传统的应用都是“monoliths”,意思就是大应用,即所有逻辑和模块都耦合在一起的
这样明显很挺多问题的,比如只能scale up,升级必须整体升级,扩容
所以我们就想把大应用,broken down成小,独立的模块或组件,这样组件可以独立的升级,扩容,组件也可以用不同的语言实现,组件间通过协议通信,每个组件就是一个微服务
微服务技术可以说是传统组件技术,如以前的COM,Corba,基于docker的演进,对于用户透明硬件,实现语言,组件间通过Restful或RPC交互
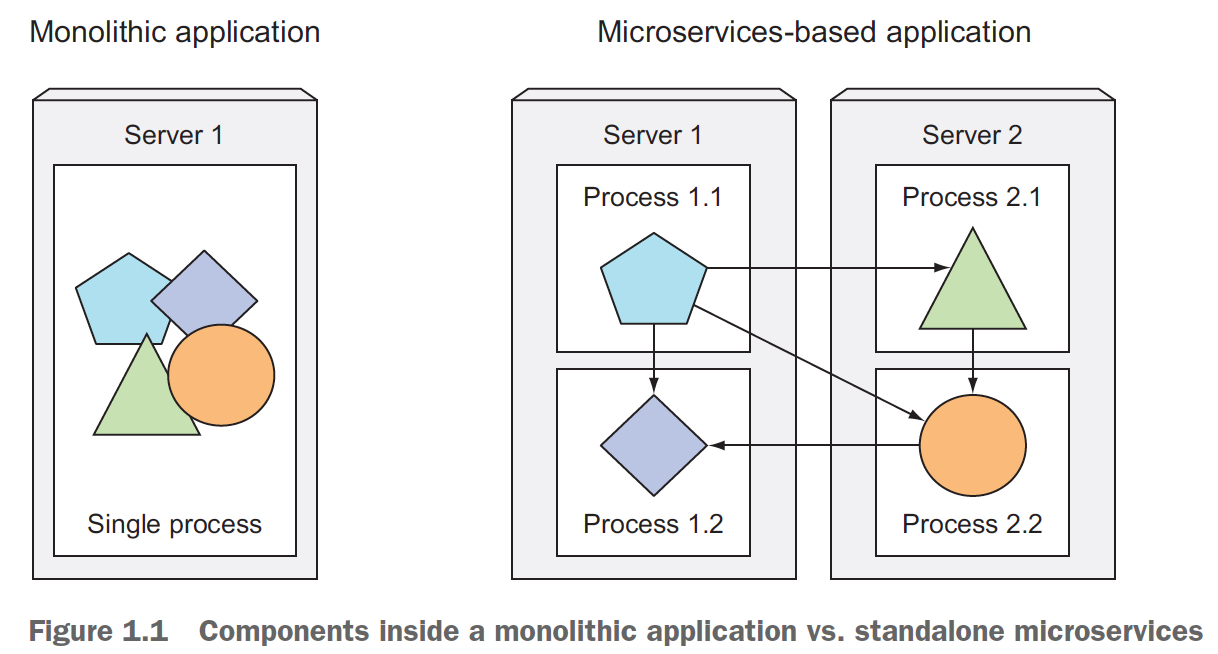
问题在于,你把一个大应用拆成很多小应用,是不是很难维护和部署?
好,你在一台物理机上部署这么多的小应用,并且独立升级,那么他们的依赖如果冲突怎么办?
并且每个组件跑的环境可能也不一样,你所有机器都需要把这些环境都装上?想想就要爆炸
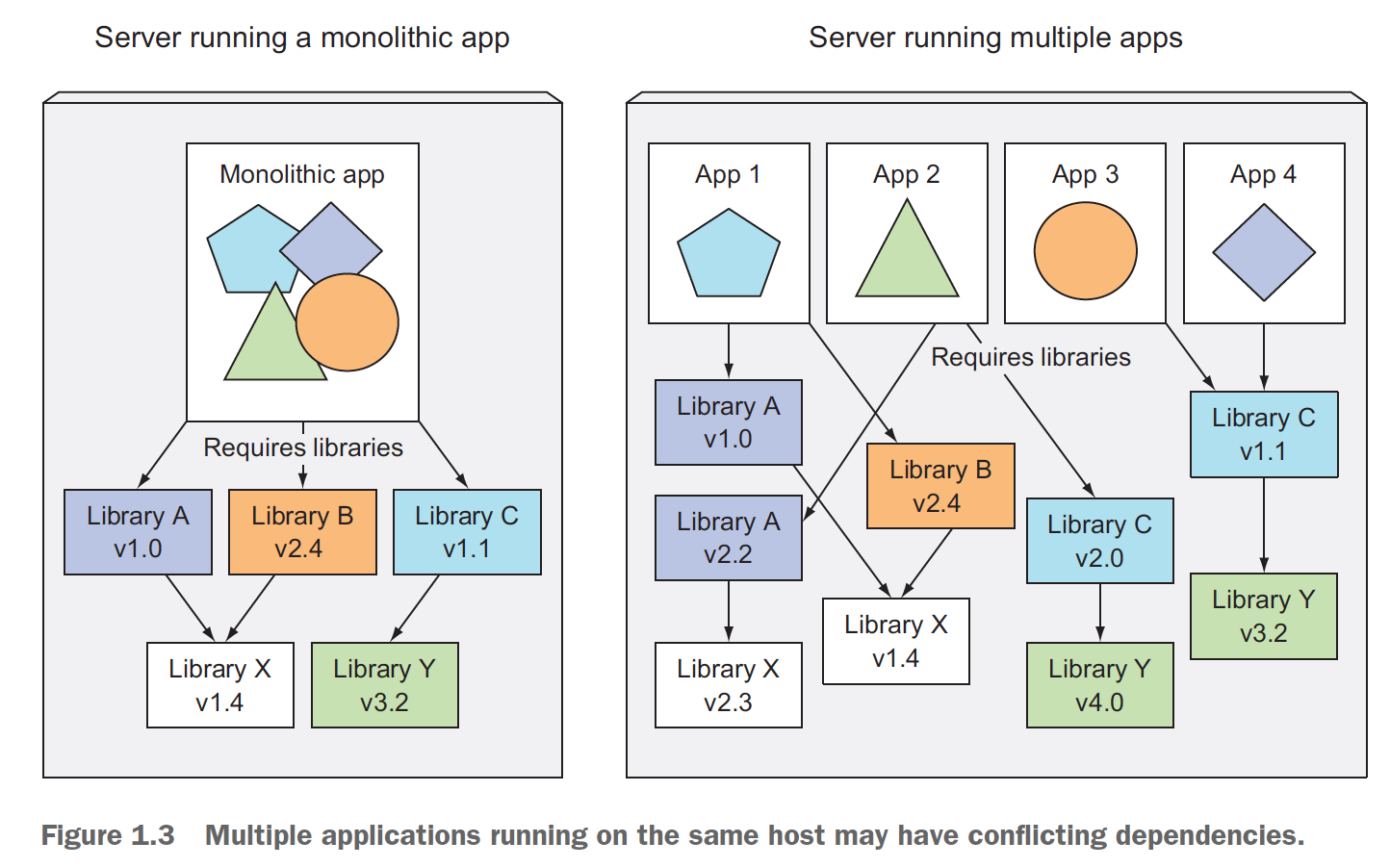
所以任何设计都有利弊,monoliths应用有他的问题,但拆成微服务也会引入一堆新的问题,
之所以现在微服务那么火,当然当年COM和Corba也是红极一时而后沉寂,是因为docker技术的出现,现有docker和相关框架可以比较好的解决这些问题,比如kubernetes
在这些框架的基础下,我们可以做到持续开发,甚至Devops,Noops
这里需要理解Devops,不是把ops团队干掉,然后把ops的工作都交给Dev,而是说在框架的支持下,原来的维护和发布已经变的非常简单,那么Dev也可以更高效的去做,没有必要让ops做,而ops也可以解放出来提供更好的基础框架,这是一种良性循环,否则张口闭口Devops只是一种恶性循环。
那么容器技术有啥牛逼的,原来的VM为啥不行?关键点就在“轻量”上
因为微服务是需要把大应用拆分成很多小应用,而这些小应用都是混布在机器上,首先考虑的问题就是隔离,
当然如果都用VM,隔离是没问题,但是太浪费资源了,都用VM可能比原来用一个应用消耗的资源大一个量级
所以,container技术,是一种轻量的VM
最大的差异是,每个VM都会跑一个独立的OS,kernel,而container会共用host上的OS
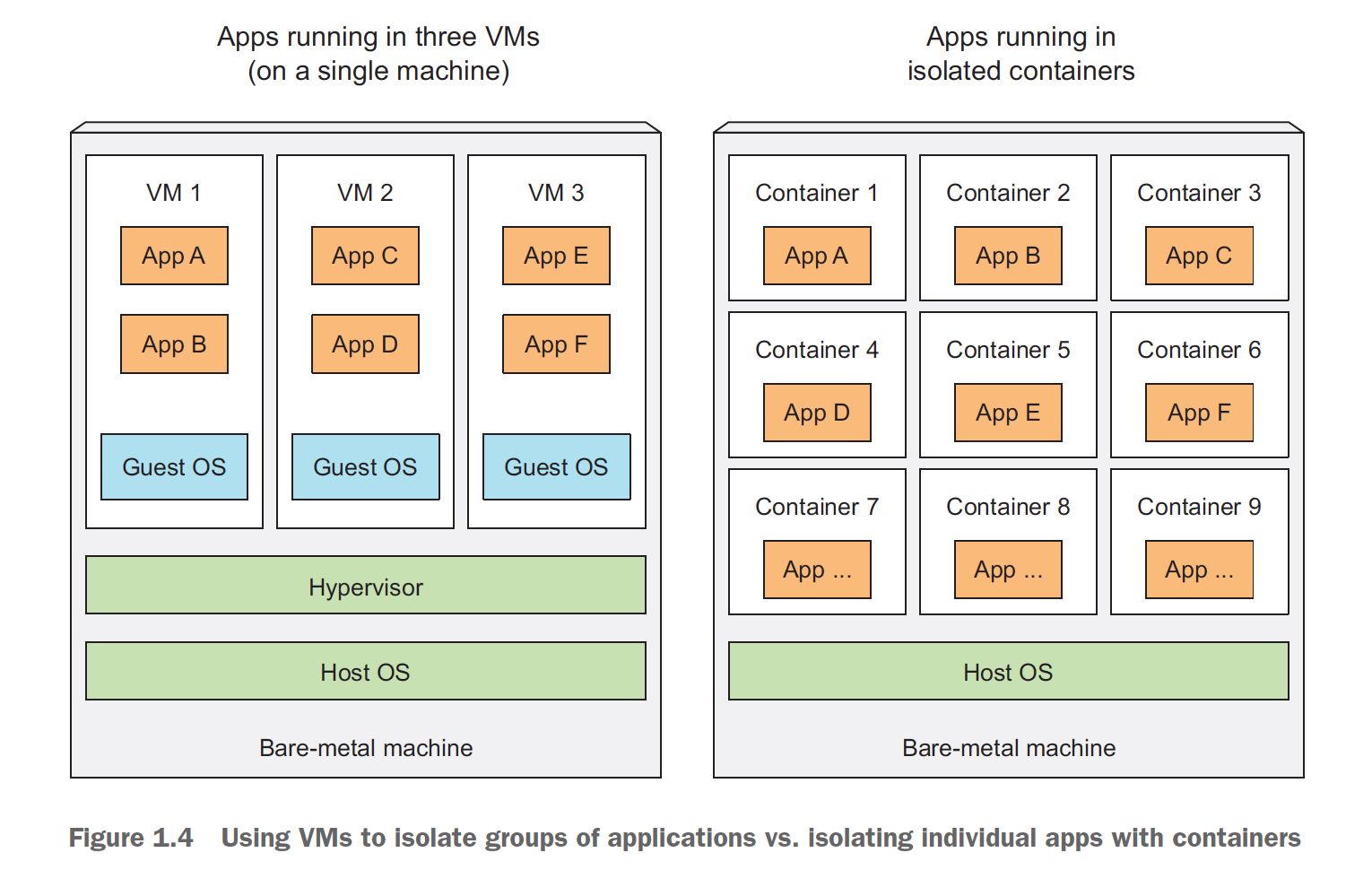
那么对于VM而言,因为OS都是独立的,所以他的隔离是很直觉的
那么container既然是共享OS,是用什么技术做到隔离的?
linux container主要是用了下面两种技术做到的容器隔离
首先,Linux namespaces,
Linux会默认用一个namespace,你也可以创建更多的namespace,namespace之间下面这些资源命名是隔离的,也就是说这个namespace看不到其他namespace的pid或userid等其他资源
Mount (mnt)
Process ID (pid)
Network (net)
Inter-process communication (ipc)
UTS (host name,domain name)
User ID (user)
再者,是CGroup,Linux kernel feature that limits the resource usage of a process (or a group of processes).
被限制的进程,使用的资源,cpu,memory,可以限制在规定的范围内
Cgroup其实也不完美,比如对于IO,只能限制IOPS,无论是磁盘还是网络,很难去限制真正的流量;Cpu也无法针对突发流量,使用率在瞬间超限,然后再被限制,这样很容易影响到其他进程,除非明确绑核;
容器技术很久之前就有,但是一直到docker技术出现后,才被大家广泛的关注和接受;原因在于docker是“Portable”的,通过docker image
Docker was the first container system that made containers easily portable across different machines.
It simplified the process of packaging up not only the application but also all its libraries and other dependencies,
even the whole OS file system, into a simple, portable package that can be used to provision the application to any other machine running Docker
docker image把整个执行环境,包含OS file system都package,这样哪怕docker内和宿主机是不同的os内核都没关系,比如一个是centos,一个是debian
docker image本身也是从vm image借鉴过来的,但docker image会更轻量
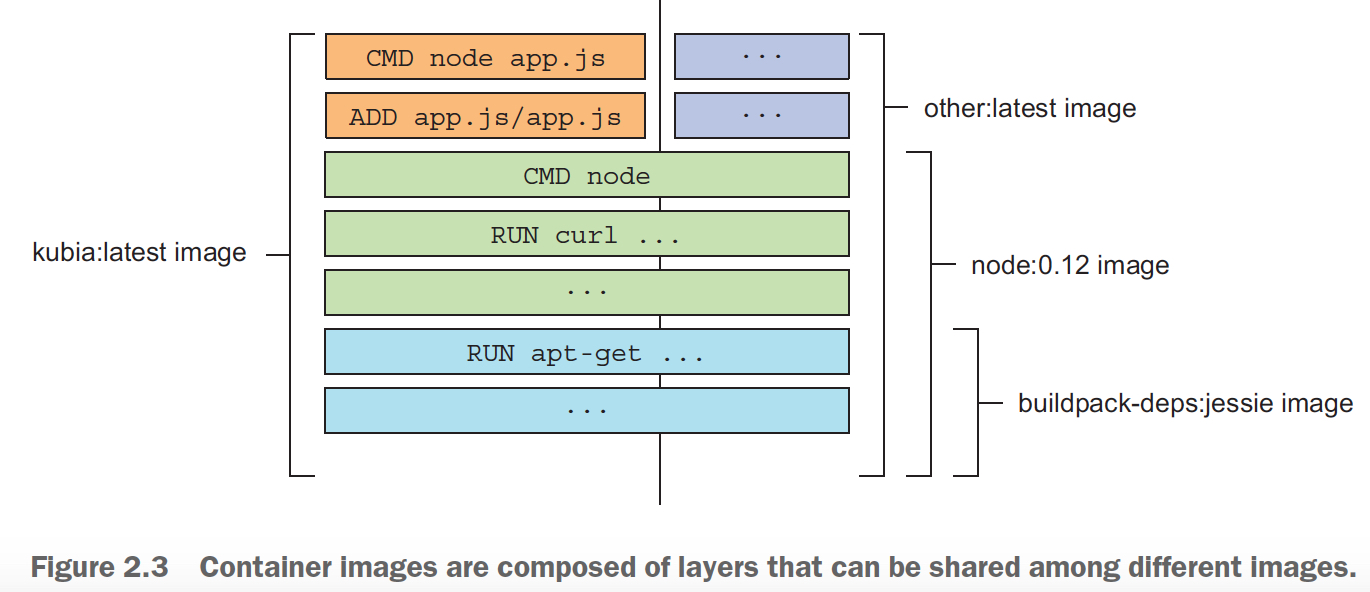
并且docker image一个很优秀的设计是他是分层的,所以如果很多image都用到一个layer,这个layer只需要被下载一次
A big difference between Docker-based container images and VM images is that
container images are composed of layers, which can be shared and reused across multiple images.
所以要理解,docker技术的核心是package技术,而不是隔离,docker的隔离是通过linux内核features,namespaces和cgroup来保证的,docker本身不管隔离的事
所以通俗的讲,docker就是一个打包和管理包的技术,就类似maven,只是他管理的不是一个java jar包,而是一个image
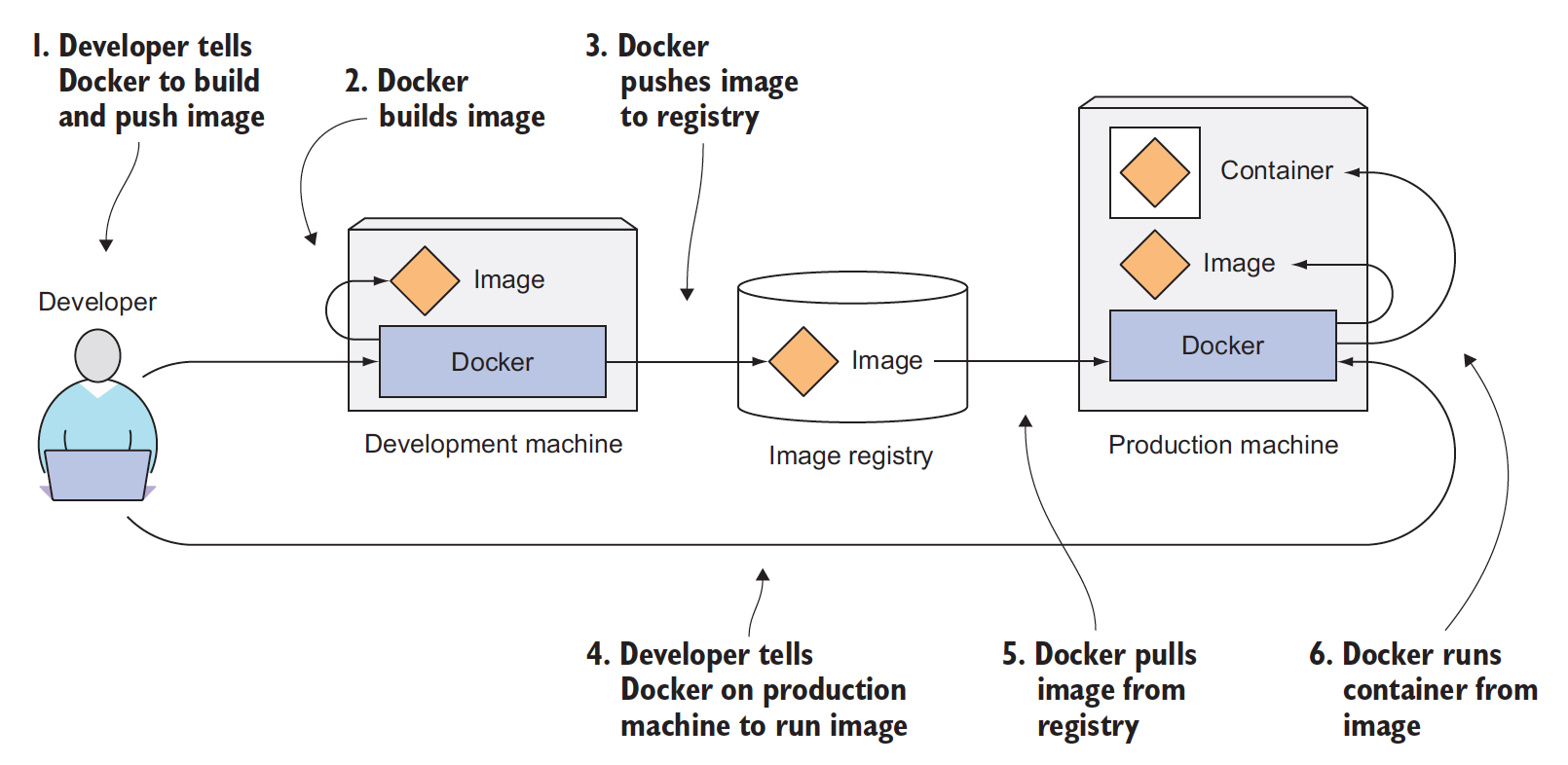
之前说过container和VM的差别,那么现在再具体看下docker container和VM的差别,加深理解
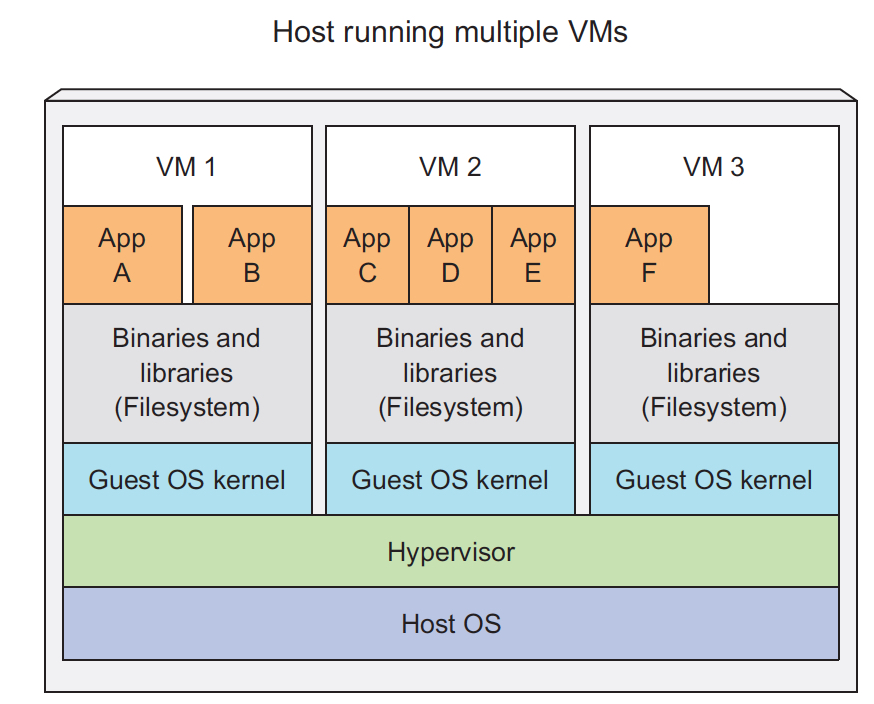

从这个图我们可以看出,
首先,之前说的区别,VM是需要自带OS kernel的,并且VM是完全独立的;docker共享宿主机的OS,并且需要一个docker进程来管理
再者,对于VM,如果应用A和B需要同一个执行环境,我们需要把他们放在一个VM中,但这样他们之间是不隔离的;对于docker,A和B需要跑在独立的容器内,但是还要共享执行环境
那么docker是怎么做的,关键就是docker image是分层的,docker可以基于同一层去启动容器;但这里的layer是read-only的,所以如果一个container改变了环境的话,他会增加一个新的layer,把所有的变更放在这个新的layer中
下面来说k8s,
我们有了docker,容器可以在各个机器上迁来迁去,那么如果我有很多容器,和主机,怎么管理他们,靠手工的迁移和管理肯定是不合适的
那么kubernetes就做这个事的,他可以看成cluster的操作系统,提供类似,service discovery, scaling, load-balancing, self-healing, and even leader election等功能
Kubernetes的架构如下,
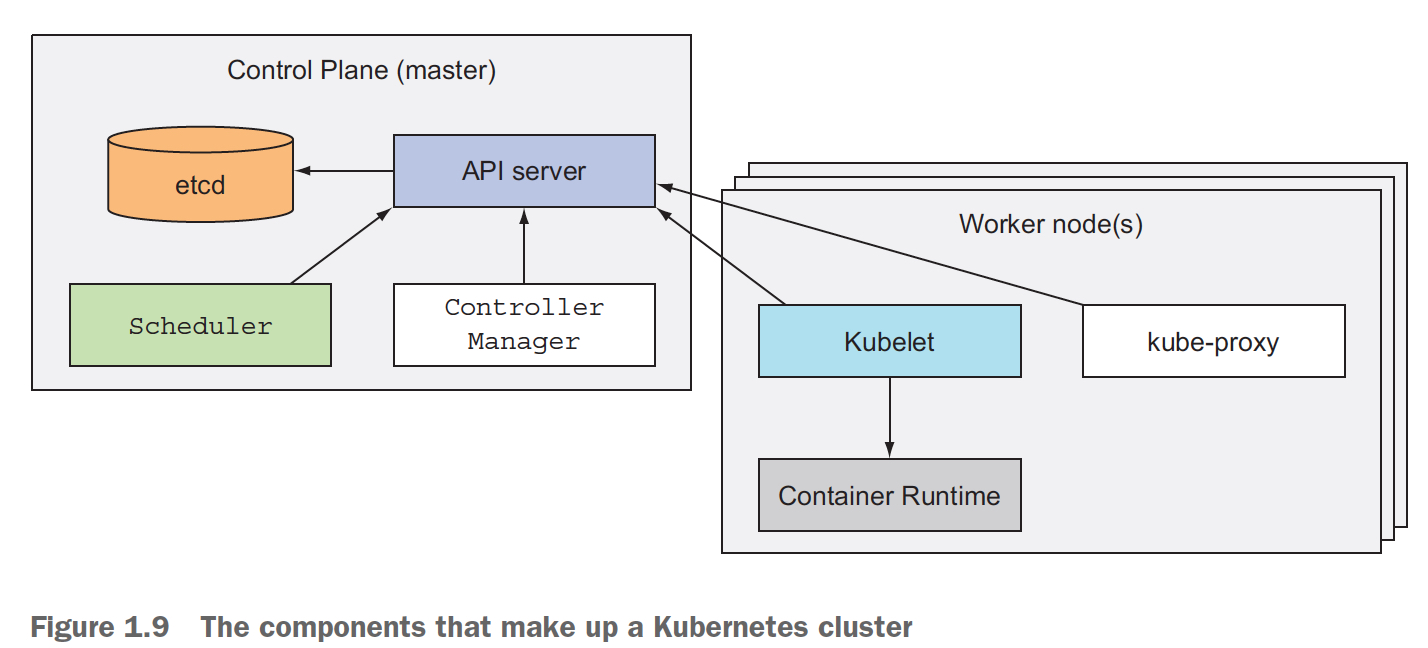
首先,kubernetes节点分为,master和worker
master,Control plane,包含API server,用于通信,client和control plane,或多个control plane之间;Scheduler,顾名思义,负责调度应用到各个worker nodes;ETCD,类似zk,存储配置,并保证一致性;Controller Manager,负责集群级别的管理,监控worker nodes,节点failover等
woker node,首先要个Container Runtime,如docker进程来执行容器;Kubelet,用于和master通信,并管理改woker上的所有容器;Kube-proxy,类似SLB,做服务访问load balance的
下面通过一个例子来看下,用户是如何通过kubernetes来提交应用的,
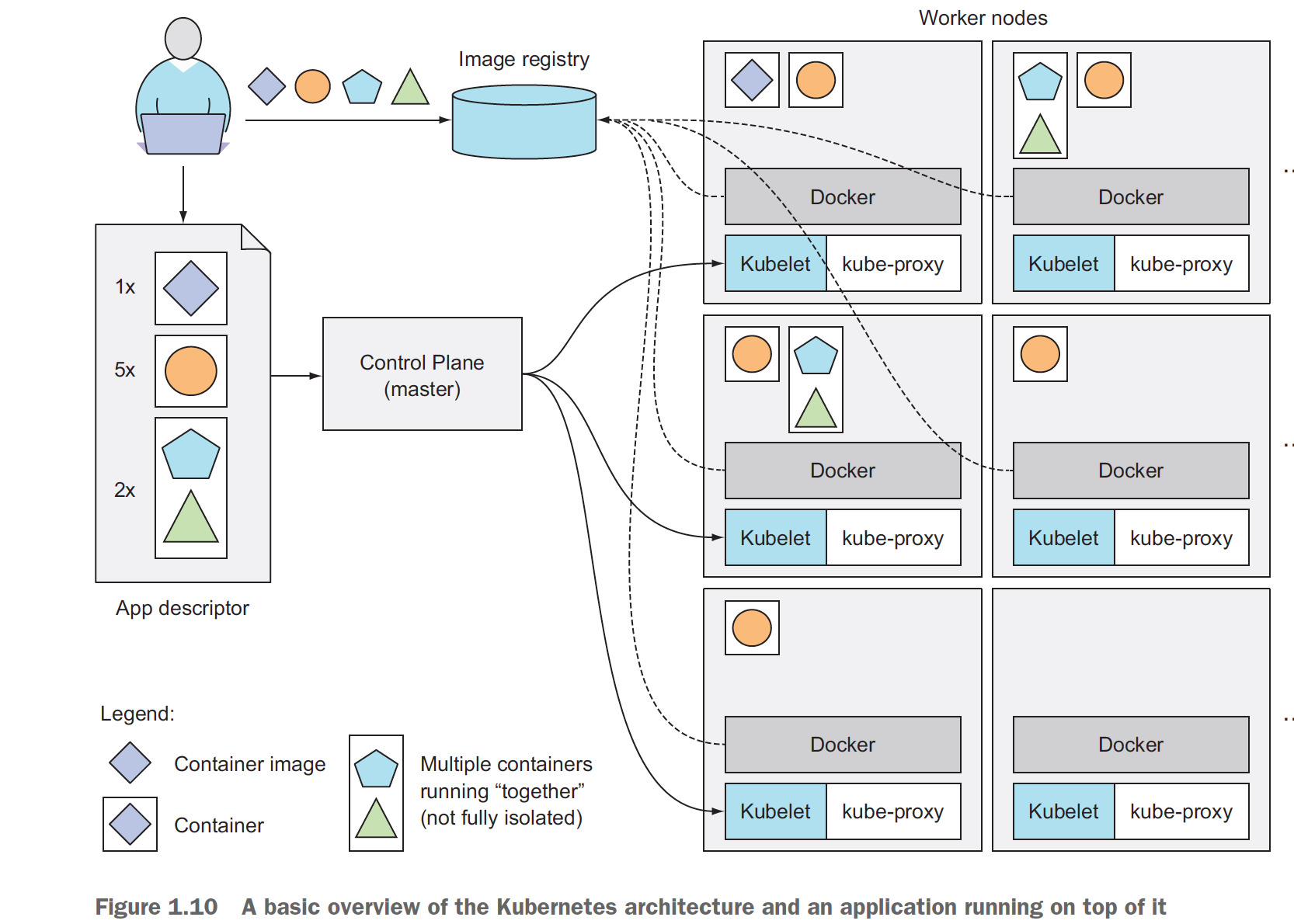
1. 用户首先要把应用相关的docker image提交到image registry
2. 然后用户需要写,App descriptor,用于描述应用中各个container是如何组织的
这里有个概念是,pods,可以理解成容器分组,在一个pods中,会被要求在一起执行,调度的时候也是按照一个整体调用,并且container之间也是不完全隔离的
所以在descriptor中,需要将container分成pods,并且给出每个pods的并发数
3. 接着就把应用提交给master,master会将各个pods调度到woker,通过woker上的kubelet,kubelet会让节点上的docker runtime把容器启动起来
4,docker runtime按照之前的步骤,先去image registry下载,然后启动容器即可
下面开始action,Docker篇
1. 启动docker
docker run <image>
docker run <image>:<tag>
例子,执行busybox image,传入参数 echo “hello world”

2. 创建docker image
首先,需要有一个要跑在docker中的程序,这里用个js,
const http = require('http');
const os = require('os');
console.log("Kubia server starting...");
var handler = function(request, response) {
console.log("Received request from " + request.connection.remoteAddress);
response.writeHead(200);
response.end("You've hit " + os.hostname() + "
");
};
var www = http.createServer(handler);
www.listen(8080);
然后,需要写个Dockerfile,
FROM node:7 #基于的image layer,“node” container image, tag 7
ADD app.js /app.js #把app.js放到容器的root目录
ENTRYPOINT ["node", "app.js"] #容器启动的时候执行那个命令,这里是“node app.js”
最终调用,docker build创建image,
docker build -t kubia .
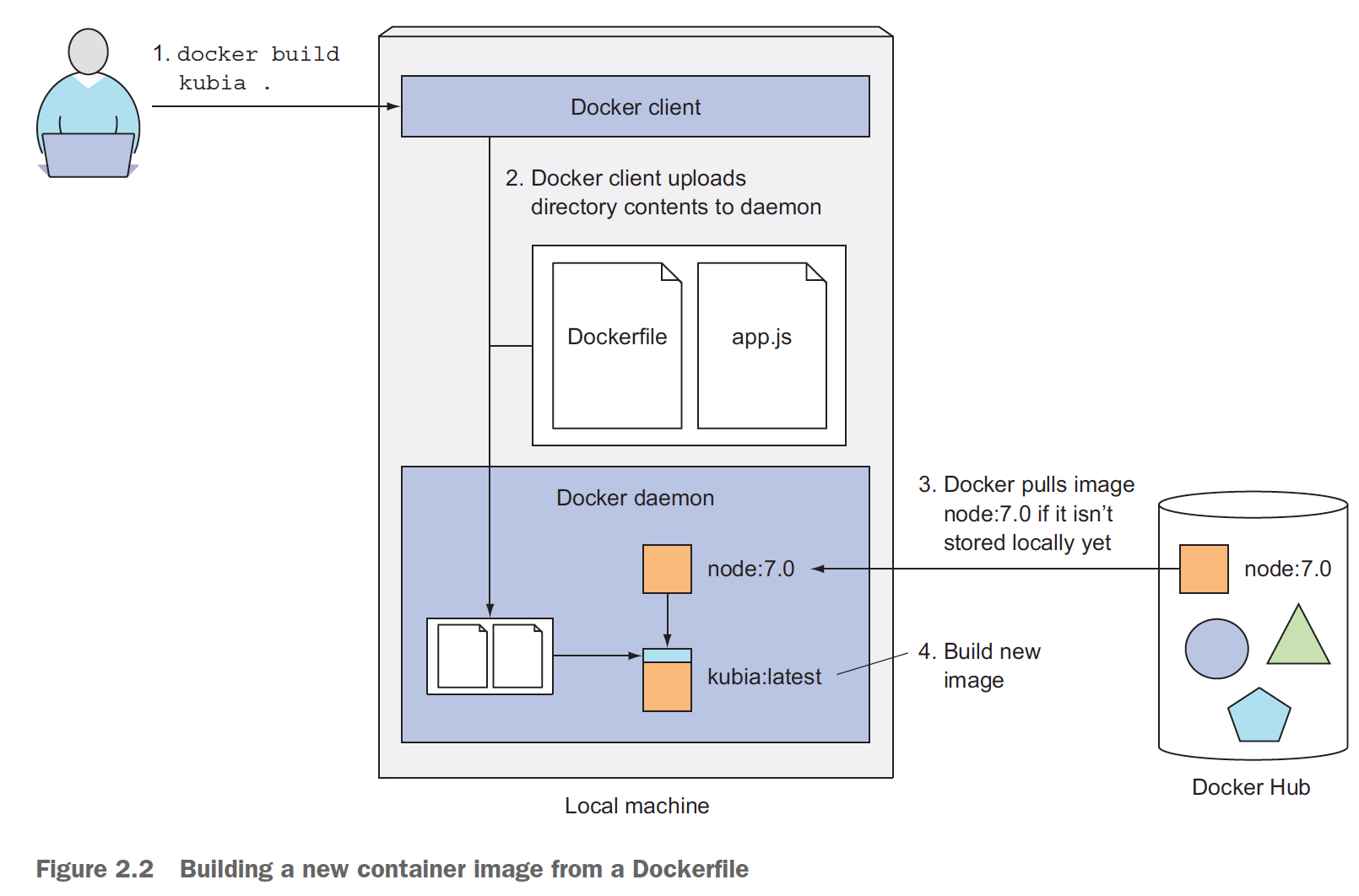
这里再通过这个例子看下,image layer的分层,
可以看到,对于dockerfile中每一行命令,都会产生一个layer
You may think that each Dockerfile creates only a single new layer, but that’s not the case. When building an image, a new layer is created for each individual command
in the Dockerfile.
这个时候,我们可以查看刚刚创建的image,

现在你可以用docker run,启动这个容器,
docker run --name kubia-container -p 8080:8080 -d kubia
--name,容器名字
-p,Port 8080 on the local machine will be mapped to port 8080 inside the container,docker的端口是隔离的,所以你想从外面访问,需要和宿主机的端口匹配上
-d,daemon,后台程序;
容器启动后,可以通过 http://localhost:8080 来访问
3. 查看容器
docker ps #查看容器基本信息
docker inspect kubia-container #查看容器相关的所有信息
登入到容器内部,
docker exec -it kubia-container bash
-i, which makes sure STDIN is kept open. You need this for entering commands into the shell.
-t, which allocates a pseudo terminal (TTY).
这里需注意,因为容器的进程其实是跑在宿主机的os上,所以容器内核宿主机上都可以看到这个容器进程,但是PID不一样,docker内的PID是隔离的


4. 停止和删除容器
docker stop kubia-container #停止的容器,可以用docker ps -a查看到
docker rm kubia-container #删除容器
5. 上传和注册容器image
经过上面的步骤,容器已经可以在local正常使用,但是如果要跨机器使用,需要把image注册到docker hub上
先要给image加tag,因为docker hub只允许用户上传,以用户docker hub id开头的image
docker tag kubia luksa/kubia #如果dockerhub id是luksa
docker push luksa/kubia #上传
这样你就可以在其他机器上,这样启动这个image
docker run -p 8080:8080 -d luksa/kubia
Kubernetes篇
集群版本kubernetes按照比较麻烦,所以一般是用miniKube,先启动miniKube
minikube start
然后,即可以用kubectl来连接kubernetes,kubectl就是一个client,用于连接kubernetes的APIServer
你可以看集群情况,

也可以看到所有节点的情况,

看某一个节点,
kubectl describe node gke-kubia-85f6-node-0rr
现在开始部署应用到kubernetes,
$ kubectl run kubia --image=luksa/kubia --port=8080 --generator=run/v1
replicationcontroller "kubia" created
这里看到启动应用的时候,创建的是一个replicationcontroller,因为应用部署的时候需要多并发,所以需要rc来管理各个应用的replica
部署完后,我们怎么看部署的应用,
对于kubernetes,应用的部署的粒度是pod,而不是container
A pod is a group of one or more tightly related containers that will always run together on the same worker node and in the same Linux namespace(s).
pod类似逻辑machine,pod内部的container不是完全隔离,是共用同一个linux namespaces的
container,pod,work node的关系如下,
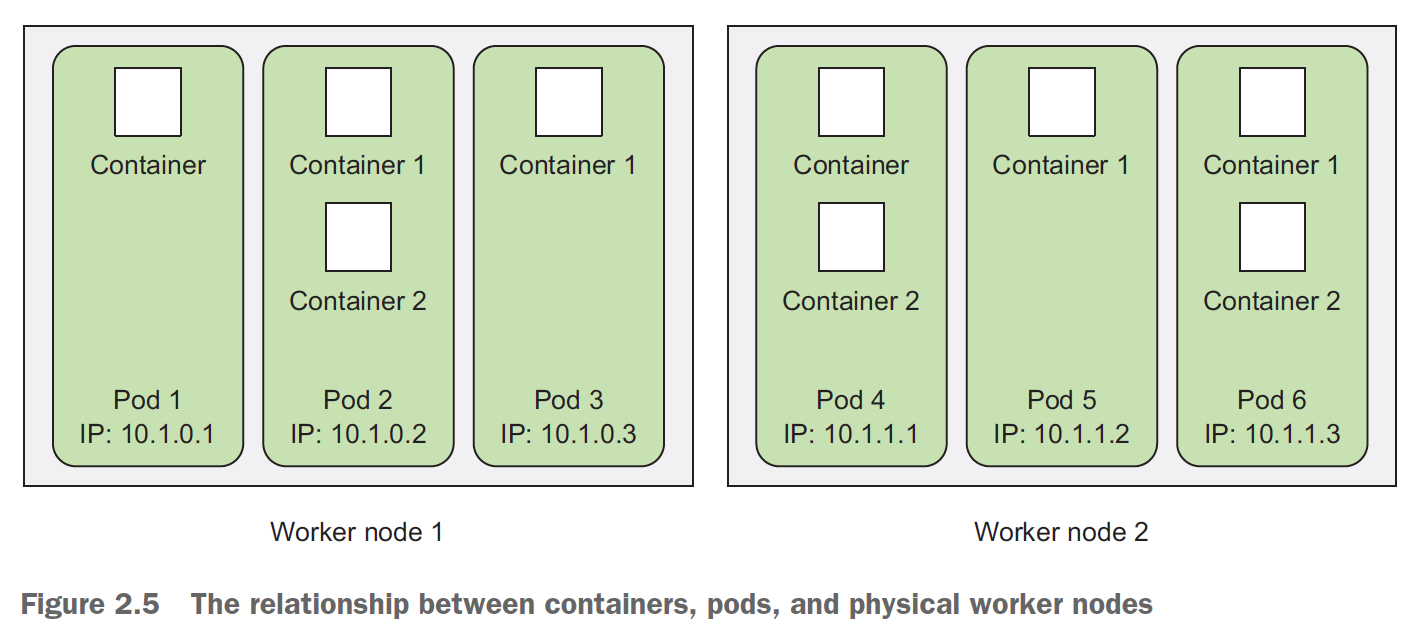
那么我们就可以看看pod的状态,

详细的信息,

接着,如何把pod所提供的服务暴露给外部用户?这里就需要创建一个service,把rc暴露出来,因为rc管理的pod是动态的,临时的,如果挂了,会拉起新的,但服务的ip不能老变,所以需要一个service做层proxy
kubectl expose rc kubia --type=LoadBalancer --name kubia-http
service "kubia-http" exposed
查看services的状态,

所以整个应用的组件图如下,
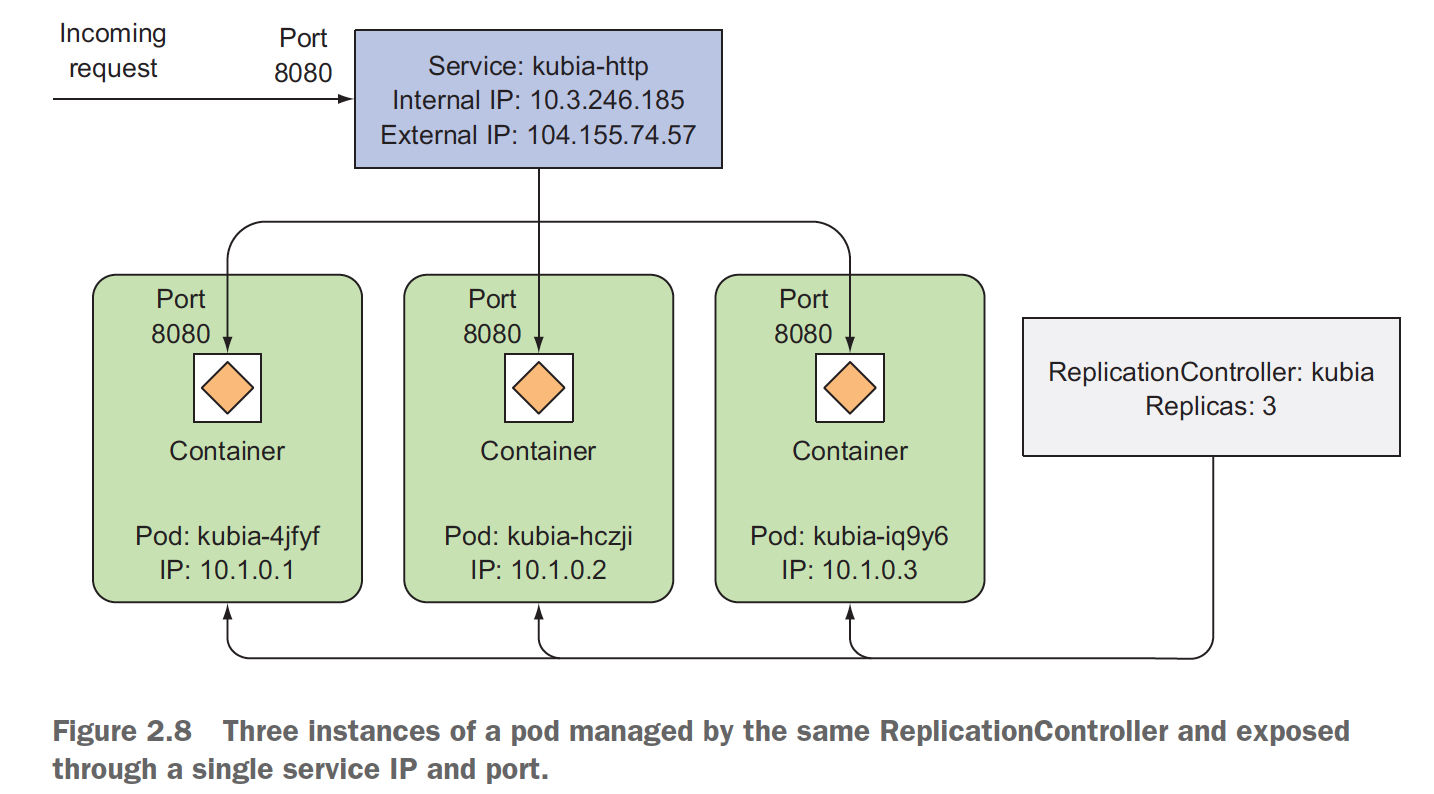
kubernetes可以动态扩容的,下面可以看到扩容前后的情况



