1.常见数据类型、常见指令、内部数据结构以及用途?

拓展:SDS 类似于 Java 中的 ArrayList,可以通过预分配冗余空间的方式来减少内存的频繁分配。
String的实际应用场景:缓存,阅读访问量之类的计数器,限流,共享用户Session,分布式锁,全局ID,
Hash的实际应用场景:结构化的数据,比如简单的实体类对象(但前提是这个对象没嵌套其他的对象)
List的实际应用场景:文章的评论列表,文章列表或者数据分页展示,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
Set的实际应用场景:玩交集、并集、差集的操作,所以可以共同好友啥的。
Sorted set的实际应用场景:去重但可以排序,所以可以用于排行榜,按照时间、按照播放量、按照获得的赞数等,
也可以来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
2.redis过期策略?
(1)定期删除:每隔0.1s检查一次,从设置过期时间的key中,随机测试20个有过期时间的key,然后删除已过期的key,如果有25%的key被删除,则重复执行整个流程。
(2)惰性删除:尝试获取某个key时进行检查,进行删除操作。
3.redis数据淘汰策略?
no-eviction(默认):当内存不足时,新写入操作会报错,这个一般没人用
allkeys-lru(常用):尝试回收使用最少的键,数据有一部分访问频率较高,其余部分访问频率较低,或者无法预测数据的使用频率时,设置allkeys-lru是比较合适的。如不设置过期时间,高效利用内存,可以选用allkeys-lru 策略
volatile-lru:在过期集合的键中,尝试回收使用最少的键
allkeys-random:回收随机的键,如果所有数据访问概率大致相等时,可以选择allkeys-random
volatile-random:在过期的键中,回收随机的键
volatile-ttl:在过期的键中,优先回收存活时间最短的键
4.redis 持久化
4.1 概念:redis会把内存的中的数据异步的写入到硬盘中,使得数据在Redis重启之后仍然存在
4.2 实现方式:
RDB持久化:将Redis某一时刻存在的所有数据都写入硬盘,操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
save模式(同步,阻塞服务器进程,已废弃,手动触发)
过程:客户端向Redis发送save命令来创建一个快照文件,如果存在老的快照文件,新的将会替换老的。
缺点:save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求。
bgSave模式(异步,手动触发)
过程: 客户端向Redis发送bgsave命令,Redis调用fork创建一个子进程,子进程负责将快照写入硬盘,而父进程则继续处理命令请求。
缺点:bgsave在fork创建子进程时,需要增加内存服务器开销,如果内存不够,会使用虚拟内存,导致阻塞Redis运行。所以,需要保证空闲内存足够。
解决方法:可以控制单个Redis实例的最大内存,来尽可能降低Redis在fork时的事件消耗。
save m n(自动触发 )指定当m秒内发生n次变化时,会触发bgsave
AOF持久化:以日志的形式记录redis写操作,追加写入硬盘中的AOF文件
流程:所有的写命令会追加到aof-buf缓冲区,aof-buf缓冲区会向磁盘同步,当aof文件越来越大时,定期对文件rewrite重写,压缩文件,当Redis重启时,load加载aof文件即可恢复,
同步策略: always:每条Redis写命令都同步写入硬盘。优点:不丢失数据,缺点:IO开销较大。
everysec(默认 建议):每秒执行一次同步,将多个命令写入硬盘。优点:每秒一次,缺点:可能会丢1s数据。
no:由操作系统决定何时同步。优点:不用管,缺点:不可控。
文件重写:定期重写AOF文件,过期的数据,无效的命令不再写入文件,多条命令可以合并为一个,从而减小AOF文件的体积。
过程:1:执行bgrewriteaof命令后,会检查是否存在子进程重写操作。
2:没有的话,主线程会fork个子线程进行重写操作,子进程根据内存快照,按照命令合并规则写入到新的aof文件
3:主线程会继续响应其他命令,修改命令继续写入aof缓冲区,写入到旧aof文件中
4:子进程重写完成后,会通知主线程,然后主线程把写到aof重写缓冲区的数据,追加到新的aof文件中
触发方式:手动触发:bgrewriteaof命令
自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定触发时机
AOF 优点:支持秒级持久化、兼容性好,有灵活的同步策略。
缺点:恢复大文件时,恢复速度慢、对性能影响大。
RDB 优点:某个时间点上的数据快照,所以适用于备份与全量复制。
缺点:快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用, 不能实时持久化数据。兼容性不太好,老版本的Redis无法兼容新版本的RDB文件。
5.redis主从复制
工作原理:基于RDB方式的持久化实现。
作用:把redis的数据复制多个副本,部署在不同服务器上,当一台服务器出问题后,其他服务器还能提供服务。
过程:全量复制:1.从服务器连接主服务器,发送SYNC命令
2.主服务器开始执行BGSAVE命令生成RDB文件,向所有从服务器发送快照文件,并使用缓冲区记录此后执行的所有写命令
3.从服务器收到快照文件后丢弃所有旧数据,载入收到的快照
4.主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
5.从服务器执行来自主服务器缓冲区的写命令
增量复制:主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令
无硬盘复制:不需要通过RDB文件去同步,直接发送数据
策略:主从服务器刚连接时,进行全量同步,全同步结束后,再进行增量同步。
缺点:非高可用,主服务器挂断,从服务器需人为干预
6.redis哨兵机制?
作用:监控 Redis 集群中Redis系统的运行状况,当被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器.
实现原理:
定时监控任务: 每隔1秒哨兵向主从服务器+其他哨兵,发送ping命令做一次心跳检测,哨兵用来判断节点是否正常.
每隔2秒哨兵通过监控的主节点的指定频道交换信息,发送该哨兵对主节点的判断及自身哨兵信息.
每隔10秒哨兵向主从节点发送info命令,获取拓扑结构图,当哨兵判断主节点客观下线时,就会向下线的主服务器下的所有从服务器,发送info命令频率改为1秒一次.
哨兵选举: 主观下线:由一个哨兵节点判定主节点down掉是主观下线.
客观下线:多个哨兵节点交换主观判定结果,超过半数任务下线,才会判定主节点客观下线
流程: 1.如果需要从redis集群选举一个节点为主节点,首先需要从哨兵集群中选举一个哨兵节点作为Leader
2.每一个哨兵节点都可以成为Leader,当一个哨兵节点确认redis集群的主节点主观下线后,会请求其他哨兵节点要求将自己选举为Leader被请求的哨兵节点如果没有同意过其他哨兵节点的选举请求,则同意该请求
3.一个哨兵节点获得的选举票数达到Leader最低票数时,当选为leader,然后决定决定新的redis主节点
4.没有选出,则进行下一轮选举
心跳机制:从服务器默认以每秒一次的频率,向主服务器发送命令。
作用:检测主服务器的网络连接状态;辅助实现min-slaves选项;检测命令丢失。
7.redis缓存雪崩?
定义:redis缓存挂掉或集中失效,全部请求都跑去数据库.
解决方法: 1.将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机时间,这样就很难引发集体失效。
2.用加阻塞式的排它锁来实现,在缓存查询不到的情况下,每此只允许一个线程去查询DB,这样可避免同一个ID的大量并发请求都落到数据库中。
8.redis缓存穿透?
定义:大量查询redis缓存中,不存在的数据,导致查询数据库
解决方法:a:使用布隆过滤器,请求数据不合法就不让这个请求到数据库层。
布隆过滤器的使用方法,类似java的SET集合,用来判断某个元素(key)是否在某个集合中。但布隆过滤器不需存储key的值。
b:查询数据库结果为空时,将null或“” 设值给redis
jedis.set("key","60*3",Json.toString(""));//3分钟后过期


//将List数据装载入布隆过滤器中 private BloomFilter<String> bf =null; //PostConstruct注解对象创建后,自动调用本方法 @PostConstruct public void init(){ //在bean初始化完成后,实例化bloomFilter,并加载数据 List<Entity> entities= initList(); //初始化布隆过滤器 bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), entities.size()); for (Entity entity : entities) { bf.put(entity.getId()); } } //访问经过布隆过滤器,存在才可以往数据库中查询 @Cacheable(value = "province") public Provinces query(String id) { //先判断布隆过滤器中是否存在该值,值存在才允许访问缓存和数据库 if(!bf.mightContain(id)){ Log.info("非法访问"+System.currentTimeMillis()); return null; } Log.info("数据库中得到数据"+System.currentTimeMillis()); Entity entity= super.query(id); return entity; }
9.redis缓存击穿?
定义:如果某个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到数据库上,则称为缓存击穿。
区别:雪崩是很多key集体失效,击穿是一个热点key失效
解决方式:分布式锁
//核心代码
String token = UUID.randomUUID().toString(); String lock = jedis.set(key, token, "NX", "EX",20);
10.分布式锁
controller
@RestController public class LockController { private static long count = 20;//黄牛 private CountDownLatch countDownLatch = new CountDownLatch(5); @Resource(name="redisLock") // @Resource(name="mysqlLock") private Lock lock; //http://www.itzhai.com/the-introduction-and-use-of-a-countdownlatch.html @ApiOperation(value="售票") @RequestMapping(value = "/sale", method = RequestMethod.GET) public Long query() throws InterruptedException { count = 20; countDownLatch = new CountDownLatch(5); System.out.println("-------共20张票,分五个窗口开售-------"); new PlusThread().start(); new PlusThread().start(); new PlusThread().start(); new PlusThread().start(); new PlusThread().start(); return count; } // 线程类模拟一个窗口买火车票 public class PlusThread extends Thread { private int amount = 0; @Override public void run() { System.out.println(Thread.currentThread().getName() + "开始售票"); countDownLatch.countDown(); if (countDownLatch.getCount()==0){ System.out.println("----------售票结果------------------------------"); } try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } while (count > 0) { lock.lock(); try { if (count > 0) { //模拟卖票 amount++; count--; } }finally{ lock.unlock(); } try { Thread.sleep(10); } catch (Exception e) { e.printStackTrace(); } } System.out.println(Thread.currentThread().getName() + "售出"+ (amount) + "张票"); } } }
redisLock
@Service public class RedisLock implements Lock { private static final String KEY = "LOCK_KEY"; @Autowired private JedisConnectionFactory factory; private ThreadLocal<String> local = new ThreadLocal<>(); @Override //阻塞式的加锁 public void lock() { //1.尝试加锁 if(tryLock()){ return; } //2.加锁失败,当前任务休眠一段时间 try { Thread.sleep(10);//性能浪费 } catch (InterruptedException e) { e.printStackTrace(); } //3.递归调用,再次去抢锁 lock(); } @Override //阻塞式加锁,使用setNx命令返回OK的加锁成功,并生产随机值 public boolean tryLock() { //产生随机值,标识本次锁编号 String uuid = UUID.randomUUID().toString(); Jedis jedis = (Jedis) factory.getConnection().getNativeConnection(); String ret = jedis.set(KEY, uuid,"NX","PX",1000); //设值成功--抢到了锁 if("OK".equals(ret)){ local.set(uuid);//抢锁成功,把锁标识号记录入本线程--- Threadlocal return true; } //key值里面有了,我的uuid未能设入进去,抢锁失败 return false; } //错误解锁方式 public void unlockWrong() { //获取redis的原始连接 Jedis jedis = (Jedis) factory.getConnection().getNativeConnection(); String uuid = jedis.get(KEY);//现在锁还是自己的 //uuid与我的相等,证明这是我当初加上的锁 if (null != uuid && uuid.equals(local.get())){//现在锁还是自己的 //锁失效了 删锁 jedis.del(KEY); } } //正确解锁方式 public void unlock() { //读取lua脚本 String script = FileUtils.getScript("unlock.lua"); //获取redis的原始连接 Jedis jedis = (Jedis) factory.getConnection().getNativeConnection(); //通过原始连接连接redis执行lua脚本 jedis.eval(script, Arrays.asList(KEY), Arrays.asList(local.get())); } //----------------------------------------------- }
unlock.lua
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
11.redis挂了怎么办?
redis挂掉 事发前:实现redis高可用(主从架构+sentine哨兵 或者Redis cluster),避免redis挂掉.
事发时:设置本地缓存(ehcache)+限流(hystrix)
事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据
12.Redis 单线程为什么还能这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。
正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
拓展:生产禁用keys,但可使用SCAN cursor [MATCH pattern] [COUNT count]示例: scan cursor match *91300 count 100 模糊查询91300工号的100条数据
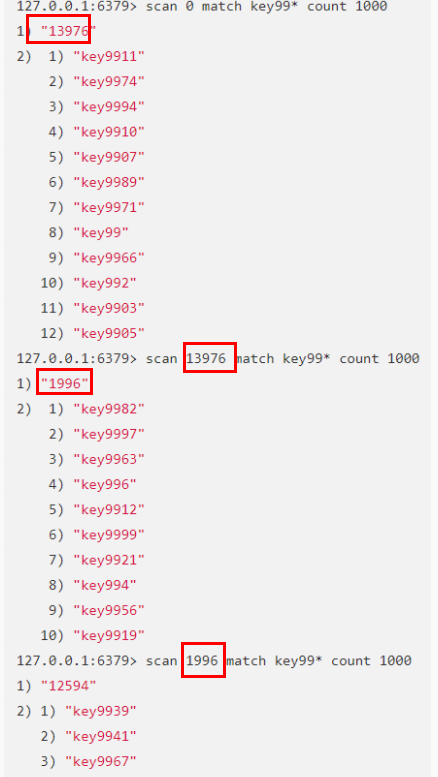
13.Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到
文件事件分派器,事件分派器将事件分发给事件处理器。
Nginx也是采用IO多路复用原理解决C10K问题