1:获取dataFrame的行数和列数
行数:dataframe.shape[0]或len(DataFrame.index)
列数:dataframe.shape[1]或len(DataFrame.columns)
2:创建DataFrame的几种方式:
self:DataFrame, data=None, index=None, columns=None, dtype=None, copy=False
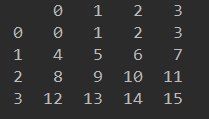
1.通过NumPy的接口来创建一个4x4的矩阵,以此来创建一个DataFrame
df = pd.DataFrame(np.arange(16).reshape(4, 4)) # 默认的索引和列名都是[0, N-1]的形式
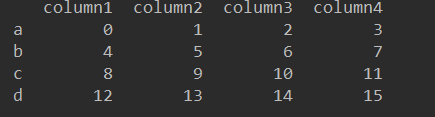
# 在创建DataFrame的时候指定列名和索引 df = pd.DataFrame(np.arange(16).reshape(4, 4), columns=["column1", "column2", "column3", "column4"], index=["a", "b", "c", "d"])
输出结果分别如下:
2.直接指定列数据来创建DataFrame
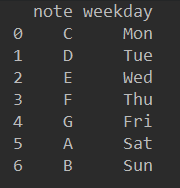
df = pd.DataFrame({"note": ["C", "D", "E", "F", "G", "A", "B"], "weekday": ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]})
输出结果如下:
3.以Series数组来创建DataFrame。注意!!!每个Series将成为一行,而不是一列!!!
noteSeries = pd.Series(["C", "D", "E", "F", "G", "A", "B"], index=[1, 2, 3, 4, 5, 6, 7]) weekdaySeries = pd.Series(["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"], index=[1, 2, 3, 4, 5, 6, 7]) df = pd.DataFrame([noteSeries, weekdaySeries])
输出结果如下:

3:DataFrame提供了下面两个操作符来访问其中的数据:
loc: 通过行和列的索引来访问数据iloc:通过行和列的下标来访问数据
补充:使用head查看前几行数据(默认是前5行),使用tail查看后几行数据(默认是后5行)
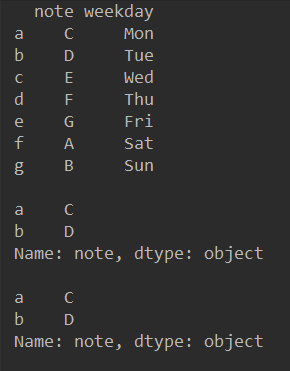
df = pd.DataFrame({"note": ["C", "D", "E", "F", "G", "A", "B"],
"weekday": ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]},
index=["a", "b", "c", "d", "e", "f", "g"])
# df.index = ["a", "b", "c", "d", "e", "f", "g"] 也可以通过此方式设置index
print(df, '
')
print(df.loc[['a', 'b'], "note"], '
') # 访问了行索引为a和b,列索引为“note”的元素
print(df.iloc[[0, 1], 0]) # 访问了行下标为0和1,列下标为0的元素
输出结果如下:
4:dataframe astype 字段类型转换
# -*- coding: UTF-8 -*- import pandas as pd df = pd.DataFrame([{'col1': 'a', 'col2': '1'}, {'col1': 'b', 'col2': '2'}]) print(df) print(df.dtypes) print('-----------') df['col2'] = df['col2'].astype('int') print(df.dtypes) print('-----------') df['col2'] = df['col2'].astype('float64') print(df.dtypes)
输出结果如下:

5:dataFrame转化为矩阵
# -*- encoding:utf-8 -*- import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), columns=list('abcd')) print(df) data = df.values print(data, type(data), ' ') data = df.as_matrix(columns=['a', 'b']) # 若columns=None或者省略columns参数,则默认把dataframe的所有列转化为矩阵 print(data, type(data))
6:dataframe 按列或者按行合并
concat 与其说是连接,更准确的说是拼接。即把两个表直接合在一起。于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis 。
函数的具体参数是:
concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False)
objs 是需要拼接的对象集合,一般为列表或者字典
axis=0 是行拼接,拼接之后行数增加,列数也根据join来定,join='outer'时,列数是两表并集。同理join='inner',列数是两表交集。
在默认情况下,axis=0为纵向拼接,此时有
concat([df1,df2]) 等价于 df1.append(df2)
在axis=1 时为横向拼接 ,此时有
concat([df1,df2],axis=1) 等价于 merge(df1,df2,left_index=True,right_index=True,how='outer')
例如:
import pandas as pd import numpy as np df1 = pd.DataFrame(np.arange(16).reshape(4, 4)) print(df1) df2 = pd.DataFrame(np.arange(12).reshape(4, 3)) print(df2) data = pd.concat([df1, df2], axis=1) print(data)
输出结果如下: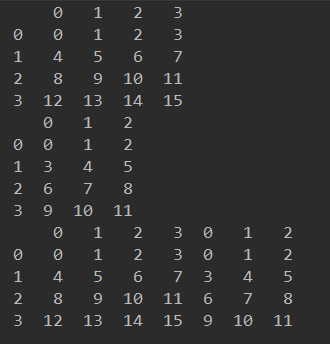
7:DataFrame切片操作
DataFrame数据框允许我们使用iloc方法来像操作array(数组)一样对DataFrame进行切片操作,其形式上,跟对数组进行切片是一样的。
1、创建一个6行4列的DataFrame数据框
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(6, 4), columns=list("ABCD")) print(df)

2、使用iloc方法,提取数据:
df.iloc[3] # 提取第四行数据
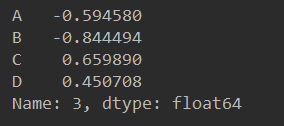
df.iloc[[1, 2, 4], [0, 2]] # 提取第2、3、5,第1、3列的数据
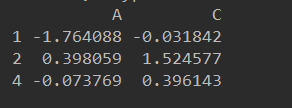
df.iloc[1:3, :] # 保证所有列都在,可以使用一个冒号来表示所有列(行也适用)

iat是专门提取某个数的方法,它的效率高更高,因此建议在提取单个数的时候用iat
df.iat[1, 1]
