Hadoop集群安装配置教程_Hadoop3.1.3_Ubuntu
http://dblab.xmu.edu.cn/blog/2544-2/
林子雨编著《大数据技术原理与应用(第3版)》教材配套大数据软件安装和编程实践指南
http://dblab.xmu.edu.cn/post/13741/
hadoop hbase hive spark对应版本
hbase与phoenix整合(使用phoenix操作hbase数据)
http://blog.itpub.net/25854343/viewspace-2638600/
hbase时间不同步问题引起的bug
https://www.cnblogs.com/parent-absent-son/p/10096064.html
HBase启动后RegionServer自动挂原因及解决办法【ntp】
https://blog.csdn.net/csq031231/article/details/51011076
关闭Hbase出现stopping hbasecat:/tmp/hbase-root-master.pid:No such file or directory
https://blog.csdn.net/sinat_23225111/article/details/82695008
解决方式是在hbase-env.sh中修改pid文件的存放路径,配置项如下所示: # The directory where pid files are stored. /tmp by default. export HBASE_PID_DIR=/var/hadoop/pids
saveasnewapihadoopdatast 保存数据到hbase报空指针异常什么情况 python语言开发的
https://bbs.csdn.net/topics/392392966
conf = SparkConf().setMaster("local").setAppName("ReadHBase").set("spark.hadoop.validateOutputSpecs", False)
Linux重要命之sed命令详解
https://www.linuxprobe.com/detailed-description-of-sed.html
Linux sed命令完全攻略(超级详细)
http://c.biancheng.net/view/4028.html
Linux sed 命令
https://www.runoob.com/linux/linux-comm-sed.html
Sed命令中含有转义字符的解决方法
https://www.cnblogs.com/zwldyt/p/12996846.html
linux sed命令删除特殊字符(含斜线、冒号等转义字符)
https://blog.csdn.net/xhoufei2010/article/details/53521625/
CentOS 查看系统 CPU 个数、核心数、线程数
https://www.cnblogs.com/heqiuyong/p/11144652.html
Linux机器之间免密登录设置
https://blog.csdn.net/u013415591/article/details/81943189
Shell脚本实现SSH免密登录及批量配置管理
https://www.cnblogs.com/30go/p/11458457.html
WARN: Establishing SSL connection without server's
https://blog.csdn.net/a458383896/article/details/86519220
大数据hive之hive连接mysql并启动,出现SSL警告,如何解决?
https://blog.csdn.net/baidu_34122324/article/details/84975839
分布式集群一键部署稳定版了解一下
mysql与hive2.1.1安装和配置
https://www.cnblogs.com/K-artorias/p/7141479.html
hive建表出错:Specified key was too long; max key length is 767 bytes
https://blog.csdn.net/qq_42826453/article/details/86182070
XML转义特殊字符
https://www.cnblogs.com/masonlu/p/9816418.html
< < 小于号
> > 大于号
& & 和
' ' 单引号
" " 双引号
空格
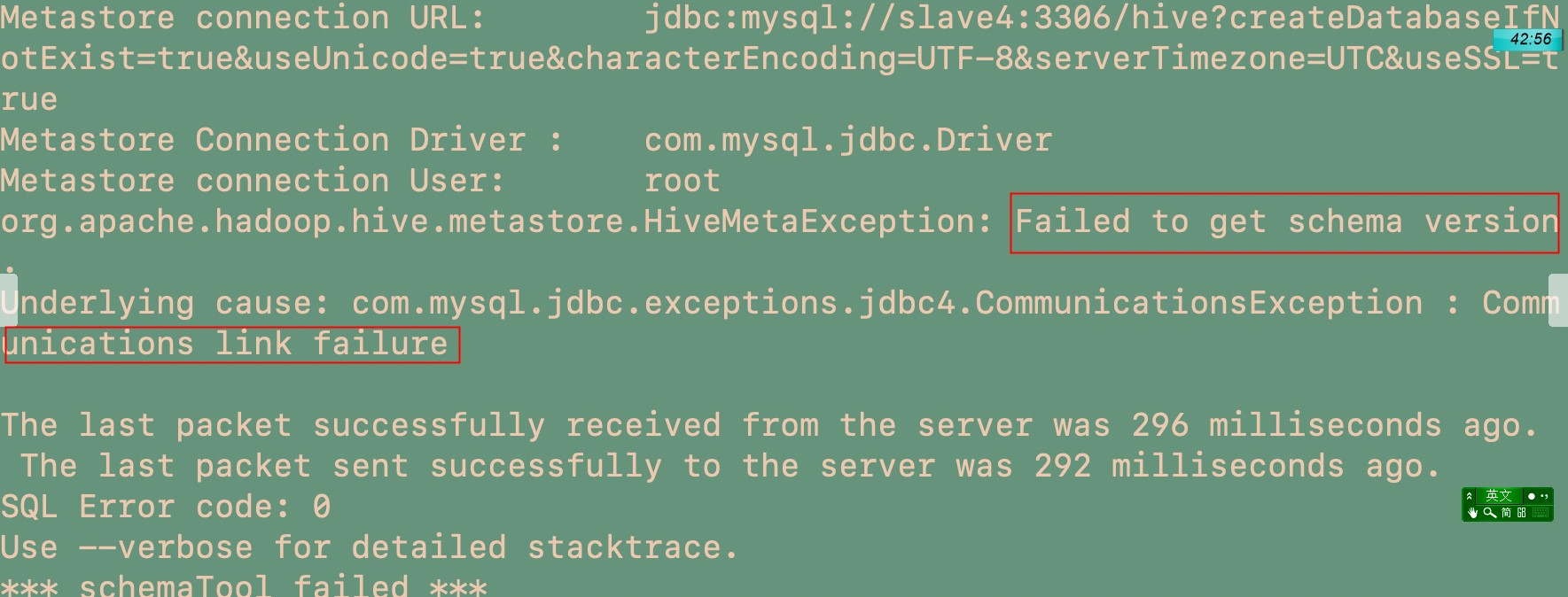
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeExcepti
https://blog.csdn.net/qq_35078688/article/details/86137440

若不配置characterEncoding=UTF-8,则在hive中会出现中文乱码,若mysql开启了ssl验证,(高版本mysql默认开启)但是my.cnf里没有配置秘钥,则会出现以下通信错误。
MySQL开启SSL认证,以及简单优化
https://www.cnblogs.com/so-cool/p/9239385.html
MySQL8中的SSL连接的关闭
https://jingyan.baidu.com/article/5552ef470a1522118ffbc9ef.html
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeExcepti
https://blog.csdn.net/qq_35078688/article/details/86137440
hive的服务端没有打开 hive --service metastore & 然后Ctrl+C 再hive,进去
大数据hive之hive连接mysql并启动,出现SSL警告,如何解决?
https://blog.csdn.net/baidu_34122324/article/details/84975839
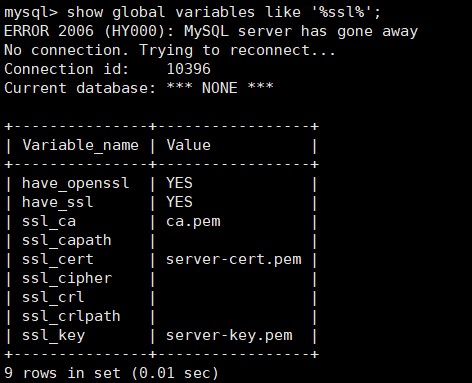
首先查看mysql ssl是否开启
show global variables like '%ssl%';

启动Hive报错:mysql://localhost:3306/hive?createDatabaseIfNotExist=true, username = root. Terminating con
https://blog.csdn.net/weixin_43968936/article/details/102872636
hive安装配置过程中还需要注意的一些问题:
–>hive 2.0以上版本,安装配置完成之后需要先初始化元数据库
执行: schematool -dbType mysql -initSchema
–>比如一定要把这个mysql-connector-java-5.1.40-bin.jar包放在hive安装目录的lib下,不能是包含这个这个包的压缩包等。
–>Exception in thread “main” java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient 这个错误应该就是没有正确的将jar包放在Lib目录下。
–>启动hive过程中还遇到过,报这个警告,但是可以启动, Sat Nov 02 15:42:13 CST 2019 WARN: Establishing SSL connection without server’s identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn’t set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to ‘false’. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
有说在hive配置文件中的mysql连接url中加一个参数的,
因为原因是MySQL在高版本需要指明是否进行SSL连接。
解决方案如下: 在mysql中查看有没有开启ssl
mysql> show global variables like ‘%ssl%’;
如果是have_ssl 对应disabled,
那就在hive配置文件conf/hive-site.xml中的mysql连接url中添加参数useSSL=false
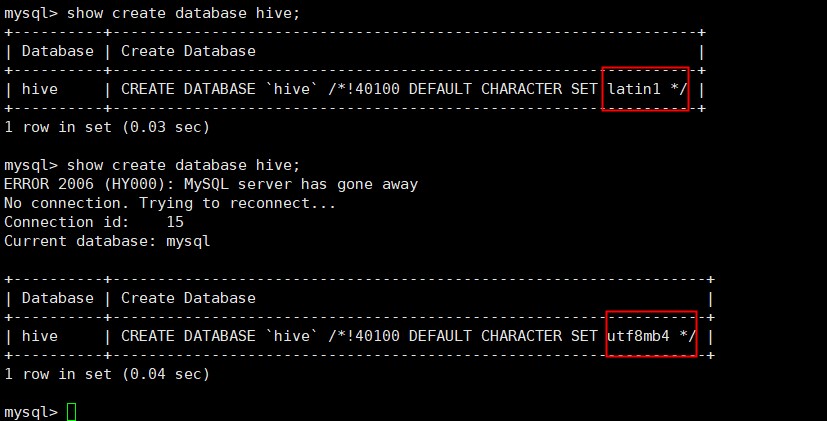
hive配置MySQL时的乱码解决方案
https://blog.csdn.net/weixin_43087634/article/details/85218017
show variables like 'char%';
Hive之metastore服务启动错误解决方案org.apache.thrift.transport.TTransportException: Could not create ServerSock
https://www.pianshen.com/article/1984355270/
https://blog.csdn.net/weixin_45568892/article/details/105451958
错误org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9083.
metastore重复启动
netstat -apn|grep 9083
执行查看linux端口命令,发现9083 端口被占用
kill进程后重新启动即可解决问题 先jps查看进程
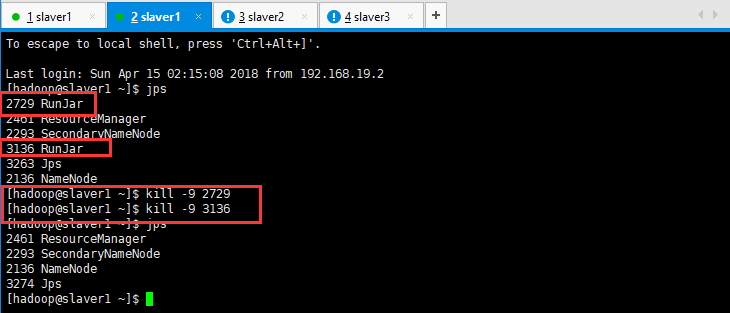
重启hive metastore服务
hive --service metastore &
Hive-异常处理Hive Schema version 2.3.0 does not match metastore's schema version 1.2.0 Metastore is not
https://blog.csdn.net/u014804456/article/details/77747720?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.control
https://github.com/apache/hive/blob/master/metastore/scripts/upgrade/mssql/upgrade-2.2.0-to-2.3.0.mssql.sql
MetaException(message:Hive Schema version 2.3.0 does not match metastore's schema version 1.2.0
https://blog.csdn.net/qq_39579408/article/details/86526757
https://blog.csdn.net/struggling_rong/article/details/82598277
SBT命令行打包spark程序
https://zhuanlan.zhihu.com/p/65572399
下载安装配置 Spark-2.4.5 以及 sbt1.3.8 打包程序
https://blog.csdn.net/qq_21516633/article/details/105077947
安装最新版sbt工具方法和体会
http://dblab.xmu.edu.cn/blog/2546-2/#more-2546
Sbt——安装、配置、详细使用
https://blog.csdn.net/blueicex2017/article/details/104275168
scala的jar包在spark,scala,java上的执行
https://zhuanlan.zhihu.com/p/87355394
spark的动态资源配置
https://blog.csdn.net/yang735136055/article/details/100061133
Hadoop _ 疑难杂症 解决1 - WARN util.NativeCodeLoader: Unable to load native-hadoop library for your plat
https://blog.csdn.net/u010003835/article/details/81127984?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromBaidu-1.control
hadoop 2.x安装:不能加载本地库 - java.library.path错误
https://www.cnblogs.com/erygreat/p/7223784.html
解决Hadoop启动时,没有启动datanode
http://dblab.xmu.edu.cn/blog/818-2/
关于Spark报错不能连接到Server的解决办法(Failed to connect to master master_hostname:7077)
https://blog.csdn.net/ybdesire/article/details/70666544
Spark启动的时候出现failed to launch: nice -n 0 /soft/spark/bin/spark-class org.apache.spark.deploy.worker
https://blog.csdn.net/qq_40707033/article/details/93210838
大部分人说需要在root用户下的.bashrc配置JAVA_HOME,试过之后发现还是原来的错误;
最后发现需要在/spark/sbin/spark-config.sh 加入JAVA_HOME的路径。
还有一个错误非常隐蔽,环境变量报错,可能是在/etc/profile.d目录下配置了环境变量。
Linux系统重启后/etc/hosts自动添加主机名解析
https://support.huaweicloud.com/intl/zh-cn/trouble-ecs/ecs_trouble_0320.html
https://blog.csdn.net/weixin_44706512/article/details/107332447
kafka启动方式
https://blog.csdn.net/m0_37690430/article/details/85098440
在Windows中 启动Kafka出现The Cluster ID doesn't match stored clusterId错误
https://www.jianshu.com/p/d51ef3369b37