1.Covariate Shift
当训练集的样本分布和测试集的样本分布不一致的时候,训练集训练得到的模型 不好繁华至测试集,这就是Covariate Shift问题。
需要根据目标样本的分支和训练样本的分布 的比例( P(x)/Q(x) ) 对训练样本做一个矫正。参考1 2
2.BN
深度网络中,随着网络深度的加深,每一层的输入逐渐向非线性激活函数的两端移动,造成梯度消失现象,训练速度慢。
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布。
但是拉回来之后,相当于每一层就是在线性变化,深度就没有用了,造成网络的表达能力下降。为了在表达能力和训练速度之前平衡,
BN对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift)。
参考3 非常详细的BN解释。
参考文献:
1.https://blog.csdn.net/coolluyu/article/details/20280795
2.https://blog.csdn.net/guoyuhaoaaa/article/details/80236500
3.https://www.cnblogs.com/guoyaohua/p/8724433.html
- 为什么要normalization
- 机器学习中,有一个前提的假设:数据独立同分布。在把数据喂给模型之前,往往需要进行白化操作
- 深度学习中的Internal Coveriate Shift问题
- 深度学习涉及很多层的叠加,每一层的参数更新会导致上一层的输入参数发生变化,越往高层变化越剧烈。这就使得高层需要不断去适应低层的参数更新。这样学习率、初始化、参数更新策略都不好弄
- 把不同的层看为源空间和目标空间,机器学习中希望源空间和目标空间的分布一致,但多层网络的相当于是边缘分布不一致,条件分布一致
- 导致的问题:
- 上层参数需要不断适应新的数据分布,降低学习速度
- 下层输入的变化可能趋向于变大或变小,导致落入梯度的饱和区,使得学习提早停止
- 每层的参数更新都会影响到其他层,因此参数更新要尽可能的小心
- normalization的通用框架与基本思想
- 神经元所做的工作简单边可以描述为y=f(x),normalization主要是做了平移和伸缩变换。可以归纳为
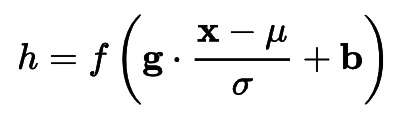 ,先做了一个标准化操作,然后再做一个平移和缩放操作
,先做了一个标准化操作,然后再做一个平移和缩放操作 - 标准化后不就好了,为什么要再做一个平移和缩放操作呢?
- 尊重底层的学习结果:再平移和再缩放的参数都是可以学习的,尊总底层的学习结果
- 不降低模型的表达能力 :保证获得非线性的表达能力。比如sigmoid,如果只做第一步,那么绝大多数输入都落在了线性区,降低了模型的表达能力。而进行第二步就可以恢复模型的表达能力了
- 变来变去会不会相当于没变呢:不会。新参数是可以通过网络来学习的。x的均值,之前是下层的复杂结构决定的,现在直接平移参数有关,很容易通过梯度下降来学习,简化网络的训练
- 神经元所做的工作简单边可以描述为y=f(x),normalization主要是做了平移和伸缩变换。可以归纳为
- 主流normalization方法
- Batch Normalization
- mini btach对单个神经元进行:mini batch的均值和方差作为标准化的参数
- 特点:
- 希望mini batch之间或者同整体分布之间是同分布的,就需要每个mini batch比较大,分布比较接近,在训练之前要进行充分的shuffle操作
- 不使用与动态的网络结构和RNN结构
- Layer Normalization
- 对单个样本,一层的所有神经元的输入做标准化平移缩放操作
- 特点:
- 对单个样本操作,避免了BN中mini batch样本分布不一致的问题
- 可用于动态网络和RNN
- 不需要保存中间的均值和方差,节约存储空间
- 一层的不同神经元经过平移和缩放后映射到了同一个空间,如果特殊类别本身差别较大,比如颜色和大小,可能降低模型的表达能力
- weight Normalization
- BN和 LN都是对输入数据进行Normalization,而weight Normalization是对圈中W进行normalization
- BN和LN都是用输入特征数据的方差和均值,对数据进行scale,而WN是用神经元圈重的欧式范数对输入数据进行scale。都是作用在输入数据上,只是拿来作用的源头不同。
- WN对应标准公式中只有scale操作而没有平移操作(可以用BN或LN的方式来计算均值miu)
- WN的规范化不直接使用输入数据的统计量,避免了BN过分依赖mini batch的不足和LN每一层统一转换的限制
- Cosine Normalization
- BN和LN对输入数据变换,一个纵向,一个横向
- WN对模型参数进行变换
- CN另辟蹊径,变换了线性变换的公式,由求点积转化为求余弦相似度。出发点是数据分布的变化,方差变大的一个原因就是点积操作是可能变得很大,而余弦操作自动限定到-1,1的范围。
- CN和WN还比较相似,一定程度理解为,WN用模型参数的权重W的模进行scale,而CN在词基础上,又用输入向量的模进行了scale
- 本来內积的意义是输入向量在权重向量上的投影,包含夹角信息和模信息,去掉scale信息后,可能模型的表达能力下降
- Batch Normalization
- normalization为什么有效
- 权重伸缩不变性:
- W的权重进行伸缩变换,得到的规范化后的值保持不变。因为W伸缩变换时,规范化的分支分母都进行相应变化,可以约去。
- 权重伸缩不变性可以有效的提高反向传播的效率:
- 权重伸缩变换不会影响反向梯度的jacobian矩阵,也就对反向梯度没有影响。避免了反向传播出现梯度消失或梯度弥散问题,加速网络训练。
- 权重伸缩不变性还具有参数正则化的效果,可以使用更高的学习率。权重值越大,其梯度就越小,参数变化也就越稳定,相当于实现了正则化的效果,避免参数大幅震荡。
- 数据伸缩不变性:
- 输入数据按照lambda进行伸缩变化时,得到的规范化后的值保持不变。对BN LN CN成立。
- 数据伸缩不变性可以有效的减小梯度弥散,简化学习率的选择
- 权重伸缩不变性: