https://www.bilibili.com/video/av9770302/?p=24
https://www.bilibili.com/video/av24724071/?p=3
https://zhuanlan.zhihu.com/p/25239682
强化学习概览
分为几个要素,
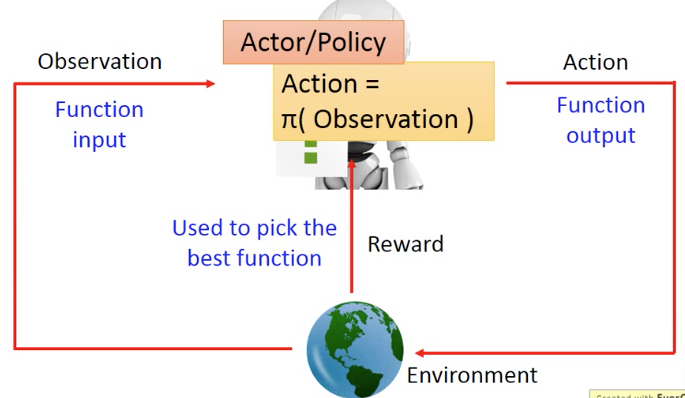
首先我们可以观察到state,observation
然后我们采取Action
环境会对我们采取的Action,给与Reward,由此可以知道action的效果的好坏
最终我们学习的目的是,policy,即state和action的匹配关系

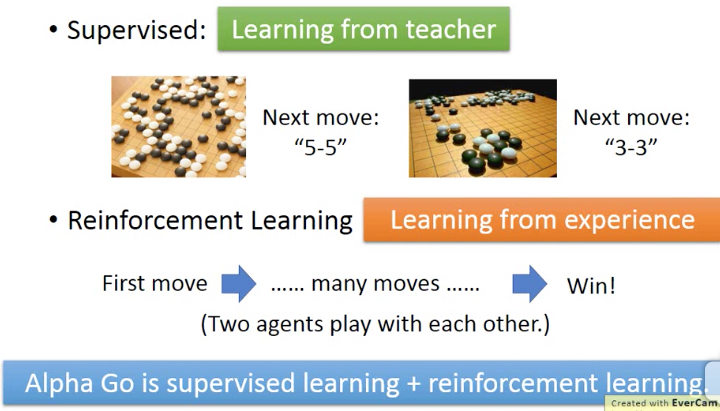
那么强化学习和传统的supervised learning有啥区别,为什么需要强化学习
传统supervised learning的场景,是人可以知道明确答案的,比如图片分类等,这样才能训练集去supervise机器
但是有些问题,人也无法决定如何做事正确答案,比如玩游戏,这是就需要强化学习,通过经验去试错
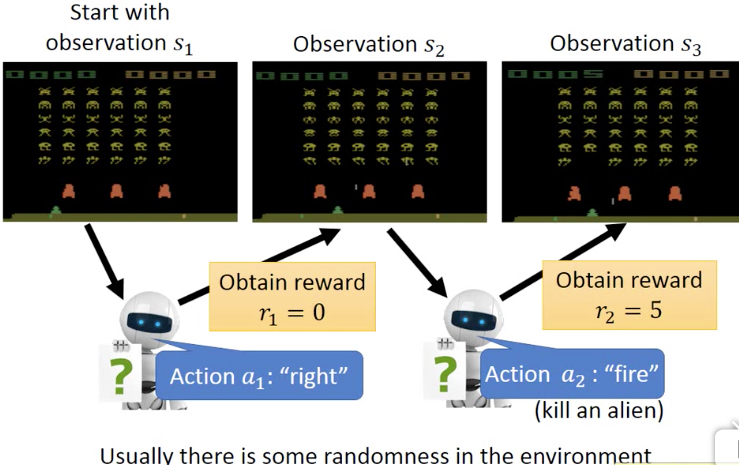
用video game来举例看下,实际的强化学习的过程,
每次看到游戏画面observation就是state
采取的actions,包含左移,右移,fire
杀死外星人就可以得到一定的reward
游戏从开始玩到gameove,称为一个episode,我们的目标,就是在一个episode中得到尽可能多的reward

强化学习,可以这样分类,
首先是Model-based和model-free,
model-based就是对环境有先验知识,比如下围棋,你读过棋谱,知道规则,那么你可以对环境后续的变化做出预判
model-free就是比较盲目的,不了解环境,只能试错
显然model-based的效率要好,但是很多场景没办法model-based,因为你确实也没有先验知识
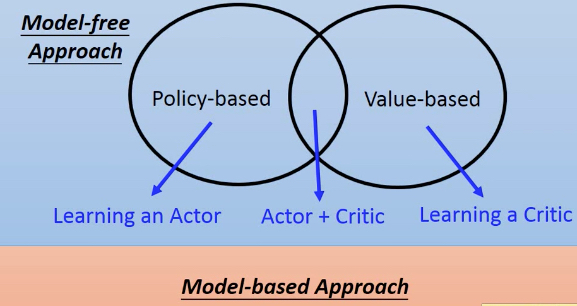
在Model-free里面,又分成Policy-based和Value-based
我们上面说强化学习的目标,就是学习policy,即即state和action的匹配关系
所以Policy-based的方法,是比较直接的方法,我把Actor/policy作为一个function,那么只要学习出这个function,问题就解决了
在Policy-based里面又可以分成on-policy和off-policy,一般看到的都是on-policy,就是和环境互动的agent就是学习agent本身
off-policy,和环境互动的agent和学习agent分开,不是同一个

而Value-based的方法,比较曲折,直接学习出policy function比较抽象,换个思路,学习一个critic,它会评价在某个state下的每个action
如果能学习出critic,那我们就可以通过他的评价,来选择最好的action,这个问题也就解决了
Q-learning就是典型的Value-based的方法,它是根据之前所有的经验来统计出当前state选择某个action,会得到的最终的Reward;但这种方法,缺乏泛化能力,对于没见过的case,无法处理,所以出现DQN用nn来拟合critic
Policy-based Actor
由于policy-based是比较新的技术,也是当前比较主流的技术,所以先介绍policy-based的方法,
Policy-based的方法,可以分成三步,

第一步先定义一个function,那么这里就用nn来作为一个actor
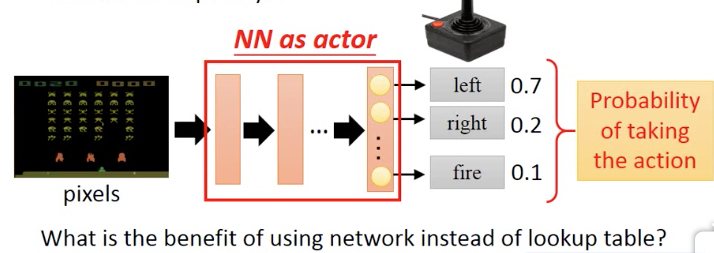
输入是游戏画面,输出是每个actions的probability,一般在选择action的时候要加入random,否则会缺乏exploration的能力,即每次相同选择,没有机会发现新大陆
第二步,怎么判断function的好坏?


判断一次episode的好坏,就是这个过程中获得的reward和
那么一个actor,会产生很多各种各样的episode,或trajectory,只要算出所有episode的R的期望,就可以用来衡量actor function的好坏
而期望实际上算不出来,所以用sample来近似,最终得到了右边的结果
第三步,如何找到其中最好的actor function
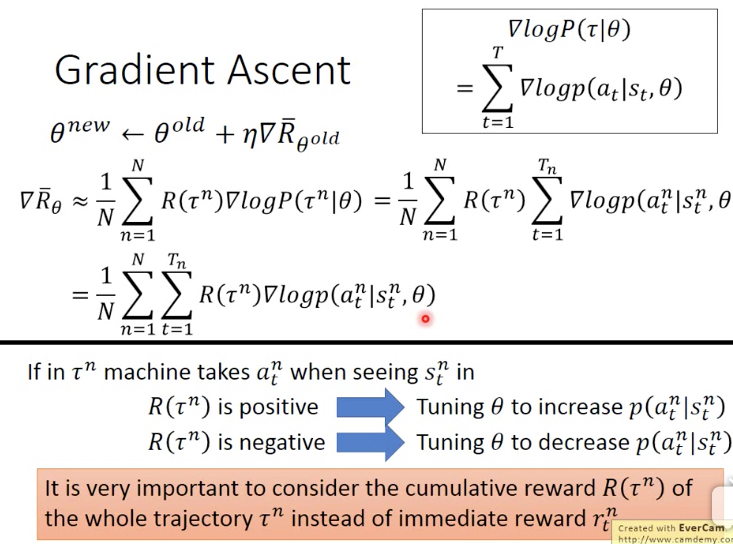
答案就是用Gradient Asent,来得到最优的actor function
那么下面就是对R的期望求gradient的问题,



最终R期望的梯度公式如下,
Tips
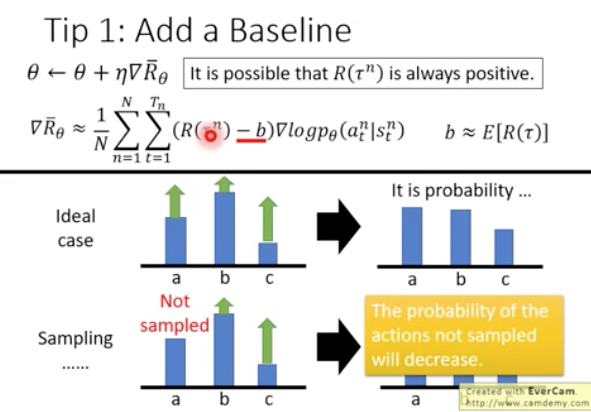
但这样的问题在于,比如对于游戏它的R可能都是正的,这样b, c会被sample到,那么他们的概率会被放大,而a其实reward比c大,但是由于没有被sample到,所以概率反而会被减小
所以增加一个baseline,大于这个baseline的reward才认为是正向reward,小于就认为是负向的reward
上面的算法还有一个明显的问题,我们在考虑一个action是正向还是负向的时候,考虑的是整个episode的reward和
很直觉的想法就是,最终的结果是正向的,并不代表过程中的所有action都是正向的,比如下左图,R=3基本都是由于a1这个action的reward,而a2,a3没有啥贡献,甚至产生负的reward
那么这个情况当sample足够多的情况下,是可以克服的,但是普通情况下sample都是不足够的
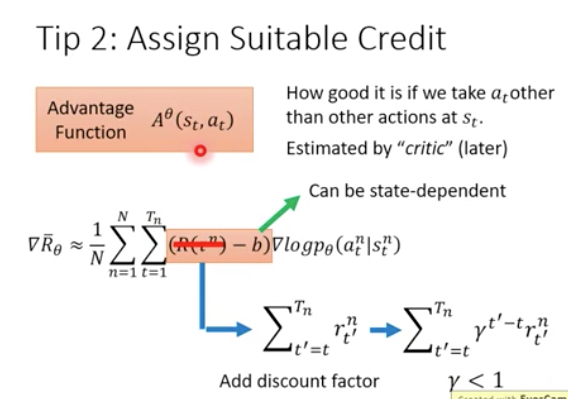
所以一个想法,当前的action只会对它后面的reward有作用,并且越靠近的reward受到的影响应该越大
所以这里会用action之后的reward和来替换整个episode的reward和,并且要乘上discount factor,让action的影响递减
替换部分称为advantage function,这个在后面的A3C算法中会看到

PPO (Proximal Policy Optimization)
前面的policy的方法都是on-policy的方法,下面介绍的PPO,当前是OpenAI的默认RL算法,是一种off-policy的方法
off-policy,就是和环境互动的agent和我训练的agent是两个不同的agent
为什么要用off-policy这么trick的方法?
因为on-policy,每次收集和环境互动得到的data,然后更新参数,更新完参数后,之前收集的data就没法继续用了,需要再和环境互动收集新的data
这样非常耗费时间
如果我们有个一个agent,它的参数是fix的,专门去和环境交互并收集data,然后用这些data去训练我们的当前的agent,这些收集的data就是可以被重用的
这个方法类比,你看别人打球,或下棋,然后从你观察到数据来用于自己学习

具体怎么做,这个首先基于一个理论,importance sampling,
如果我们要算一个分布P中x,对于f(x)的期望,如果不能直接求解,我们用的方式就是sample,在P中sample n个x,然后算平均
那么如果我们这时没法在P中做sample,我们有任意一个分布Q,我们在Q中做sample,仍然能算出f(x)在P上的期望
这个感觉很神奇,但是上面的推导确实给出公式
用这个理论还是有些问题的,
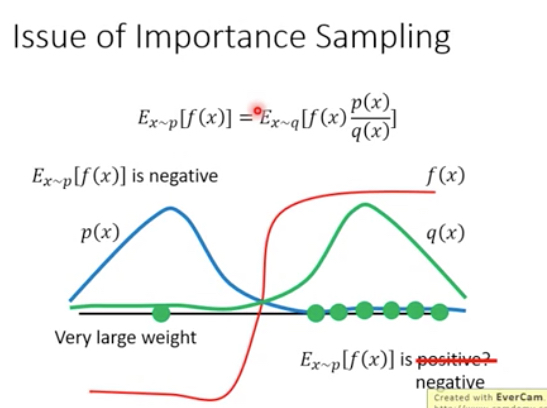
问题在于这个理论保证期望不变,但是方差是变化的,所以如果两个分布相差太远,方差会有较的差异
比较形象的例子,右图,如果P,Q的分布式相反的,这样去sample会导致,如果在P中sample那么绝大部分情况会集中在左边,而在Q中sample会集中在右边
这样会导致得到的期望完全不一样,当然如果sample足够多,这个问题是可以被克服的,因为小概率事件还是有可能会发生的,你在Q中也是有小概率会sample到左边的点

现在回到off-policy,我们要做的就是,用在一个agent上sample的数据,来计算在另一个agent上的reward和的期望

上面说到过,这里会用advantage function来优化这个R
第二步做的就是importance sampling的转换
第三步假设不同agent出现某个state的概率相同,所以把这项消掉,因为state和你选择啥policy没关系,也说的通
第四步得到off-policy的目标函数

这个算法就称为PPO,但是上面说了两个agent的分布如果差的很远会影响算法效果
所以一般会加上一个正则项,即两个分布的KL,这样会让两个分布尽可能的接近


这个PPO算法的问题是实现比较麻烦,尤其后面的那个KL
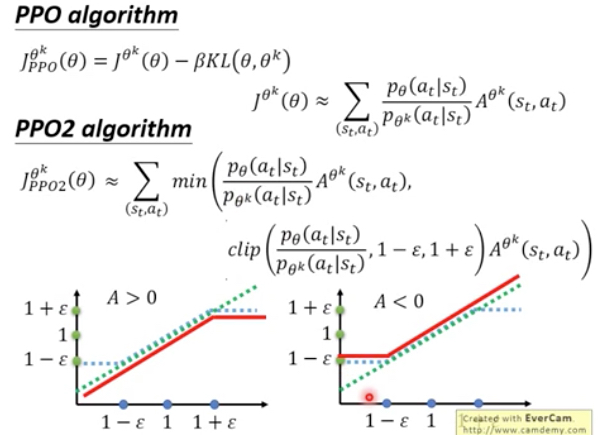
所以出现PPO2,这里去掉了KL,但是用clip来限制两个分布不相差太远
如果A是正向的,那么我们要尽可能增加学习agent的state|action的概率,但是当逼近和环境交互的agent的概率,就会停止,因为min会限制住它
如果A是负向的,反之尽量降低这个概率,但是同样只能逼近另一个概率
Value-based Critic
Critic不决定采取什么action,而只是评价actor好坏
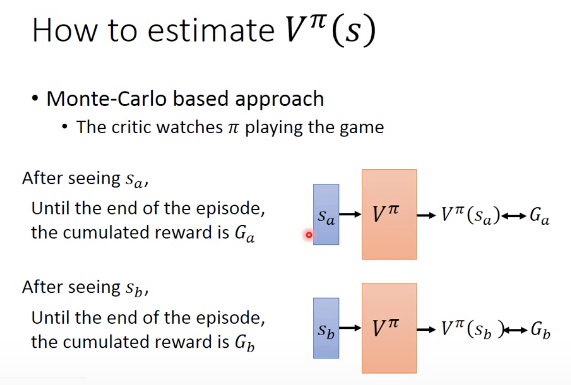
对于Critic,就是要训练一个function V,输入是某个actor和state,输出是从state到episode结束的reward总和

那么如何训练Critic?
两种方法,
Monte-carlo方法,直觉的方法,V不就是要拟合整个episode的reward吗,那就对于该actor和一个state,会得到实际的reward G,那么V只要去逼近G就可以完成训练
Temporal-difference方法,这个就有些trick,两个相邻状态V应该相差这步的reward,那么就用这个差值来拟合V,这个方法的好处就是不需要等episode结束,每一步都可以train

两个方法的不同,
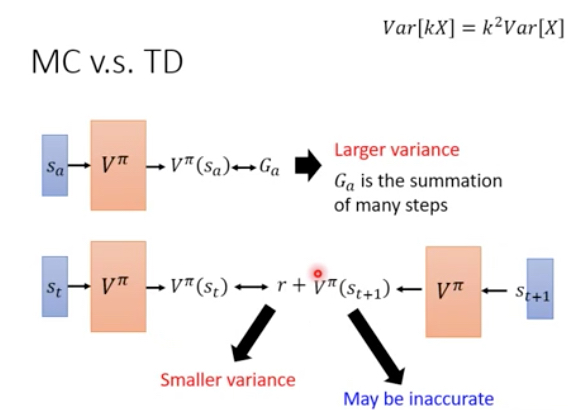
MC方法的varianc会比较大,因为每次从Sa出发,最终得到的结果G可能会有很大的差异,因为环境和model都有随机性,而G是多步叠加的结果,所以Var会很大
TD方法,因为r只是一小步的reward,所以这个Var就会相对比较小,但是TD,根据一步训练,所以会有偏差

Q-learning
上面学习到V,只是知道当前state下最终会得到的reward是多少,但是并没有办法根据V去选择action

所以我们需要一种新的Critic,Q,给出在当前state下,选取某个action得到的reward和
如果我们得到Q,那么就很容易选择下一步的action,选reward最大的好
这样就不需要训练单独的actor和policy,因为通过Q可以推导出policy,这就是Q-learning
由于Q-learning,每步需要找出最大的Q,所以如果action是连续的,就会比较麻烦,需要gradient descend;但是对于离散的action就会很简单,穷举就好
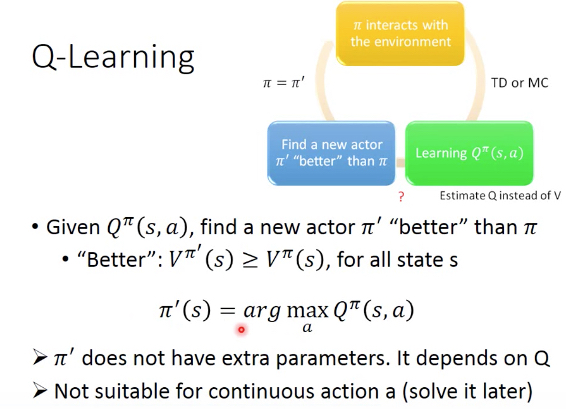
这里形式化的表达,只需要每一步state都选取最大的Q,我就可以得到一个更好的actor
这是非常直觉的一个事情,如果我通过Q可以知道选取哪个action可以得到更大的reward,那么当然应该选择该action
这里给出形式化证明,

Q-learning算法
那现在的问题就是如何学习Q?训练的时候有一些tips
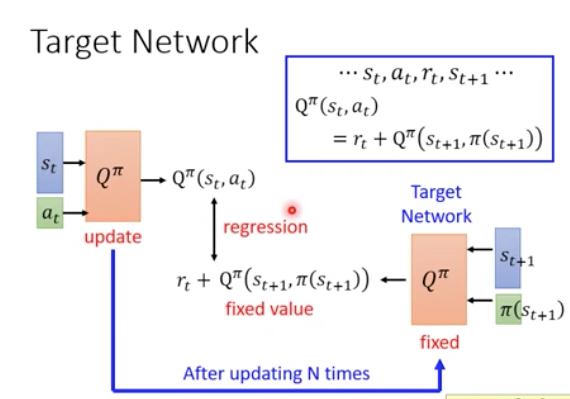
Target Network
你可以用TD的方法,仍然是两部之间差一个rt
实现的时候,这里有两个Q,虽然参数上应该是一样的,但是训练的时候会fix住一个的参数,称为TargetNetwork,让另一个去逼近;然后再把参数同步过去,再去逼近,这样实现更容易些
Exploration
增强学习的时候,要去尝试新的选择,因为保守的选取之前尝试过的case,可能会错过最优解
基本策略是加入随机性,比如大概率选MaxQ,但有小概率会random;在训练的前期,exploration比较关键,而到了后期,你已经尝试过所有case的情况下,exploration就没有那么关键了,所以这个概率可以随着学习的过程decay

Replay Buffer
不光当前policy actor和环境交互的数据被记录下来,之前的actor和环境交互的数据也会被记录下来
训练的时候从buffer中选取一个batch,这个里面有可能包含一些其他actor的交互数据,这样训练的鲁棒性会比较强,而且大大节约actor的交互时间

加上这些tips,典型的Q-learning算法,
两个Q,一个作为target network
在和环境互动的时候,加入epsilon greedy,增加exploration的能力
将互动得到的数据放入buffer,然后从buffer中随机sample一批数据作为训练数据去计算target network Q^
不断的让Q去逼近这个Q^,n部后,把Q的参数同步给Q^

Adanced Q-learning
Double DQN
DQN有个问题,就是Q的value会被over estimate
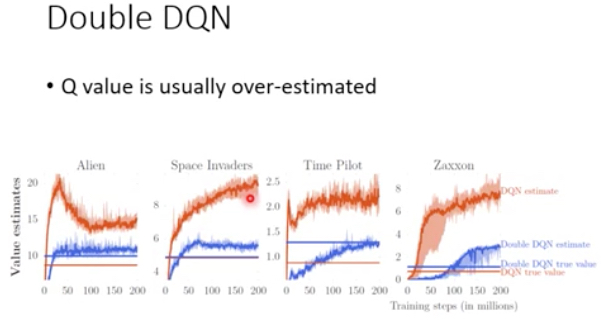
因为Q一定是有误差的,或大或小,但是由于训练过程中总是选Max Q,所以会总是选到被高估的action
Double DQN,就是用两个Q函数而不是一个,这样一个Q决定如何选择action,另一个Q用于计算reward,这样只要不是两个Q都over estimate某一个action,就不会有太大的问题


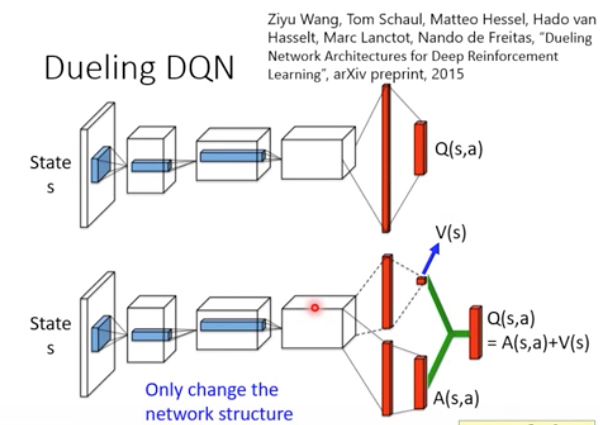
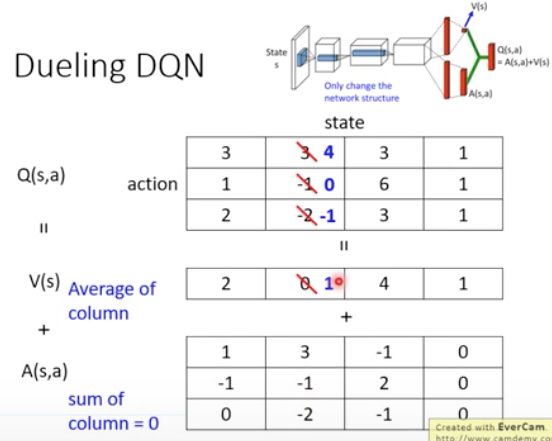
Dueling DQN
这个方法其实就是改了下网络结构,加了一层,但是这样为何就比原来的好?
右图,这个方法会通过加约束,让算法倾向于修改Vs,而不是A,这样通过sample到case的学习的结果,就可以影响到未sample到的case
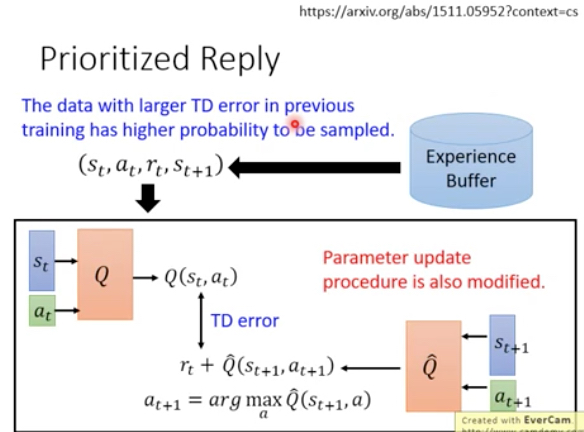
Prioritized Reply
从buffer里面sample测试集的时候,不是随机的sample,而是挑选那些在上一次training中TD error比较大的data
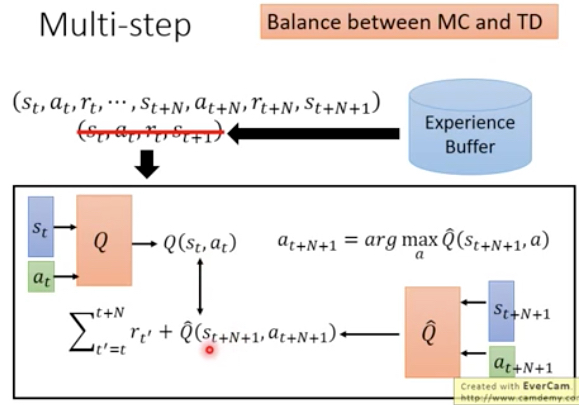
Multi-step
MC是整个完整的episode做完后,才能train
而TD是完成一步以后就可以train
自然的想法是balance一下,mini-batch,若干步后用TD training
Noisy Net
增加noise是为了增加模型的exploration能力
之前的方法是noise on action,即选择action的时候,会小概率加入随机action
当前的方法称为noise on parameter,即在episode开始的时候,在Q的nn的参数上加入一定的noise
这样做的好处见右图,noise action不确定性太大


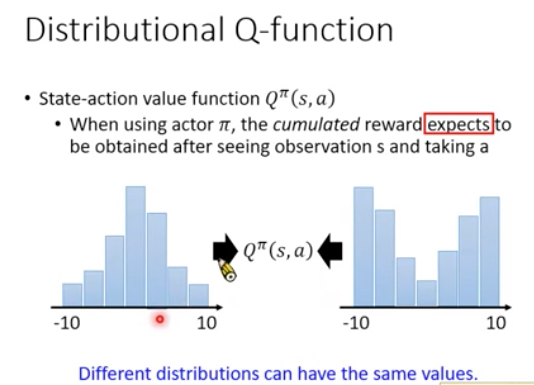
Distributional Q-function
原先Q,是一个期望,在s状态,采取a后,得到的reward总和的期望,平均值
但平均值不能很好的反应出数据,左图中两个分布的平均值一样,但是分布相差很远
所以对于Q我们不光只输出一个期望值,而是输出一个期望的分布,比如右图,对于每个action,输出5个值,表示不同期望区间的概率分布

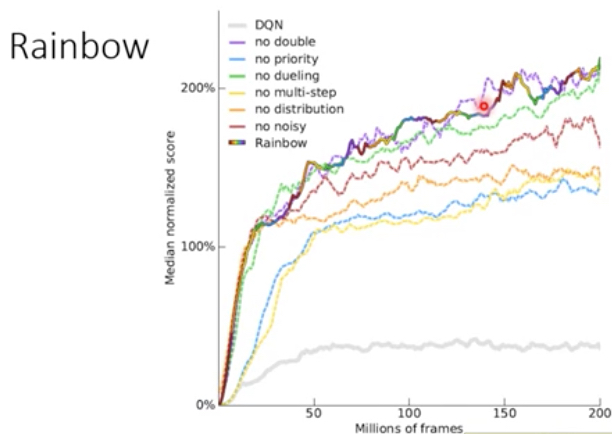
那么这些技术tips的效果到底如何?
Rainbow是结合所有的tips所达到的效果,可以看到还是非常不错的
其他的线表示单独加上一种tip时候,对性能的影响
右图,是反映在rainbow中,去掉某一种tip时的效果,可以看到去掉multi-step或priority时,性能会下降很大

Continuous Action
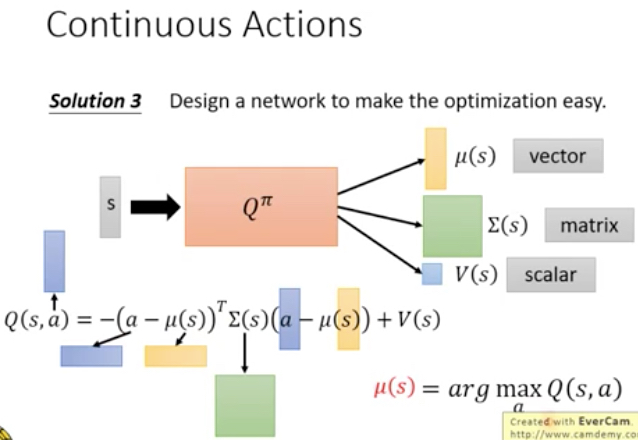
Q-learing对于离散的action是比较好处理的,如果是连续的action应该如果去做
Sample是比较简单的方法,但是不准确;gradient asent太费了
第三种方法,比较匪夷所思,设计一种网络Q,让他比较容易算出max,如下图定义Q(s,a),当a=u(s),第一项为0,整个就取到max值

A3C
A3C,一共3个A,一个C
其中一个A和C,表示同时使用Actor和Critic,即policy-based和value-based
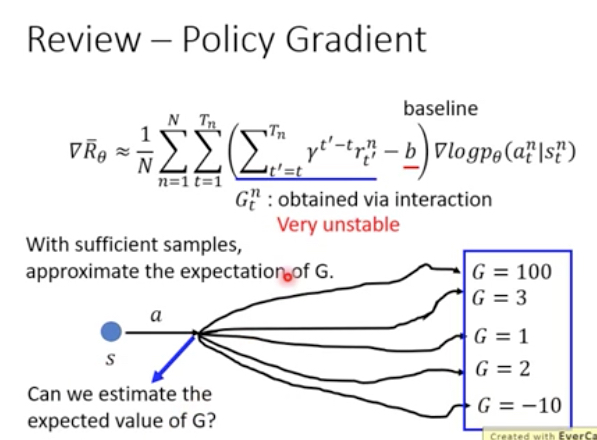
那么直接用policy-based,有啥不好?
可以看到policy-based做梯度上升的时候,是需要用到G,即整个episode的reward和
这样要求一个episode结束后才能开始训练,并且这个G的variance是非常大的,就是非常不稳定
那么既然现在我们有一个critic,而critic可以预测出G的期望,那么是否可以用来替换G?这样就可以做到每一步都能训练,并且提供稳定性
如下左图,G的期望就等价于Q,而baseline,我们用V来替换,因为V表示在状态St所得到的reward期望,而我们采取的action a时,所得到的reward要高于这个才是有价值的
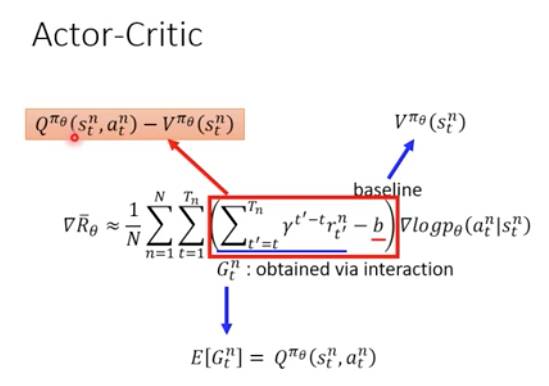

但是这样,我们要同时训练Q和V两个function,所以Advantage Actor-Critic,所做的是用V来近似表示Q,这样我们只需要训练V这一个function,
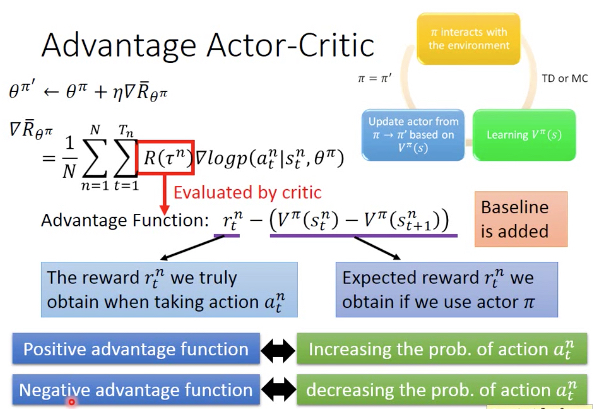
Advantage Function的定义也很直觉,后面括号中的部分是用Critic预测走这一步所会得到的reward,这个可以看做是一个baseline
如果我们实际这一步得到的reward大于baseline,那么我们就认为这步是正向的,否则是负向的
A3C设计的Tips,
首先actor和critic可以共享部分网络,这个是显然的,因为输入都是s,比如游戏画面,输出虽然有不同,但是前面大部分的网络可以共享
用output entropy作为Actor输出的正则项,即Actor会有机会倾向于去尝试不确定的action,这样模型会比较好的泛化能力

最后一个A,异步,这个比较工程的想法,就是用多组actor-critic同时来训练和更新参数,更快的收敛
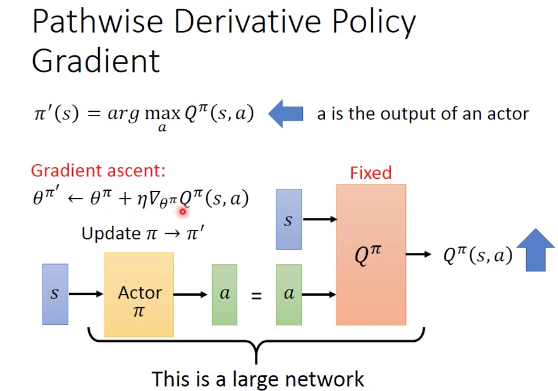
Pathwise derivative policy gradient
本身Q-learning得到的Q,就可以决定选择哪个action,前面说了这样对于连续性的action就很麻烦
这个方法说,不,critic只能评价,不能直接决定action
还是要训练一个actor决定采取什么样的action
这时其实是把Q作为supervisor
训练的方式就是把actor和Q连成一个大的nn,固定住训练好的Q的参数,训练actor的参数,使得最终的输出最大化
然后再用更新过的actor和环境互动,进一步去训练Q,周而复始
最终使用的时候,直接用actor就可以,不用管Q
这个方法的最大价值,是它可以类比GAN,
Actor是generator,Q是Discriminator,很有意思
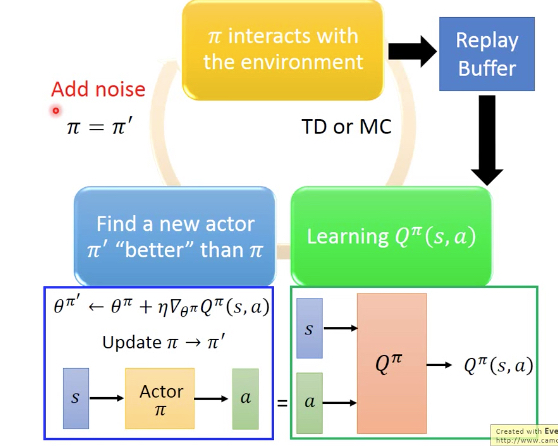
这里有两个tips,
第一个,replay buffer,即在训练Q的时候,会把所有actor和环境的互动的过程都记录下来,用于训练Q,这样更加robust
第二个,actor的输出要加随机noise,泛化和exploration的能力
这里给出一个实际的算法实现对比,左边是经典的Q-learning,右边通过4步的变化,成为Pathwise Derivative Policy Gradient
第一步,用actor π来觉得采取什么action,而不是用Q
第二步,用target actor π^的输出作为Q^的输入
第三步,Fix住Q,调整actor π的参数,使得Q最大化
第四步,更新π^,Q^


Imitation learning
有些场景下,不太好定义出reward
比如说自动驾驶或chatbot
如果不能明确定义出reward function,我们就无法用RL去训练
这时的思路,就是imitation learning,意思是用expert的示范来告诉你应该怎么做,比如比较典型的是自动驾驶,通过看大量人类驾驶的录影来学习
这里最直观的就behavior cloning,即expert怎么做,你照搬就好,这就是典型的supervised学习
这个方法的缺点,就是会有盲区,如果没有看到过这个场景的例子,机器会不知道该怎么办,比如人开车很少会撞墙,所以机器当快撞墙时,就没有经验可以借鉴
第二个缺点,就是expert并不是所有的行为都是有用的,或有益的,而单纯的clone这些行为是没有意义的
所以比较科学的方法,加做Inverse Reinforcement Learning
普通的RL,是通过定义reward function,来训练出actor
而如果我们不知道reward function,就需要先通过一堆demonstration来找到真正的reward function


如何找?
类似GAN的过程,
我们用Expert的一堆操作作为positive的例子,而随机产生一个actor的操作作为negative的例子,这里actor是一个nn,可以看成generator
我们来训练一个Reward function,也是一个nn,使得它能分辨出expert的操作优于actor的操作,可以看出Discriminator
然后我们用新的reward function来训练一个新的actor,再用新actor产生的操作作为negative例子,进一步的去更新reward function。。。。。。
