里对象的一个情况,可以用MAT(eclipse的一个插件(MAT也可以单独使用))这样的工具进行分析。
无非就是找出来当时占用内存最大的对象,找出来这些对象在代码中哪些地方创建出来的,一般来说就是可能会对内存做一个调优。
从业务背景出发,一步一步的说明,在什么样的业务背景下,为什么会产生oom的问题?
当某个系统崩溃时,找到自动导出的内存快照,分析XX 对象,直接定位代码,修改代码。
你一定要把案例的业务、背景和思想给吸收了,就得融入到自己的业务里去,我负责的业务系统,在什么样的情况下,可能说会出现一大批的对象卡在内存里,无法回收,导致我系统没法放更多的对象了。
oom不是你自己的代码,可能是你依赖的第三方的组件,结合自己的项目去一步一步的分析,oom问题的产生,和解决的过程。
参考资料:
互联网Java工程师面试突击(第三季)-- 中华石杉