这个项目就九章算法大数据课程的一个项目。主要分为两步:
第一步是 offline 建立 数据库 我们用两个map reduce 的data pipline 来实现。
第二步是 online显示把数据里面数据读出来显示。
如果实际运用中 第一步 mapreduce 一般数据一天之内更新不会太多 所以mapredcue 一天跑一次。
第二步 online 显示 like 数据大了会比较慢 。 然后可以优化系统版讲的trie树就是其中一种。
Map-Reduce 实现搜索自动补全。这项功能可以用在搜索的自动补全和拼写纠错。
search auto complete是基于N-Gram model实现的,下面首先介绍N-Gram model
一、模型基础
-
N-Gram model
N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。
关于N-Gram的一个介绍,参见博客 http://blog.csdn.net/baimafujinji/article/details/51281816
简单来说,N-Gram是一个句子的长度为n的连续子序列
例如:
I love big data
4-gram i love big data
3-gram l love big, love big data
2-gram l love, love big, big data
-
language model
A statistical language model is a probability distribution over sequences of words. Given such a sequence, say of length m, it assigns a probability 
to the whole sequence. https://en.wikipedia.org/wiki/Language_model
简单来说就是根据已有的数据集,不同的字符串序列在这个数据集上有一个概率分布,据此可以得到一个字符串序列出现的概率大小。
本文所述的就是N-gram model.一句前边出现的字符串序列去预测后边出现某字符串的概率大小。
这里又Predict N-Gram based on N-Gram 和 Predict N-Gram based on 1-Gram,当然第一种方式要准确得多,但是也相对更复杂。
所以本文采用首先基于1-Gram预测N-Gram,然后再数据库上做文章,实现基于N-Gram预测N-Gram。
二、系统框架
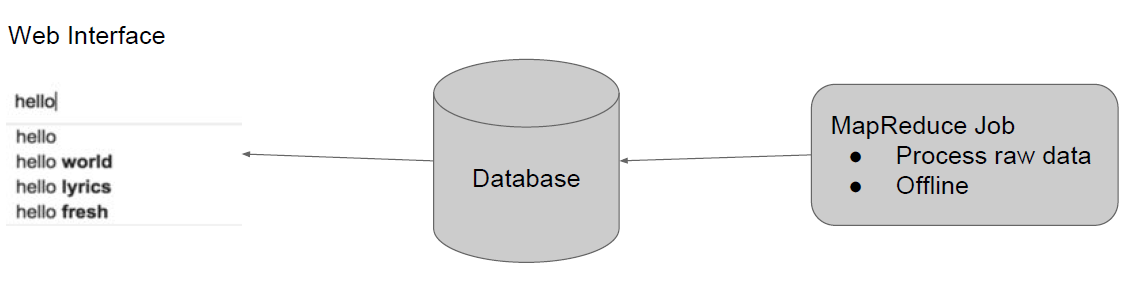
图1
基本架构如图一所示,主要分为三个模块:
Web接口模块:基于LAMP实现的一个简单的测试接口(LAMP集成了Apache, Php, Mysql)
数据库模块:存放我们建立好了的1-Gram model
Map-Reduce模块:离线处理我们的训练数据。
三、具体步骤

图2
如图2所示,具体步骤如下:
- 读取文件数据
- 建立N-Gram library
- 计算概率获得language model
- web接口展示
3.1读取文件数据
按句子读入数据,预处理删除所有的非字母字符
3.2建立N-Gram library

使用Map-Reduce实现。
- Mapper
划分句子,取出1-gram,...,N-gram
- Reducer
统计各个phrase出现的次数。
3.3计算概率获得language model
基于概率计算公式:

来计算概率。但是考虑到我们的目的是得到phrase之后应该取哪一个word,分母都一样,所以就省去除以分母这一步骤。
这样,我们对于一个N-Gram:提取Starting word/phrase为key,最后一个字符串为value。然后对同一个key,选取value最大的几个value存入数据库。
最后,我们获得了一个最后的数据库,但是回过头来分析,我们得到的只是基于一个单词去预测的模型,所以这里在数据库中选择数据的时候做了一个小操作,下文详述。
- Mapper

由于一些出现次数特别少的字符串,我们并不希望它们出现在结果中,所以在Mapper阶段需要设定易于阈值,只有出现次数大于这个阈值的时候,才让它进入Reducer。
- Reducer
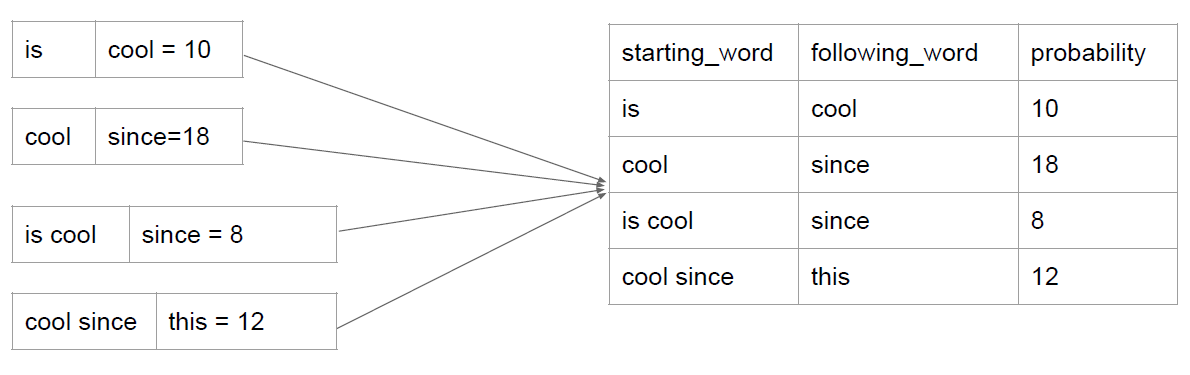
我们并不需要存储所有数据进入数据库,存储的大小和我们设定的需要提示的数量是有关系的,假如我们需要自动补全的提示框有k条,那么我们是需要选择出TopK存储进入数据库就可以了。
最后得到的数据库中存储结果如下图所示:

呼应之前提到的,我们现在得到的只是基于1-gram的预测,怎么得到N-Gram呢?在从数据库中提取数据的时候,我们选择这样操作:

这样就可以由N-Gram预测N-Gram。
这里之前也有一个疑惑,既然这样操作的话,那么你前边还把language model的Mapper的拆分还有什么必要?
这里是必要的,举个例子:
a man 264
a little 90
a great 83
a apple 50
a beautiful girl 45
a wonderful game 40
假如我们不进行拆分的话,那么意思就是找TopK的时候就按照‘a’打头的分组来找TopK。那么一般2-Gram的都会比较大,直接就选择了 a man 264、a little 90、a great 83 、a apple 50。后边的都没有机会进去,但实际分析我们希望的是a beautiful girl 45、a wonderful game 40能够入选。