Query Model
Query处理有三种方式,

首先是Iterator model,这是最基本的model,又称为volcano,pipeline模式
他是top-down的模式,通过next函数去逐层获取tuple
好处是比较简单,并且很容易做limit


iterator的例子,
输出一个数据,从top开始调用next,这里第二步需要join,建hashtable,需要把3的数据全部读取上来

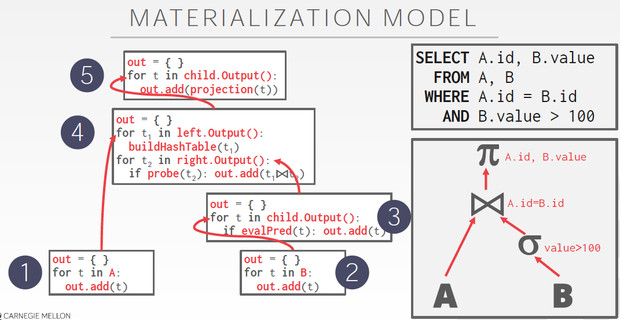
第二种方式,materialization model
反其道,这是一种bottom-up的方式,每个把数据都准备好后,往上传递
这种方式,明显适合TP,对于AP会产生大量的中间结果,
而且不好控制limit,limit1,底下节点可能也要把所有的数据都读出来


Materailization Model的例子,
多了个out,来记录返回的全量结果
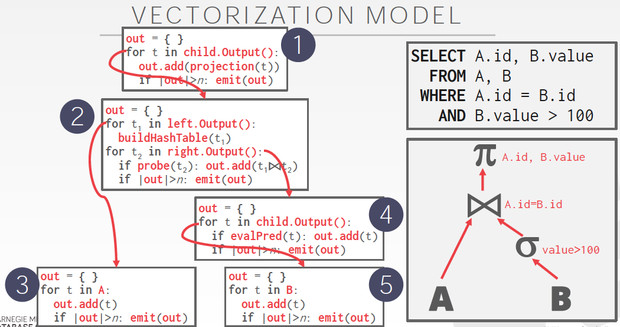
Vectorization Model
向量化模型,iterator的时候每次取一个batch,而不是一个tuple
这样大大降低next的调用频率,而且可以更好的利用SIMD进行并行处理


Vectorization Model的例子,
加上对out大小的判断以形成batch
3种模型的区别如下,

Access Methods
刚刚的查询计划里面,只是说读取数据,但是没有怎么说如何读取数据
Access Methods就是说明如何从数据库中读取数据的
Access Methods也有三种,
Sequentail Scan,Index Scan, Multi-Index/'Bitmap' Scan
Sequential Scan
顺序读,就是一个个page这么读过去,然后用一个内部的cursor去记录读到哪儿了

顺序读会比较慢,但有时是无法避免的
优化的方法如下,
预取,并行化,bypass bufferPool,都是前面说过的优化

Zone Maps
在每个page上加上一些统计信息,又称为pre-computed aggregates
这样我就可以根据这个信息来判断是否需要读这个page

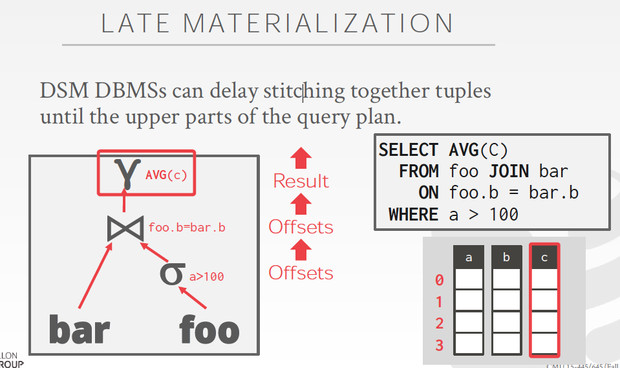
Late Materialization
这个只能用于列存,因为列存才能一次读一列,
所以在前两个过滤条件上,我们只需要把offset传上来,不需要原始数据
到最后一步,才需要把C这一列真正的materialization出来
Heap Clustering
Tuples在pages中是按照clustering index排序的,所以根据clustering index进行query是非常高效的

但是如果要按非clustered index的字段进行排序,就是比较低效的
因为tuples会分布在不同的pages中,你需要混着读
一个优化是,把所有要读的tuples按page id进行排序,然后一个个page顺序读过来会比较高效

Index Scan
关键就是如何pick合适的index来进行查询,这个比较复杂,在后面会详细描述

Multi-index Scan
同时用多个index进行索引,
然后对多个索引的结果集,进行union和intersect,最终得到结果


intersection往往通过bitmaps,hash tables,bloom filters来实现,所以有时也称为Bitmap Scan

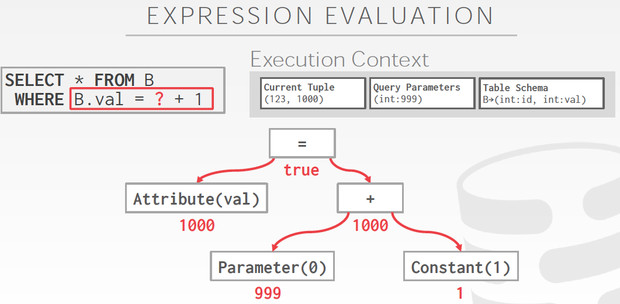
Expression Evaluation
SQL中的表达式,可以通过expression tree来表示,这种方式很灵活,但是性能比较差,所以比较高效的方式是直接codegen