Introduction
引入Shared-nothing架构
Shared-nothing architectures have been the foundation of traditional query execution engines and data warehousing systems.
In such architectures, persistent data (e.g., customer data stored as tables) is partitioned across a set of compute nodes, each of which is responsible only for its local data.
Such shared-nothing architectures have enabled query execution engines that scale well, provide cross-job isolation and good data locality resulting in high performance for a variety of workloads.
Shared-nothing的问题
However, these benefits come at the cost of several major disadvantages:
Hardware-workload mismatch:
Shared-nothing architectures make it hard to strike a perfect balance(达到完美平衡) between CPU, memory, storage and bandwidth resources provided by compute nodes, and those required by workloads.
For instance, a node configuration that is ideal for bandwidth-intensive compute-light bulk loading may be a poor fit for compute-intensive bandwidth-light complex queries.
Many customers, however, want to run a mix of queries without setting up a separate cluster for each query type.
Thus, to meet performance goals, resources usually have to be over-provisioned(过度预留); this results in resource underutilization(利用不足) on an average(平均而言) and in higher operational costs.
Lack of Elasticity:
Even if one could match the hardware resources at compute nodes with workload demands, static parallelism and data partitioning inherent to(固有的) (inelastic) shared-nothing architectures constrain adaptation to data skew and time-varying workloads.
For instance, queries run by our customers have extremely skewed intermediate data sizes that vary over five orders of magnitude (§4), and have CPU requirements that change by as much as an order of magnitude within the same hour (§7).
Moreover, shared-nothing architectures do not admit efficient elasticity; the usual approach of adding/removing nodes to elastically scale resources requires large amounts of data to be reshuffled.
This not only increases network bandwidth requirements but also results in significant performance degradation since the set of nodes participating in data reshuffling are also responsible for query processing.
当前数据和负载的变化又加剧了问题
Traditional data warehousing systems were designed to operate on recurring queries on data with predictable volume and rate,
e.g. , data coming from within the organization: transactional systems, enterprise resource planning application, customer relationship management applications, etc.
The situation has changed significantly.
Today, an increasingly large fraction of data comes from less controllable, external sources (e.g. , application logs, social media, web applications, mobile systems, etc.) resulting in ad-hoc, time-varying, and unpredictable query workloads.
For such workloads, shared-nothing architectures beget high cost, inflexibility, poor performance and inefficiency, which hurts production applications and cluster deployments.
针对上述的问题,提出snowflake,key insight是计算和存储分离
To overcome these limitations, we designed Snowflake — an elastic, transactional query execution engine with SQL support comparable to state-of-the-art databases.
The key insight in Snowflake design is that the aforementioned limitations of shared-nothing architectures are rooted in tight coupling of compute and storage, and the solution is to decouple the two!
Snowflake thus disaggregates compute from persistent storage;
customer data is stored in a persistent data store (e.g. , Amazon S3 [5 ], Azure Blob Storage [8 ], etc.) that provides high availability and on-demand elasticity.
Compute elasticity is achieved using a pool of pre-warmed nodes, that can be assigned to customers on an on-demand basis.
SF设计有两个核心的ideals,使用定制开发的存储系统来存放临时或中间结果数据;并且用定制存储系统用于对象存储的cache(write-through,直写)
Snowflake system design uses two key ideas (§2 ).
First, it uses a custom-designed storage system for management and exchange of ephemeral/intermediate data that is exchanged between compute nodes during query execution (e.g. , tables exchanged during joins).
Such an ephemeral storage system was necessary because existing persistent data stores [5 , 8 ] have two main limitations:
(1) they fall short of providing the necessary latency and throughput performance to avoid compute tasks being blocks on exchange of intermediate data; and
(2) they provide stronger availability and durability semantics than what is needed for intermediate data.
Second, Snowflake uses its ephemeral storage system not only for intermediate data, but also as a write-through “cache” for persistent data.
Combined with a custom-designed query scheduling mechanism for disaggregated storage,
Snowflake is able to reduce the additional network load caused by compute-storage disaggregation as well as alleviate the performance overheads of reduced data locality.
本文主要从以下几点展开,中间存储,查询调度,扩展性,多租户
Snowflake system has now been active for several years and today, serves thousands of customers executing millions of queries over petabytes of data, on a daily basis.
This paper describes Snowflake system design, with a particular focus on ephemeral storage system design, query scheduling, elasticity and efficiently supporting multi-tenancy.
本文分析一个14天的查询数据集,得出以下发现,查询类型比例;查询中间结果大小差异数个量级;
很小的本地存储作为cache仍然可以取得很好命中率;良好的扩展性;Peak资源利用率高,平均利用率较低
We also use statistics collected during execution of 70 million queries over a period of 14 contiguous days in February 2018 to present a detailed study of network, compute and storage characteristics in Snowflake.
Our key findings are:
- Customers submit a wide variety of query types; for example, read-only queries, write-only queries and read-write queries, each of which contribute to 28%, 13% and 59%, respectively, of all customer queries.
- Intermediate data sizes can vary over multiple orders of magnitude across queries, with some queries exchanging hundreds of gigabytes or even terabytes of intermediate data.
The amount of intermediate data generated by a query has little or no correlation with the amount of persistent data read by the query or the execution time of the query.
- Even with a small amount of local storage capacity, skewed access distributions and temporal access patterns common in data warehouses enable reasonably high average cache hit rates (60-80% depending on the type of query) for persistent data accesses.
- Several of our customers exploit(利用)our support for elasticity (for 20% of the clusters). For cases where customers do request elastic scaling of resources, the number of compute nodes in their cluster can change by as much as two orders of magnitude during the lifetime of the cluster.
- While the peak resource utilization can be high, the average resource utilization is usually low. We observe average CPU, Memory, Network Tx and Network Rx utilizations of 51%, 19%, 11%, 32%, respectively.
提出3个未来研究的方向,计算和中间存储分离;更深的存储结构;亚秒级计费
Our study both corroborates(证实,confirm) exciting ongoing research directions in the community, as well as highlights several interesting venues for future research:
- Decoupling of compute and ephemeral storage:
Snowflake decouples compute from persistent storage to achieve elasticity.
However, currently, compute and ephemeral storage is still tightly coupled.
As we show in §4, the ratio of compute capacity and ephemeral storage capacity in our production clusters can vary by several orders of magnitude,
leading to either underutilization of CPU or thrashing(冲撞) of ephemeral storage, for ad-hoc query processing workloads.
To that end(为此), recent academic work on decoupling compute from ephemeral storage [22, 27] is of extreme interest.
However, more work is needed in ephemeral storage system design, especially in terms of providing fine-grained elasticity, multi-tenancy, and crossquery isolation (§4, §7).
- Deep storage hierarchy:
Snowflake ephemeral storage system, similar to recent work on compute-storage disaggregation [14, 15],
uses caching of frequently read persistent data to both reduce the network traffic and to improve data locality.
However, existing mechanisms for improving caching and data locality were designed for two-tier storage systems (memory as the main tier and HDD/SSD as the second tier).
As we discuss in §4, the storage hierarchy in our production clusters is getting increasingly deeper, and new mechanisms are needed that can efficiently exploit the emerging deep storage hierarchy.
- Pricing at sub-second timescales:
Snowflake achieves compute elasticity at fine-grained timescales by serving customers using a pool of pre-warmed nodes.
This was cost-efficient with cloud pricing at hourly granularity.
However, most cloud providers have recently transitioned to sub-second pricing [6], leading to new technical challenges in efficiently achieving resource elasticity and resource sharing across multiple tenants.
Resolving these challenges may require design decisions and tradeoffs that may be different from those in Snowflake’s current design (§7).
解释一波,这个系统,负载,infrastructure的泛化问题
Our study has an important caveat(注意事项).
It focuses on a specific system (Snowflake), a specific workload (SQL queries), and a specific cloud infrastructure (S3).
While our system is large-scale, has thousands of customers executing millions of queries, and runs on top of one of the most prominent infrastructures, it is nevertheless limited.
We leave it to future work an evaluation of whether our study and observations generalize to other systems, workloads and infrastructures.
However, we are hopeful that just like prior workload studies on network traffic characteristics [9 ] and cloud workloads [28 ]
(each of which also focused on a specific system implementation running a specific workload on a specific infrastructure) fueled(加油) and aided research in the past, our study and publicly released data will be useful for the community.
Design Overview
We provide an overview of Snowflake design.
Snowflake treats persistent and intermediate data differently;
we describe these in §2.1, followed by a high-level overview of Snowflake architecture (§2.2) and query execution process (§2.3).
系统设计首先考虑存储的hierarchy,Persistent,Intermediate,Meta 三层存储
Persistent and Intermediate data
Like most query execution engines and data warehousing systems, Snowflake has three forms of application state:
Persistent data is customer data stored as tables in the database.
Each table may be read by many queries, over time or even concurrently.
These tables are thus long-lived and require strong durability and availability guarantees.
Intermediate data is generated by query operators (e.g., joins) and is usually consumed by nodes participating in executing that query.
Intermediate data is thus short-lived.
Moreover, to avoid nodes being blocked on intermediate data access, low-latency high-throughput access to intermediate data is preferred over strong durability guarantees.
Indeed, in case of failures happening during the (short) lifetime of intermediate data, one can simply rerun the part of the query that produced it.
Metadata such as object catalogs, mapping from database tables to corresponding files in persistent storage, statistics, transaction logs, locks, etc.
This paper primarily focuses on persistent and intermediate data, as the volume of metadata is typically relatively small and does not introduce interesting systems challenges.
End-to-end System Architecture
Figure 1 shows the high-level architecture for Snowflake.
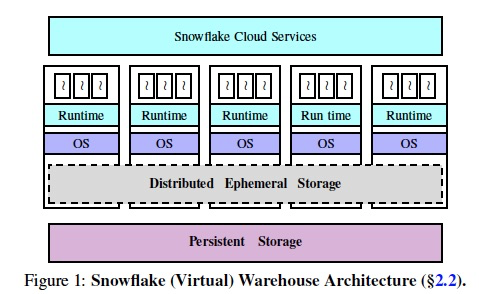
架构分四层,
服务层(管控,SQL,调度),
计算层,核心具有pre-warmed的ECS pool
中间存储层,特殊设计的分布式存储,和计算节点 co-located,增删节点无需repartition
Persistent存储层
It has four main components — a centralized service for orchestrating(编排) end-to-end query execution, a compute layer, a distributed ephemeral storage system and a persistent data store.
We describe each of these below.
Centralized Control via Cloud Services.
All Snowflake customers interact with and submit queries to a centralized layer called Cloud Services (CS) [12].
This layer is responsible for access control, query optimization and planning, scheduling, transaction management, concurrency control, etc.
CS is designed and implemented as a multi-tenant and long-lived service with sufficient replication for high availability and scalability.
Thus, failure of individual service nodes does not cause loss of state or availability, though some of the queries may fail and be re-executed transparently.
Elastic Compute via VirtualWarehouse abstraction.
Customers are given access to computational resources in Snowflake through the abstraction of a Virtual Warehouse (VW).
Each VW is essentially a set of AWS EC2 instances on top which customer queries execute in a distributed fashion.
Customers pay for compute-time based on the VW size.
Each VW can be elastically scaled on an on-demand basis upon customer request.
To support elasticity at fine-grained timescales (e.g., tens of seconds), Snowflake maintains a pool of pre-warmed EC2 instances;
upon receiving a request, we simply add/remove EC2 instances to/from that VW (in case of addition, we are able to support most requests directly from our pool of pre-warmed instances thus avoiding instance startup time).
Each VW may run multiple concurrent queries.
In fact, many of our customers run multiple VWs (e.g., one for data ingestion, and one for executing OLAP queries).
Elastic Local Ephemeral Storage.
Intermediate data has different performance requirements compared to persistent data (§2.1).
Unfortunately, existing persistent data stores do not meet these requirements
(e.g., S3 does not provide the desired low-latency and high-throughput properties needed for intermediate data to ensure minimal blocking of compute nodes);
hence, we built a distributed ephemeral storage system custom-designed to meet the requirements of intermediate data in our system.
The system is co-located with compute nodes in VWs, and is explicitly designed to automatically scale as nodes are added or removed.
We provide more details in §4 and §6 , but note here that as nodes are added and removed, our ephemeral storage system does not require data repartitioning or reshuffling (thus alleviating one of the core limitations of shared-nothing architectures).
Each VW runs its own independent distributed ephemeral storage system which is used only by queries running on that particular VW.
Elastic Remote Persistent Storage.
Snowflake stores all its persistent data in a remote, disaggregated, persistent data store.
We store persistent data in S3 despite the relatively modest(委婉的说不行) latency and throughput performance because of S3’s elasticity, high availability and durability properties. S3的优劣
S3 supports storing immutable files—files can only be overwritten in full and do not even allow append operations.
However, S3 supports read requests for parts of a file.
To store tables in S3, Snowflake partitions them horizontally into large, immutable files that are equivalent to blocks in traditional database systems [12].
Within each file, the values of each individual attribute or column are grouped together and compressed, as in PAX [2]. 文件以row group的PAX的方式组织,结构类似orc,parquet
Each file has a header that stores offset of each column within the file, enabling us to use the partial read functionality of S3 to only read columns that are needed for query execution.
All VWs belonging to the same customer have access to the same shared tables via remote persistent store, and hence do not need to physically copy data from one VW to another.
Ephemeral Storage System
重复前面说一遍,为什么需要Ephemeral Storage System
Snowflake uses a custom-designed distributed storage system for management and exchange of intermediate data, due to two limitations in existing persistent data stores [5 , 8 ].
First, they fall short of providing the necessary latency and throughput performance to avoid compute tasks being blocks on intermediate data exchange.
Second, they provide much stronger availability and durability semantics than what is needed for intermediate data.
Our ephemeral storage system allows us to overcome both these limitations.
Tasks executing query operations (e.g. , joins) on a given compute node write intermediate data locally; and, tasks consuming the intermediate data read it either locally or remotely over the network
(depending on the node where the task is scheduled, §5 ).
基本的设计选择就是,中间数据,除了放内存,还可能放SSD,或S3,原因很简单因为放不下
Storage Architecture, and Provisioning
We made two important design decisions in our ephemeral storage system.
First, rather than designing a pure in-memory storage system, we decided to use both memory and local SSDs — tasks write as much intermediate data as possible to their local memory;
when memory is full, intermediate data is spilled to local SSDs.
Our rationale(基本原理) is that while purely in-memory systems can achieve superior performance when entire data fits in memory, they are too restrictive to handle the variety of our target workloads.
Figure 3 (left) shows that there are queries that exchange hundreds of gigabytes or even terabytes of intermediate data; for such queries, it is hard to fit all intermediate data in main memory.
The second design decision was to allow intermediate data to spill into remote persistent data store in case the local SSD capacity is exhausted.
Spilling intermediate data to S3, instead of other compute nodes, is preferable for a number of reasons—
it does not require keeping track of intermediate data location, it alleviates the need for explicitly handling out-of-memory or out-of-disk errors for large queries, and overall, allows to keep our ephemeral storage system thin and highly performant.
因为无法估计查询用的资源和中间结果大小,所以很难保证突然产生大量中间结果不会用完local资源,只能放都S3。
如果要解决这问题,需要首先解耦计算层和中间结果层,独立正对query的需求进行分配,并且中间结果层要支持细粒度的扩展性。
Future Directions. For performance-critical queries, we want intermediate data to entirely fit in memory, or at least in SSDs, and not spill to S3.
This requires accurate resource provisioning(供应). However, provisioning CPU, memory and storage resources while achieving high utilization turns out to be challenging due to two reasons.
The first reason is limited number of available node instances (each providing a fixed amount of CPU, memory and storage resources), and significantly more diverse resource demands across queries.
For instance, Figure 3 (center) shows that, across queries, the ratio of compute requirements and intermediate data sizes can vary by as much as six orders of magnitude.
The available node instances simply do not provide enough options to accurately match node hardware resources with such diverse query demands.
Second, even if we could match node hardware resources with query demands, accurately provisioning memory and storage resources requires a priori(先验) knowledge of intermediate data size generated by the query.
However, our experience is that predicting the volume of intermediate data generated by a query is hard, or even impossible, for most queries.
As shown in Figure 3 , intermediate data sizes not only vary over multiple orders of magnitude across queries, but also have little or no correlation with amount of persistent data read or the expected execution time of the query.
To resolve the first challenge, we could decouple compute from ephemeral storage.
This would allow us to match available node resources with query resource demands by independently provisioning individual resources.
However, the challenge of unpredictable intermediate data sizes is harder to resolve.
For such queries, simultaneously achieving high performance and high resource utilization would require both decoupling of compute and ephemeral storage, as well as efficient techniques for fine-grained elasticity of ephemeral storage system.
We discuss the latter in more detail in §6 .
Persistent Data Caching
中间结果集生命周期很短,在peak时比较大,平均很小,所以可以和cache共用本地磁盘
机会主义的共用方式,中间结果优先
One of the key observations we made during early phases of ephemeral storage system design is that intermediate data is short-lived.
Thus, while storing intermediate data requires large memory and storage capacity at peak, the demand is low on an average.
This allows statistical multiplexing of our ephemeral storage system capacity between intermediate data and frequently accessed persistent data.
This improves performance since (1) queries in data warehouse systems exhibit highly skewed access patterns over persistent data [10 ]; and
(2) ephemeral storage system performance is significantly better than that of (existing) remote persistent data stores.
Snowflake enables statistical multiplexing of ephemeral storage system capacity between intermediate data and persistent data by “opportunistically” caching frequently accessed persistent data files,
where opportunistically refers to the fact that intermediate data storage is always prioritized over caching persistent data files.
However, a persistent data file cannot be cached on any node—Snowflake assigns input file sets for the customer to nodes using consistent hashing over persistent data file names.
A file can only be cached at the node to which it consistently hashes to; each node uses a simple LRU policy to decide caching and eviction of persistent data files.
Given the performance gap between our ephemeral storage system and remote persistent data store, such opportunistic caching of persistent data files improves the execution time for many queries in Snowflake.
Furthermore, since storage of intermediate data is always prioritized over caching of persistent data files, such an opportunistic performance improvement in query execution time can be achieved without impacting performance for intermediate data access.
文件Cache通过一致性hash被分配到某一个node上,通过直写cache来保证一致性
并且当加减节点是,使用lazy的一致性hash,来避免resuffle,搬运数据
Maintaining the right system semantics during opportunistic caching of persistent data files requires a careful design.
First, to ensure data consistency, the “view” of persistent files in ephemeral storage system must be consistent with those in remote persistent data store.
We achieve this by forcing the ephemeral storage system to act as a write-through cache for persistent data files.
Second, consistent hashing of persistent data files on nodes in a naïve way requires reshuffling of cached data when VWs are elastically scaled.
We implement a lazy consistent hashing optimization in our ephemeral storage system that avoids such data reshuffling altogether ; we describe this when we discuss Snowflake elasticity in §6 .
直写cache,所以需要多写一份local数据,每次写Persistent数据时候,需要同步更新cache
Persistent data being opportunistically cached in the ephemeral storage system means that some subset of persistent data access requests could be served by the ephemeral storage system (depending on whether or not there is a cache hit).
Figure 4 shows the persistent data I/O traffic distribution, in terms of fraction of bytes, between the ephemeral storage system and remote persistent data store.
The write-through nature of our ephemeral storage system results in amount of data written to ephemeral storage being roughly of the same magnitude
as the amount of data written to remote persistent data store (they are not always equal because of prioritizing storage of intermediate data over caching of persistent data).
cache的效果还不错,虽然local disk很小
Even though our ephemeral storage capacity is significantly lower than that of a customer’s persistent data (around 0: 1% on an average),
skewed file access distributions and temporal file access patterns common in data warehouses [7 ] enable reasonably high cache hit rates (avg. hit rate is close to 80% for read-only queries and around 60% for read-write queries).
Figure 5 shows the hit rate distributions across queries. The median hit rates are even higher.
未来的方向,
如何平衡中间结果和cache对于有限本地磁盘的占用
随着NVM或remote临时存储的诞生,存储的hierarchy会越来越深,需要新的多层cache的新架构
Future Directions. Figure 4 and Figure 5 suggest that more work is needed on caching.
In addition to locality of reference in access patterns, cache hit rate also depends on effective cache size available to the query relative to the amount of persistent data accessed by the query.
The effective cache size, in turn, depends on both the VW size and the volume of intermediate data generated by concurrently executing queries.
Our preliminary(初步的) analysis has not led to any conclusive observations on the impact of the above two factors on the observed cache hit rates, and a more fine-grained analysis is needed to understand factors that impact cache hit rates.
We highlight two additional technical problems.
First, since end-to-end query performance depends on both, cache hit rate for persistent data files and I/O throughput for intermediate data, it is important to optimize how the ephemeral storage system splits capacity between the two.
Although we currently use the simple policy of always prioritizing intermediate data, it may not be the optimal policy with respect to end-to-end performance objectives (e.g. , average query completion time across all queries from the same customer).
For example, it may be better to prioritize caching a persistent data file that is going to be accessed by many queries over intermediate data that is accessed by only one.
It would be interesting to explore extensions to known caching mechanisms that optimize for end-to-end query performance objectives [7 ] to take intermediate data into account.
Second, existing caching mechanisms were designed for two-tier storage systems (memory as the main tier and HDD/SSD as the second tier).
In Snowflake, we already have three tiers of hierarchy with compute-local memory, ephemeral storage system and remote persistent data store;
as emerging non-volatile memory devices are deployed in the cloud and as recent designs on remote ephemeral storage systems mature [22 ], the storage hierarchy in the cloud will get increasingly deeper.
Snowflake uses traditional two-tier mechanisms — each node implements a local LRU policy for evictions from local memory to local SSD, and an independent LRU policy for evictions from local SSD to remote persistent data store.
However, to efficiently exploit the deepening storage hierarchy, we need new caching mechanisms that can efficiently coordinate caching across multiple tiers.
We believe many of the above technical challenges are not specific to Snowflake, and would apply more broadly to any distributed application built on top of disaggregated storage.
Query (Task) Scheduling
We now describe the query execution process in Snowflake.
Customers submit their queries to the Cloud Services (CS) for execution on a specific VW.
CS performs query parsing, query planning and optimization, and creates a set of tasks to be scheduled on compute nodes of the VW.
Locality-aware task scheduling.
To fully exploit the ephemeral storage system, Snowflake colocates each task with persistent data files that it operates on using a locality-aware scheduling mechanism (recall, these files may be cached in ephemeral storage system).
Specifically, recall that Snowflake assigns persistent data files to compute nodes using consistent hashing over table file names.
Thus, for a fixed VW size, each persistent data file is cached on a specific node.
Snowflake schedules the task that operates on a persistent data file to the node on which its file consistently hashes to.
As a result of this scheduling scheme, query parallelism is tightly coupled with consistent hashing of files on nodes — a query is scheduled for cache locality and may be distributed across all the nodes in the VW.
For instance, consider a customer that has 1million files worth of persistent data, and is running a VW with 10 nodes.
Consider two queries, where the first query operates on 100 files, and the second query operates on 100000 files; then, with high likelihood, both queries will run on all the 10 nodes because of files being consistently hashed on to all the 10 nodes.
Work stealing. It is known that consistent hashing can lead to imbalanced partitions [19]. 很常见的做法,闲的node会steal task执行
In order to avoid overloading of nodes and improve load balance, Snowflake uses work stealing, a simple optimization that allows a node to steal a task from another node
if the expected completion time of the task (sum of execution time and waiting time) is lower at the new node.
When such work stealing occurs, the persistent data files needed to execute the task are read from remote persistent data store rather than the node at which the task was originally scheduled on.
This avoids increasing load on an already overloaded node where the task was originally scheduled (note that work stealing happens only when a node is overloaded).
调度两个极端,task和数据完全colocate,避免读persistent的数据,但中间数据会需要传输;所有task都放一起,这样避免执行中间结果传输
Future Directions. Schedulers can place tasks onto nodes using two extreme options:
one is to colocate tasks with their cached persistent data, as in our current implementation.
As discussed in the example above, this may end up scheduling all queries on all nodes in the VW;
while such a scheduling policy minimizes network traffic for reading persistent data, it may lead to increased network traffic for intermediate data exchange.
The other extreme is to place all tasks on a single node. This would obviate(消除) the need of network transfers for intermediate data exchange but would increase network traffic for persistent data reads.
Neither of these extremes may be the right choice for all queries.
It would be interesting to codesign query schedulers that would pick just the right set of nodes to obtain a sweet spot(甜区) between the two extremes, and then schedule individual tasks onto these nodes.
Resource Elasticity
In this section, we discuss how BlowFish design achieves one of its core goals: resource elasticity, that is, scaling of compute and storage resources on an on-demand basis.
Disaggregating compute from persistent storage enables Snowflake to independently scale compute and persistent storage resources.
Storage elasticity is offloaded to persistent data stores [5]; compute elasticity, on the other hand, is achieved using a pre-warmed pool of nodes that can be added/removed to/from customer VWs on an on-demand basis.
By keeping a pre-warmed pool of nodes, Snowflake is able to provide compute elasticity at the granularity of tens of seconds.
Lazy Consistent Hashing
One of the challenges that Snowflake had to resolve in order to achieve elasticity efficiently is related to data management in ephemeral storage system.
Recall that our ephemeral storage system opportunistically caches persistent data files; each file can be cached only on the node to which it consistently hashes to within the VW.
The problem is similar to sharednothing architectures: any fixed partitioning mechanism (in our case, consistent hashing) requires large amounts of data to be reshuffled upon scaling of nodes;
moreover, since the very same set of nodes are also responsible for query processing, the system observes a significant performance impact during the scaling process.
Snowflake resolves this challenge using a lazy consistent hashing mechanism, that completely avoids any reshuffling of data upon elastic scaling of nodes by exploiting the fact that a copy of cached data is stored at remote persistent data store.
Specifically, Snowflake relies on the caching mechanism to eventually “converge” to the right state.
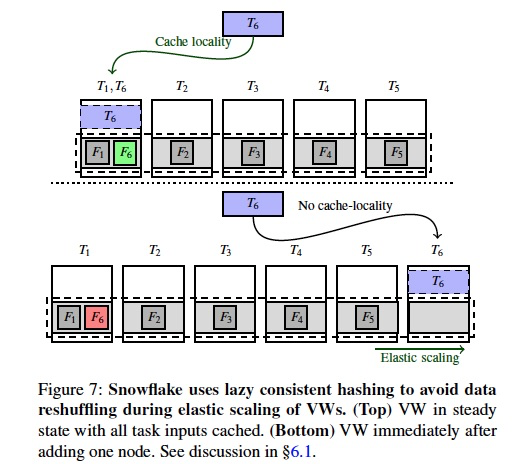
所谓Lazy就是,当增加node时,不会reshuffle cache,当下次Task6被assign到新节点是,会从remote读取file6,此时把file6 cache下来
Multi-tenancy
对于当前的方案,每个VW是使用一组独占的nodes,和ephemeral存储,这样的好处是隔离性比较好;
但是问题是资源利用率会很低,因为客户的业务高峰总是短暂的,并且是错开的,所以要资源利用率好就需要资源共享,所以这里就是隔离和利用率的tradeoff
Snowflake currently supports multi-tenancy through the VW abstraction.
Each VW operates on an isolated set of nodes, with its own ephemeral storage system.
This allows Snowflake to provide performance isolation to its customers.
In this section, we present a few system-wide characteristics for our VWs and use these to motivate an alternate sharing based architecture for Snowflake.
The VW architecture in Snowflake leads to the traditional performance isolation versus utilization tradeoff.
Figure 10 (top four) show that our VWs achieve fairly good, but not ideal, average CPU utilization; however, other resources are usually underutilized on an average.
Figure 11 provides some reasons for the low average resource utilization in Figure 10 (top four):
the figure shows the variability of resource usage across VW; specifically, we observe that for up to 30% of VW, standard deviation of CPU usage over time is as large as the mean itself.
This results in underutilization as customers tend to provision VWs to meet peak demand.
In terms of peak utilization, several of our VWs experience periods of heavy utilization, but such high-utilization periods are not necessarily synchronized across VWs.
An example of this is shown in Figure 10 (bottom two), where we see that over a period of two hours, there are several points when one VW’s utilization is high while the other VW’s utilization is simultaneously low.
While we were aware of this performance isolation versus utilization tradeoff when we designed Snowflake, recent trends are pushing us to revisit this design choice.
Specifically, maintaining a pool of pre-warmed instances was cost-efficient when infrastructure providers used to charge at an hourly granularity;
however, recent move to per-second pricing [6] by all major cloud infrastructure providers has raised interesting challenges.
From our (provider’s) perspective, we would like to exploit this finer-grained pricing model to cut down operational costs.
However doing so is not straightforward, as this trend has also led to an increase in customer-demand for finer-grained pricing.
As a result, maintaining a pre-warmed pool of nodes for elasticity is no longer cost-effective:
previously in the hourly billing model, as long as at least one customer VW used a particular node during a one hour duration, we could charge that customer for the entire duration.
However, with per-second billing, we cannot charge unused cycles on pre-warmed nodes to any particular customer.
This cost-inefficiency makes a strong case for moving to a sharing based model, where compute and ephemeral storage resources are shared across customers:
in such a model we can provide elasticity by statistically multiplexing customer demands across a shared set of resources, avoiding the need to maintain a large pool of pre-warmed nodes.
In the next subsection, we highlight several technical challenges that need to be resolved to realize such a shared architecture.
Resource Sharing
The variability in resource usage over time across VW, as shown in Figure 11, indicates that several of our customer workloads are bursty(突发的) in nature.
Hence, moving to a shared architecture would enable Snowflake to achieve better resource utilization via fine-grained statistical multiplexing.
Snowflake today exposes VW sizes to customers in abstract “T-shirt” sizes (small, large, XL etc.), each representing different resource capacities.
Customers are not aware of how these VWs are implemented (no. of nodes used, instance types, etc.).
Ideally we would like to maintain the same abstract VW interface to customers and change the underlying implementation to use shared resources instead of isolated nodes.
The challenge, however, is to achieve isolation properties close to our current architecture. 挑战是在共享的情况下仍然可以达到资源隔离属性
The key metric of interest from customers’ point of view is query performance, that is, end-to-end query completion times.
While a purely shared architecture is likely to provide good average-case performance, maintaining good performance at tail is challenging. 长尾性能很难保证
The two key resources that need to be isolated in VWs are compute and ephemeral storage.
There has been a lot of work [18, 35, 36] on compute isolation in the data center context, that Snowflake could leverage.
Moreover, the centralized task scheduler and uniform execution runtime in Snowflake make the problem easier than that of isolating compute in general purpose clusters.
Here, we instead focus on the problem of isolating memory and storage, which has only recently started to receive attention in the research community [25 ]. 由于计算资源的隔离已得到充分的讨论,重点放在内存和存储的隔离问题
The goal here is to design a shared ephemeral storage system (using both memory and SSDs) that supports fine-grained elasticity without sacrificing isolation properties across tenants.
With respect to sharing and isolation of ephemeral storage, we outline two key challenges.
First, since our ephemeral storage system multiplexes both cached persistent data and intermediate data, both of these entities need to be jointly shared while ensuring cross-tenant isolation.
While Snowflake could leverage techniques from existing literature [11 , 26 ] for sharing cache, we need a mechanism that is additionally aware of the co-existence of intermediate data.
Unfortunately, predicting the effective lifetime of cache entries is difficult.
Evicting idle cache entries from tenants and providing them to other tenants while ensuring hard isolation is not possible, as we cannot predict when a tenant will next access the cache entry.
Some past works [11 , 33 ] have used techniques like idlememory taxation to deal with this issue.
We believe there is more work to be done, both in defining more reasonable isolation guarantees and designing lifetime-aware cache sharing mechanisms that can provide such guarantees.
The second challenge is that of achieving elasticity without cross-tenant interference:
scaling up the shared ephemeral storage system capacity in order to meet the demands of a particular customer should not impact other tenants sharing the system.
For example, if we were to naïvely use Snowflake’s current ephemeral storage system, isolation properties will be trivially violated.
Since all cache entries in Snowflake are consistently hashed onto the same global address space, scaling up the ephemeral storage system capacity would end up triggering the lazy consistent hashing mechanism for all tenants.
This may result in multiple tenants seeing increased cache misses, resulting in degraded performance.
Resolving this challenge would require the ephemeral storage system to provide private address spaces to each individual tenant, and upon scaling of resources, to reorganize data only for those tenants that have been allocated additional resources.
Memory Disaggregation.
Average memory utilization in our VWs is low (Figure 10); this is particularly concerning since DRAM is expensive.
Although sharing resource sharing would improve CPU and memory utilization, it is unlikely to lead to optimal utilization across both dimensions.
Further, variability characteristics of CPU and memory are significantly different (Figure 11), indicating the need for independent scaling of these resources.
Memory disaggregation [1, 14, 15] provides a fundamental solution to this problem.
However, as discussed in §4.2, accurately provisioning resources is hard;
since over-provisioning memory is expensive, we need efficient mechanisms to share disaggregated memory across multiple tenants while providing isolation guarantees.
Related Work
In this section we discuss related work and other systems similar to Snowflake.
Our previous work [12] discusses SQLrelated aspects of Snowflake and presents related literature on those aspects.
This paper focuses on the disaggregation, ephemeral storage, caching, task scheduling, elasticity and multi-tenancy aspects of Snowflake;
in the related work discussion below, we primarily focus on these aspects.
SQL-as-a-Service systems.
There are several other systems that offer SQL functionality as a service in the cloud.
These include Amazon Redshift [16], Aurora [4], Athena [3], Google BigQuery [30] and Microsoft Azure Synapse Analytics [24].
While there are papers that describe the design and operational experience of some of these systems,
we are not aware of any prior work that undertakes a data-driven analysis of workload and system characteristics similar to ours.
Redshift [16] stores primary replicas of persistent data within compute VM clusters (S3 is only used for backup); Redshift,shared-nothing,计算存储未分离
thus, it may not be able to achieve the benefits that Snowflake achieves by decoupling compute from persistent storage.
Aurora [4] and BigQuery [30] (based on the architecture of Dremel [23]) decouple compute and persistent storage similar to Snowflake. Aurora分离了,但是依赖特殊涉及到存储服务
Aurora, however, relies on a customdesigned persistent storage service that is capable of offloading database log processing, instead of a traditional blob store.
We are not aware of any published work that describes how BigQuery handles elasticity and multi-tenancy. 未发现任何公开的资料讨论BigQuery相关的
Decoupling compute and ephemeral storage systems.
Previous work [20] makes the case for flash storage disaggregation by studying a key-value store workload from Facebook.
Our observations corroborate(证实) this argument and further extend it in the context of data warehousing workloads.
Pocket [22] and Locus [27] are ephemeral storage systems designed for serverless analytics applications.
If we were to disaggregate compute and ephemeral storage in Snowflake, such systems would be good candidates.
However, these systems do not provide fine-grained resource elasticity during the lifetime of a query.
Thus, they either have to assume a priori knowledge of intermediate data sizes (for provisioning resources at the time of submitting queries),
or suffer from performance degradation if such knowledge is not available in advance.
As discussed in §4.1, predicting intermediate data sizes is extremely hard.
It would be nice to extend these systems to provide fine-grained elasticity and cross-query isolation.
Technologies for high performance access to remote flash storage [13, 17, 21] would also be integral to efficiently realize decoupling of compute and ephemeral storage system.
Multi-tenant resource sharing.
ESX server [33] pioneered techniques for multi-tenant memory sharing in the virtual machine context, including ballooning and idle-memory taxation.
Memshare [11] considers multi-tenant sharing of cache capacity in DRAM caches in the single machine context, sharing un-reserved capacity among applications in a way that maximizes hit rate.
FairRide [26] similarly considers multi-tenant cache sharing in the distributed setting while taking into account sharing of data between tenants.
Mechanisms for sharing and isolation of cache resources similar to the ones used in these works would be important in enabling Snowflake to adopt a resource shared architecture.
As discussed previously, it would be interesting to extend these mechanisms to make them aware of the different characteristics and requirements of intermediate and persistent data.