SqlTaskManager
Worker的SqlTaskManager负责接收发来的TaskRequest,
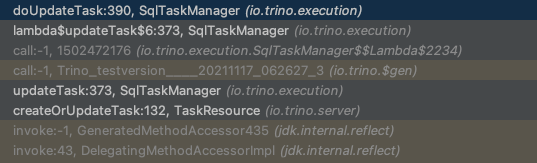
doUpdateTask
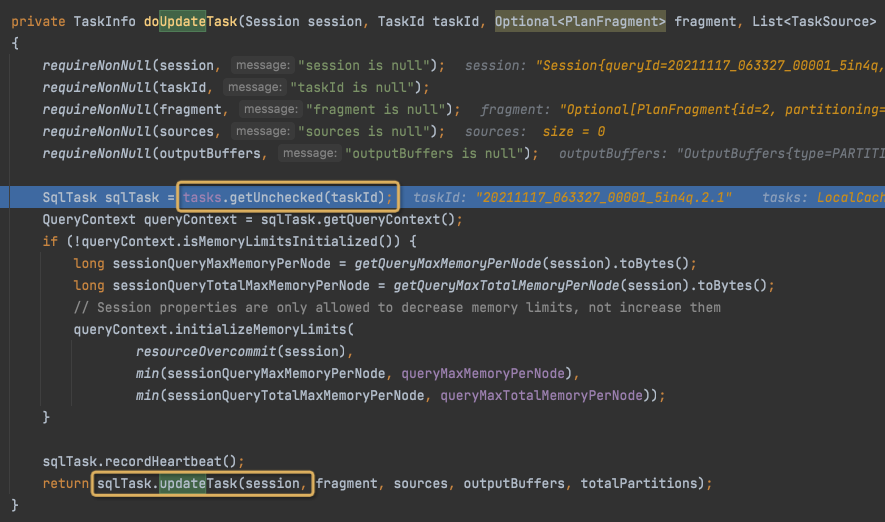
Get或创建SqlTask,仅仅新的Task需要创建,
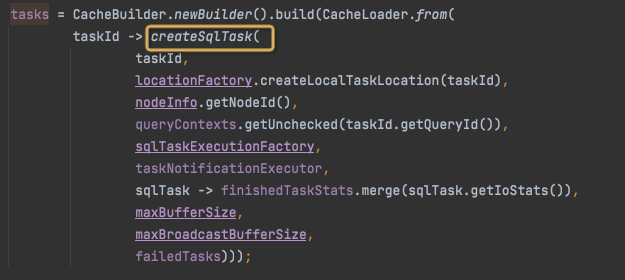
tasks是LoadingCache<TaskId, SqlTask>
最终调用updateTask,
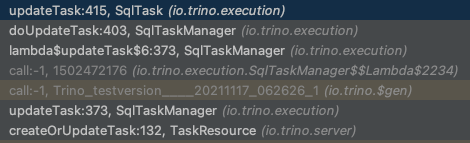
生成SqlTaskExecution,
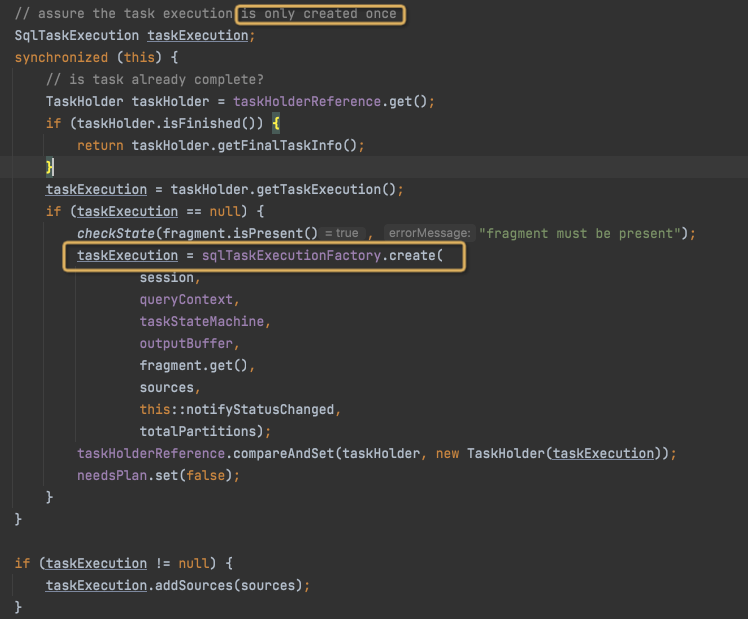
sqlTaskExecutionFactory.create
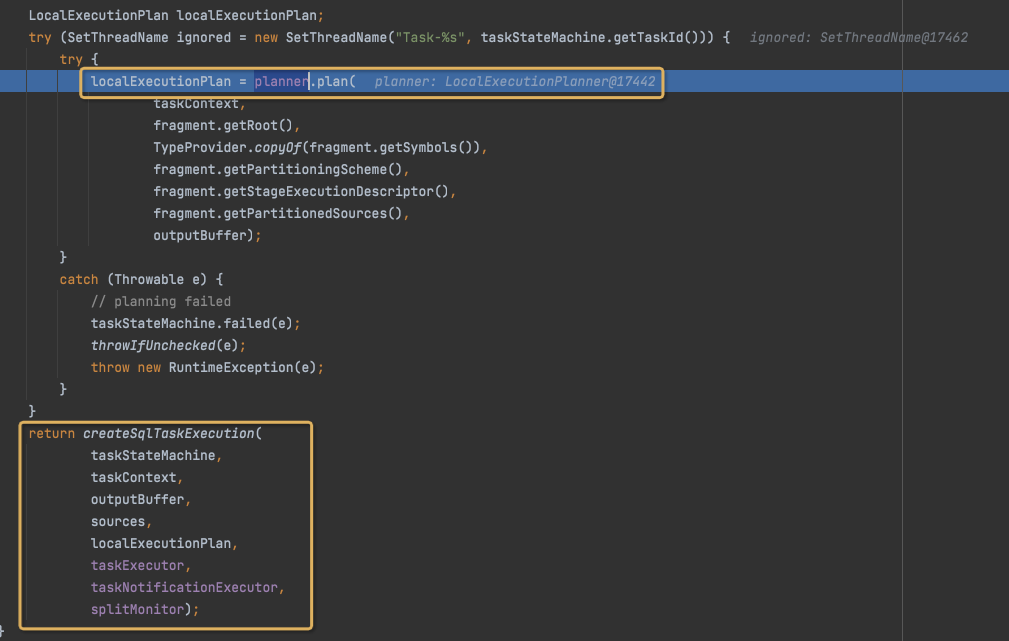
LocalExecutionPlan
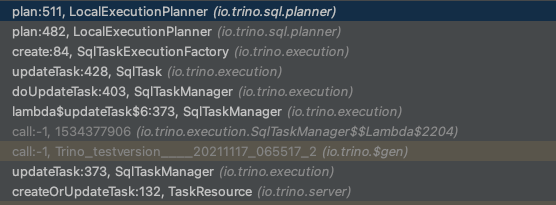
首先将PlanNode,通过Visitor模式,替换成PhysicalOperation,
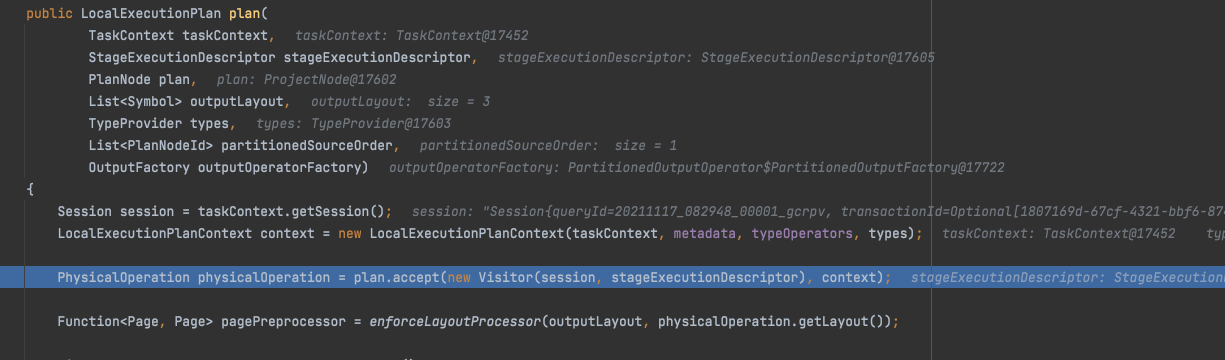
比如对于Fragment2,
PlanNode,

变换成PhysicalOperation,
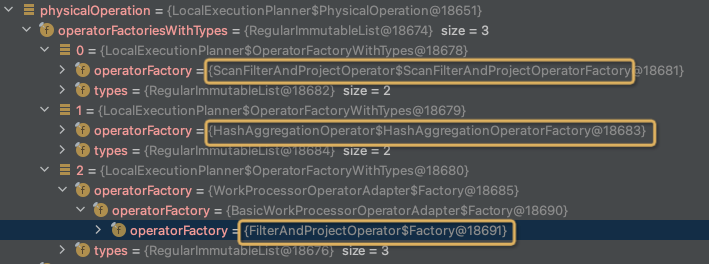
将PhysicalOperation生成DriverFactory,
这里的context是LocalExecutionPlanContext,static类,不同线程的DriverFactory会加入到同一个context对象的driverFactories中
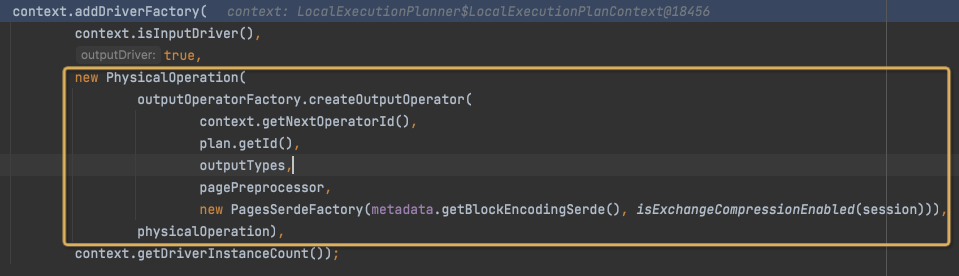
之前会加一层PhysicalOperation,
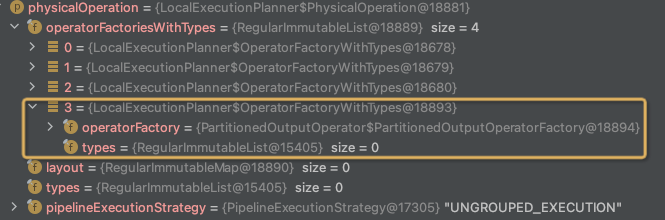
生成DriverFactory,加到driverFactories中,
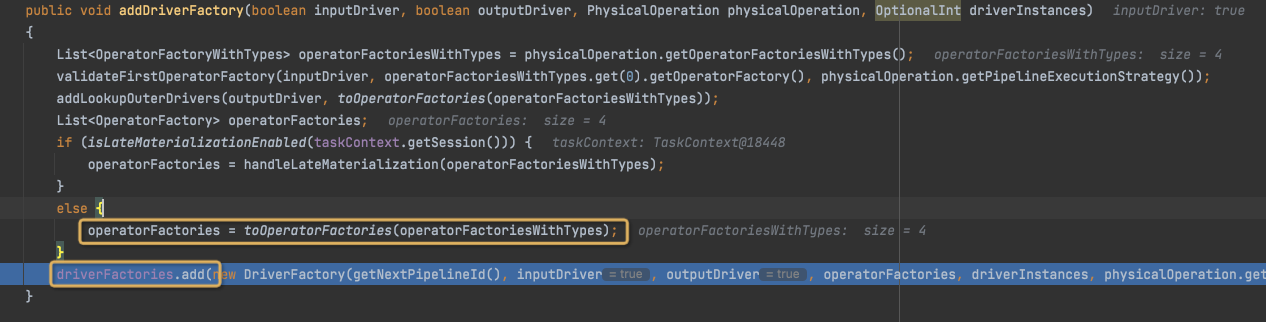
结果是这样,
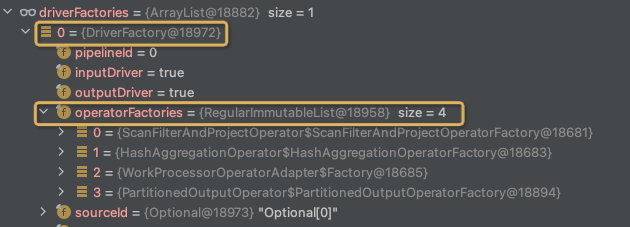
最终生成LocalExecutionPlan并返回,

从而完成SqlTaskExecution的创建,

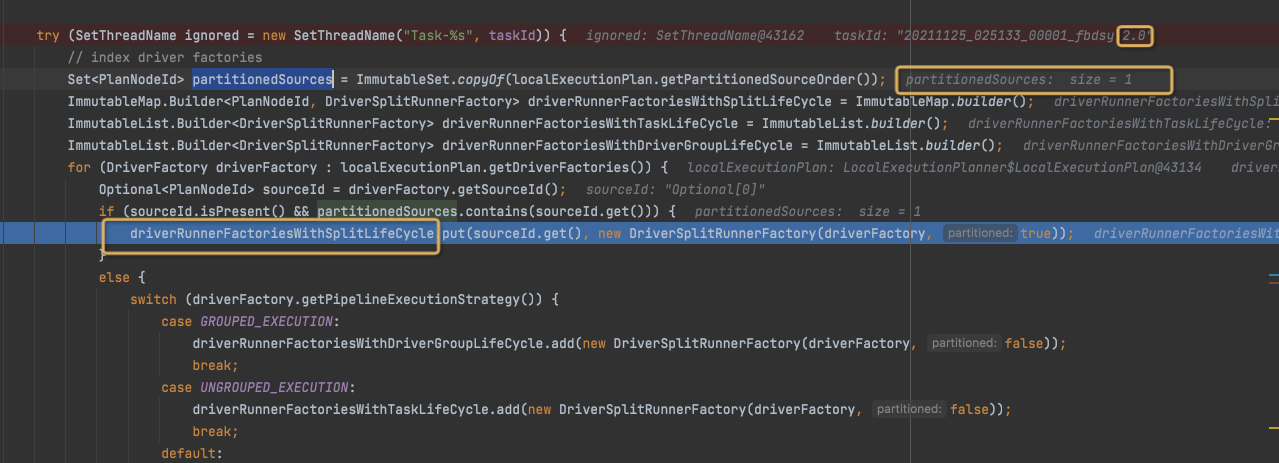
这里会将localExecutionPlan中的所有driverFactory,放入三种容器,driverRunnerFactories,
分别是,SplitLifeCycle,TaskLifeCycle,DriverGroupLifeCycle
区别是,
TaskLifeCycle的driver,是Task级别全局的,Task执行的时候按照并行度启动,一直跑到Task结束
SplitLifeCycle的driver,对于每个split都需要run一个driver,一个split跑完了,driver就结束了,对于新的split要启动新的driver
DriverGroup,参考,https://prestodb.io/blog/2019/08/05/presto-unlimited-mpp-database-at-scale
思路就是考虑分片,这里会提出lifespan的概念,
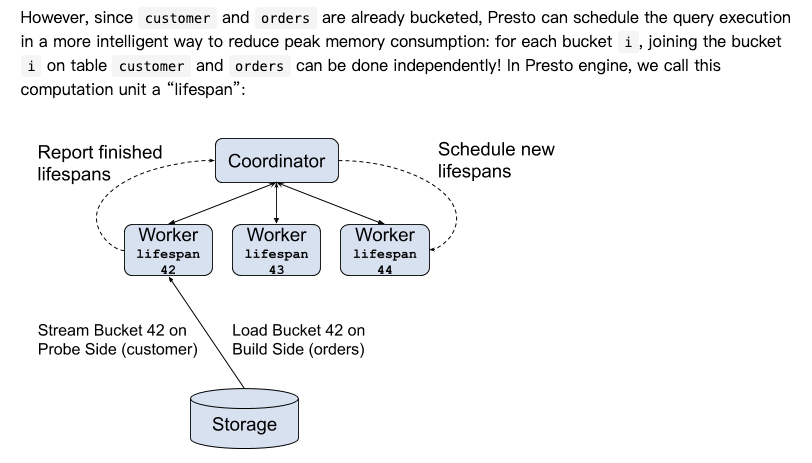
这里Fragment2是带source的,所以会被放入SplitLifeCycle
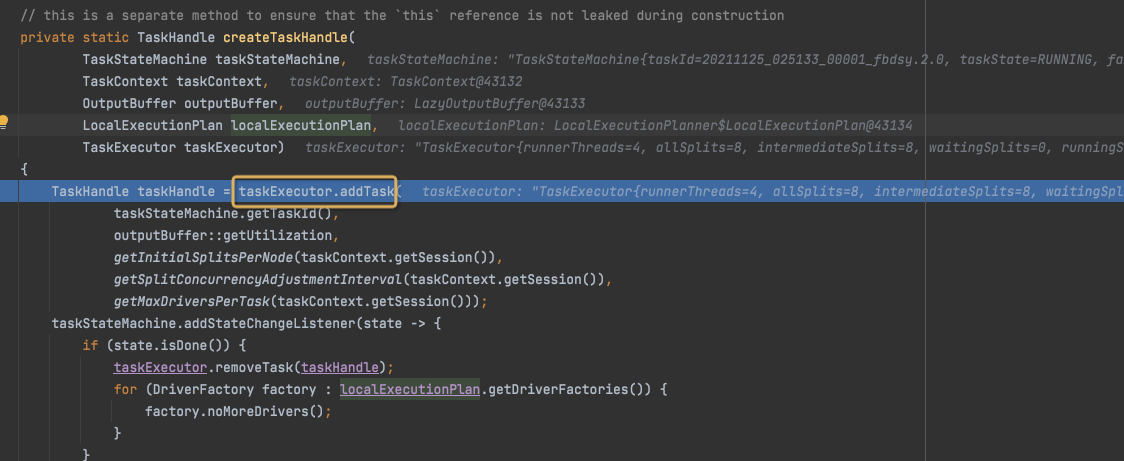
继而调佣createTaskHandle,

最终是生成TaskHandle,放入TaskExecutor的task队列中,
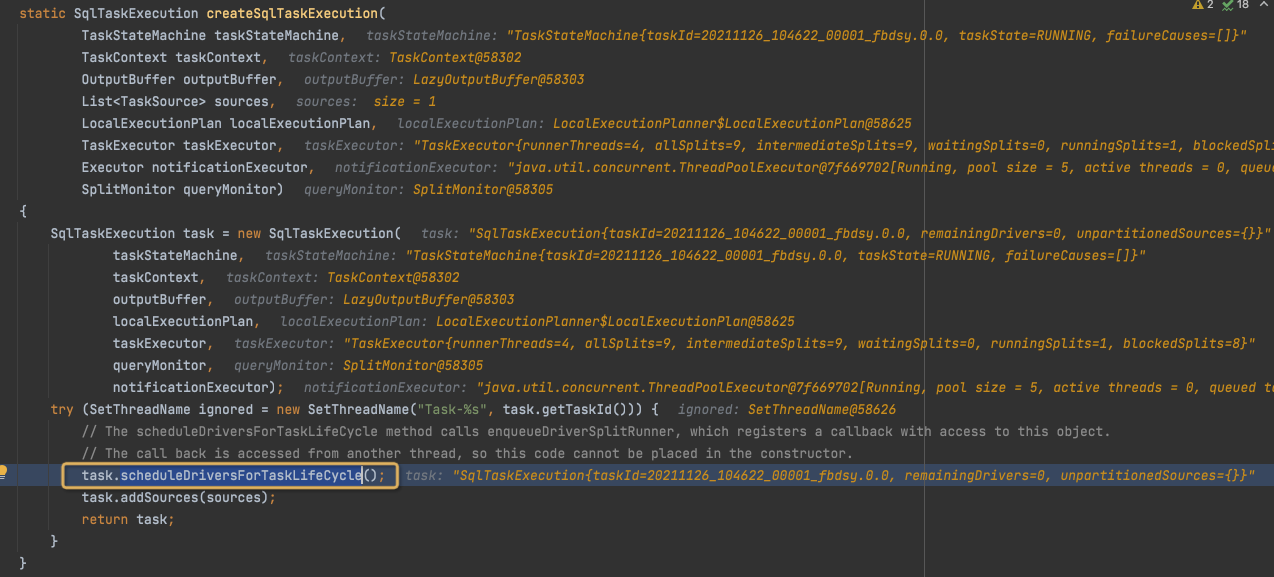
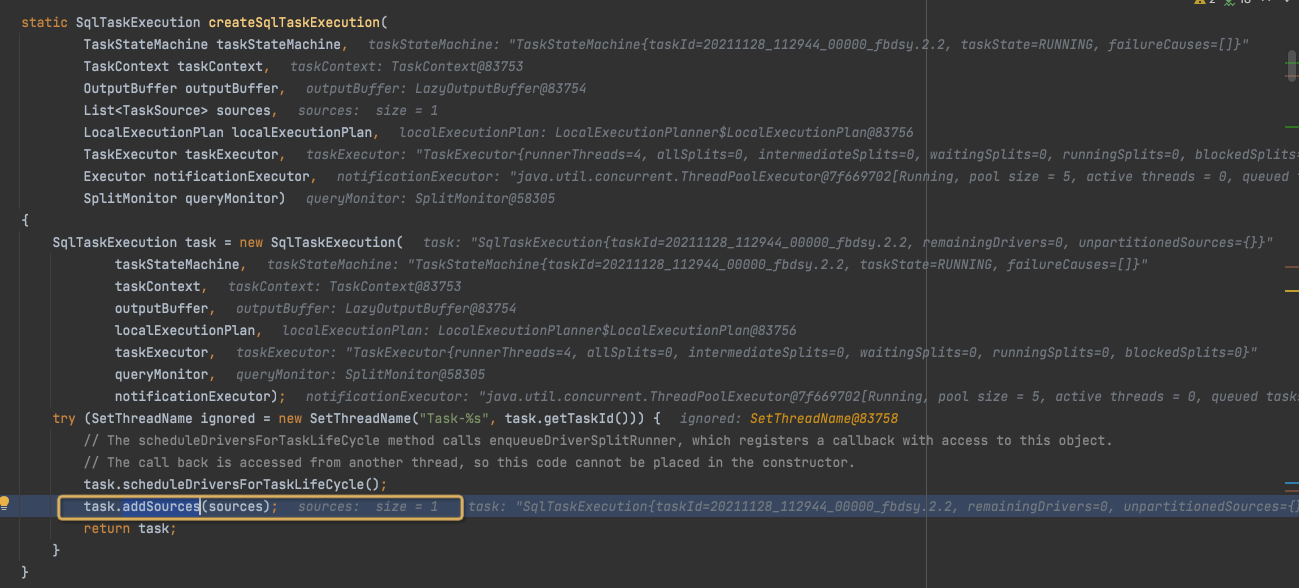
在createSqlTaskExecution中,继续调用scheduleDriverForTaskLifeCycle,
来调度TaskLifeCycle的drivers,
前面Fragment2有source,所以是SplitLifeCycle,
但是对于Fragment0,Fragment1,为TaskLifeCycle
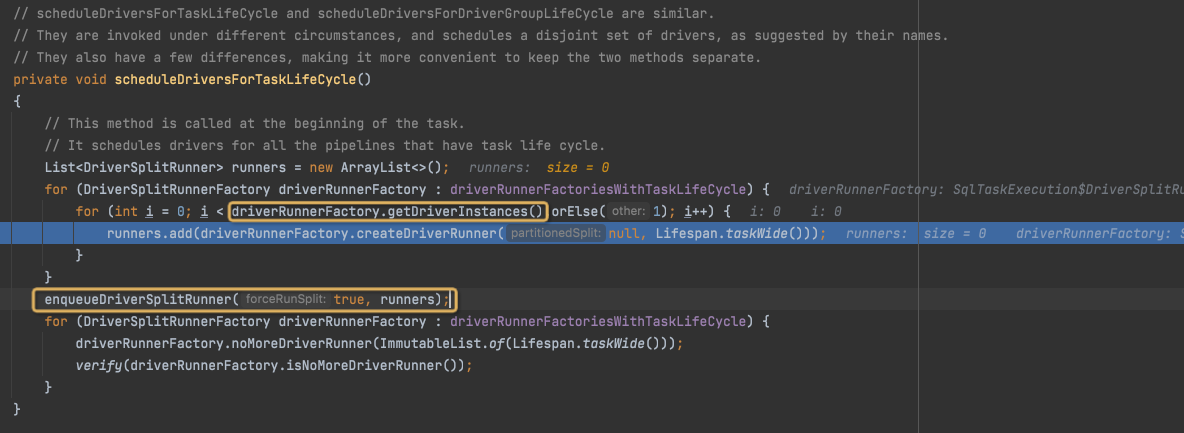
对于Fragment0,一共两个driverFactories,driverinstances一共4+1,5个,这个代表每个driver的并发
所以一共创建5个DriverSplitRunner,
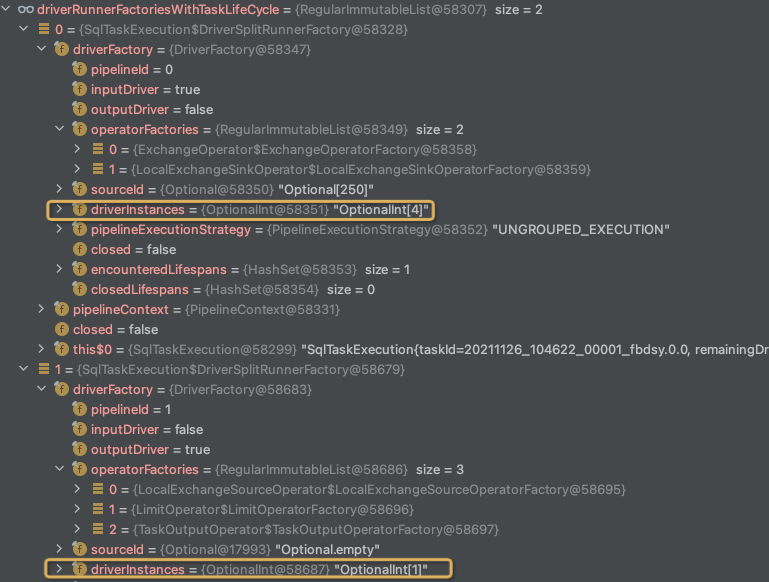
而对于Fragment1,一共产生8个DriverSplitRunner,

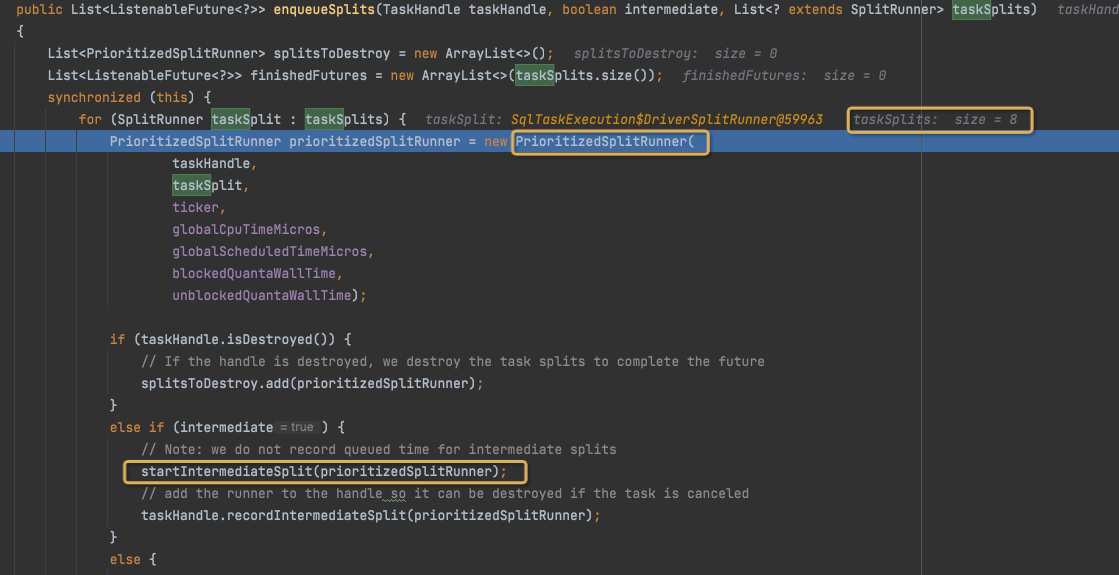
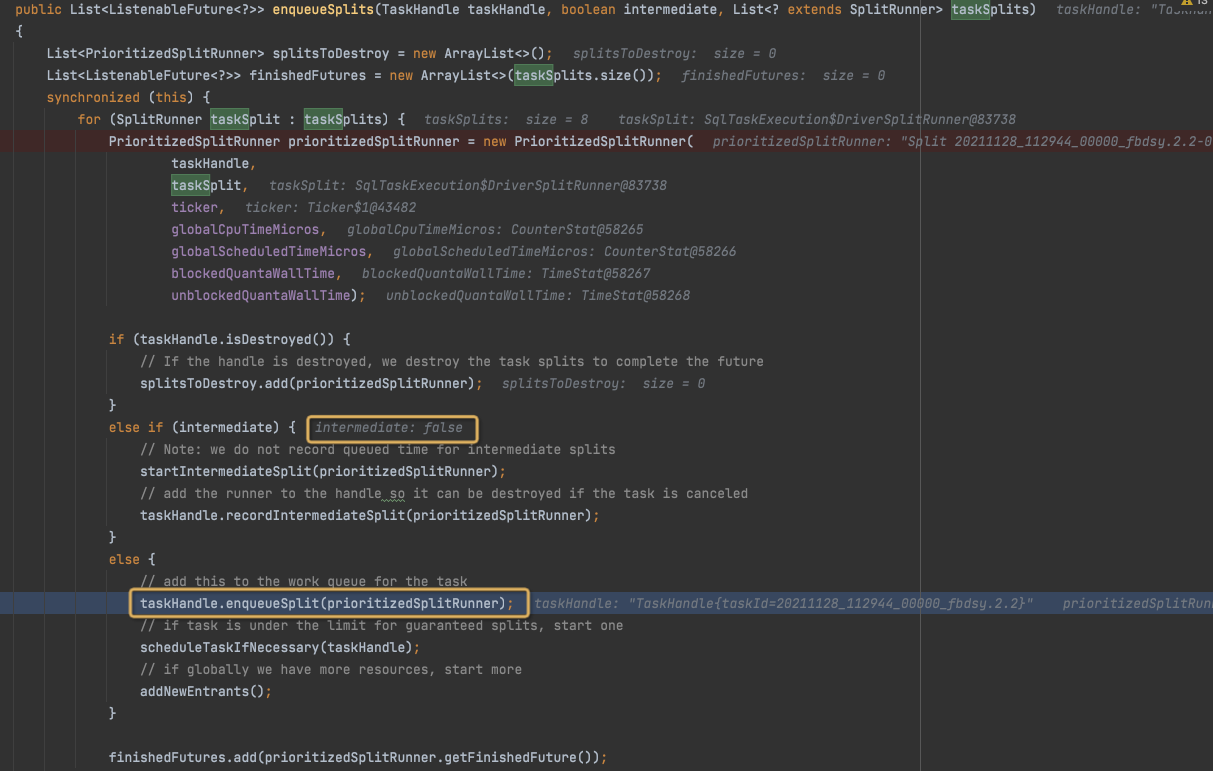
enqueueSplits中,
生成PrioritizedSplitRunner,并放入waitingSplits
注意这里的几个list是在TaskExecutor上的,记录的是所有task的splits统计,

allSplits,包含waiting,running和blocked,在start的时候同时加入到all和waiting
intermediateSplits,非leafSplits,并且intermediateSplits是直接start的,没有queued的状态
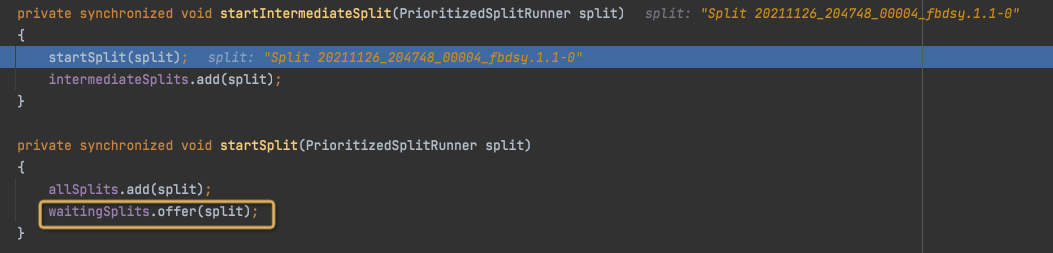
在createSqlTaskExecution中,继续调用addSource来调度SplitLifeCycle
可以看到是先调度TaskLifeCycle,再调度SplitLifeCycle,队列后进先出?
那么对于Fragment2,如下,
enqueueSplits中和前面不同的是,这里不是中间节点,
所以调用路径不同,
最终是加到,queuedLeafSplits中,这个是准备状态等待调度
对比上面,对于LeafSplits,有queuedLeafSplits和runningLeafSplits状态
注意这个状态是Task级别的,为何Leaf要保留task级别的状态,因为split和Task是耦合的

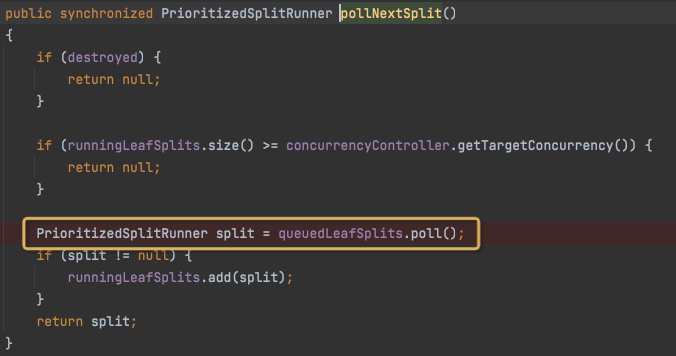
当在pollNextSplit的时候,变成running状态,放入runningLeafSplits,这是改的TaskHandle的状态
进而还是要调用start,放入waiting和all,这是TaskExecutor的状态,很confuse,刚开始没注意被绕进去了

并且这里在enqueueSplit完后,还要干两件事,
scheduleTaskIfNecessary和addNewEntrants,除了这里,还会在splitFinished的时候被调用,两个地方一边是,产生splits的时候看看是不是可以马上执行,一个是在一个split执行完后调度新的
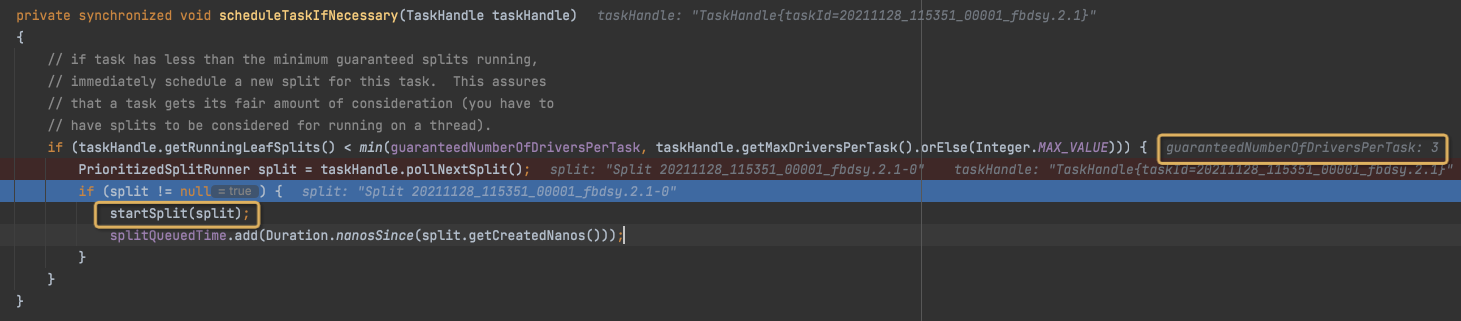
scheduleTaskIfNecessary
首先是判断这个Task的runningLeafSplits数目,是不是小于guaranteedNumberOfDriversPerTask,这里是3,也就是对于一个task同时执行的leafSplit不能小于3
这个是Task内部调度,保证每个Task有足够的LeafSplits在同时执行
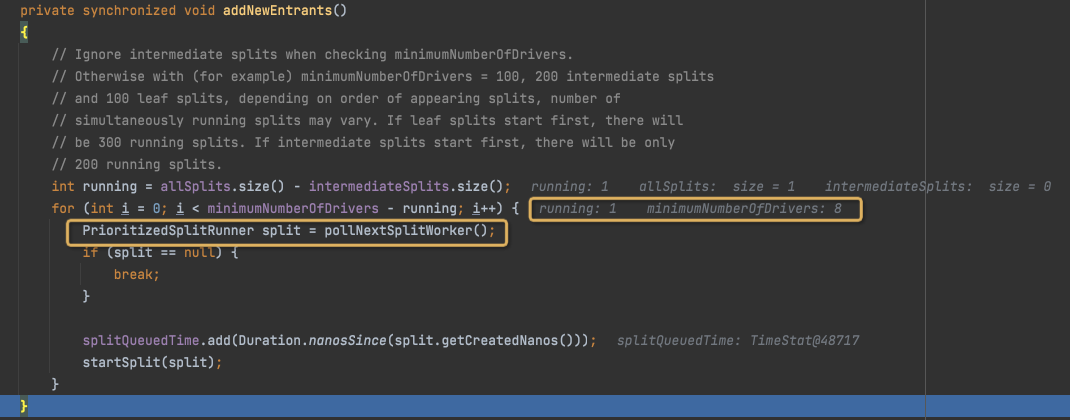
addNewEntrants
这个注释没看懂,反正意思就是不考虑intermediateSplits
这个和上面的不同在于是从整个TaskExecutor去考虑,
All代表所有被执行的splits,减去intermediate的,那么就是所有running的Leaf的多少
如果小于minimumNumberOfDrivers,这里是8,那么就调用pollNextSplitWorker,意思控制这个TaskExecutor中正在执行的LeafSplits的个数
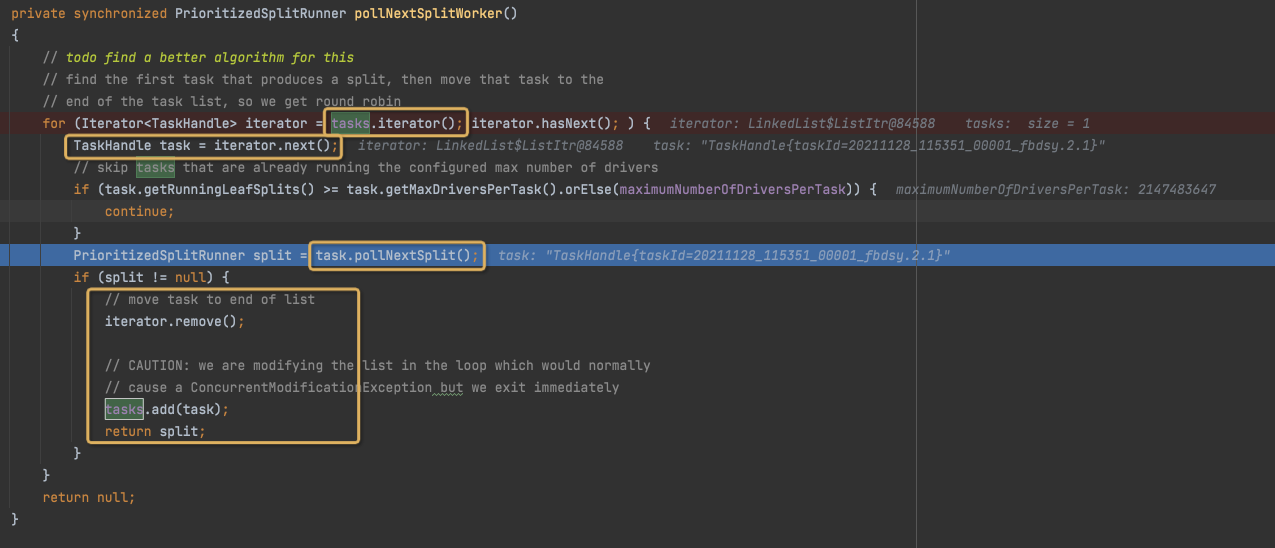
pollNextSplitWorker,
遍历Tasks,round robin的找到一个能poll split的task,并把这个task放到队尾
这是在全局层面调度split,和上面的task级别的配合?