1.词编码需要满足的几个条件:
保证词的相似性
向量空间分布的相似性
向量空间子结构(男人女人 国王女王)
2.计算机中表示一个词:
字典表示的话:不能分辨细节差异,需要大量认为劳动,主观,无法发现新词,很难精确凭借词之间的相似度
离散表示:one hot encoding (bag of words | set of words)
词权重也可以用TF-IDF计算出来。
但是使用这种方式表示的缺点是不能描述词语之间的关系,所以这里就会设计语言模型。N-gram model
3.N-gram

但是会带来 词表急剧扩张,sparse的问题。
语言模型:

4.离散表示的缺点:

5.分布式表示(Distributed representation)

接下来核心来了 nlp总最有创建的想法之一:用一个词附近的词来表示该词
那么怎么描述词附近的词呢?共现矩阵
6.共现矩阵

如果将共现矩阵的行列向量当做他的向量表示,容易带来的问题:

可以使用SVD降维,但是对于n * n的矩阵,使用svd降维的话,复杂度为n*3,所以计算量太大。

7.NNLM(Neural Network Language Model)
未完待续...
http://blog.csdn.net/itplus/article/details/37969817
神经概率语言模型,主要包括四个层:输入层,投影层,隐藏层,输出层
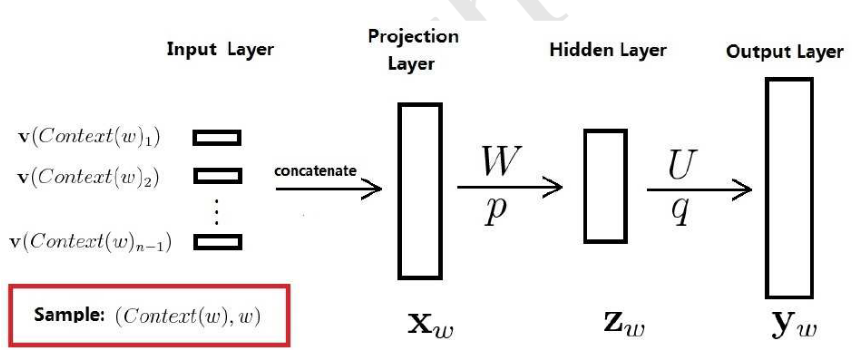
假如词典中有10000个词,取w的前边 n- 1个词来进行训练的话,那么输入层就是n - 1 个one-hot表示的行向量。
通过投影矩阵进行线性映射,就得到n-1个m维度的稠密向量。把这些稠密详细首位相接拼接在一起就得到一个(n - 1) * m的向量Xw.
接下来进入隐藏层,使用双曲正切函数作为隐藏层的激活函数:

计算后得到一个10000维的向量,若想要其分量表示概率,用softmax做归一化。就得到:

回过头来看看theta的参数有哪些


8.word2vec
8.1 知识补充Huffman Tree http://blog.csdn.net/itplus/article/details/37969635
word2vec中将会用到Huffman编码,它把训练语料中的词当做叶子节点,其在语料中出现的次数当做叶子节点的权值,
通过构造的huffman树(带权路径长度)对每一个词进行Huffman编码。
8.2 详细介绍参考博客http://blog.csdn.net/itplus/article/details/37969979
可以细分为CBOW和Skip-gram
CBOW是使用w的context去预测w,skip是使用w去预测context的上下文。
又可以分为基于Hierarchical softmax的模型和基于negative sampling的模型。
8.3 CBOW
三层:输入层,映射层,输出层
输入层:context的词的词向量
投影层:输入层的词向量的求和
输出层:Huffman树
对于词典中的词w,必存在一条由根节点到w的路径,路径上每遇到一个非叶节点,就对应一次二分类的过程,就会有一个概率值,
路径上的所有概率在相乘就会得到一个当前的P(w | context(w)).然后对于词典中的每一个词,都会有一个概率,就可以表示出似然函数,
也就可以表示出损失函数,然后采用SGD求解即可。