本次所以的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
前言
在二手房网找房时,房屋物理信息(指房屋本身的信息,例如户型、朝向、面积、装修等固定的属性。)、附属信息、价格信息、周边情况信息,哪一个才是年轻人关注的重点呢?
这次的租房房源数据来源于方天下(https://sh.esf.fang.com/house/i310/),用 Python 收集数据后制作成可视化图形。
一、数据获取
1.网站代码分析:
首先这个网站有登陆功能,登录网站,看看登录前后前后是否有区别, 发现并无区别,爬虫时可以无需模拟登陆:
需要爬虫的数据为红色方框部分,对应的内容和代码:


2.代理IP
在爬取数据100条以后,网站需要验证码才可以登陆进去,此时可以考虑使用代理ip进行爬取,因为免费ip少之又少,并且时效性较短,用起来不太方便,本人用了班里同学爬取整个代理网站的ip并筛选好的代理ip使用,详情可见链接:。
测试代理ip失效(txt格式保存到代码路径下)如下:

3.设置时间间隔
爬取时间过快也会导致被封ip风险性增加,设置一下时间间隔,代码如下:
1 # 为了降低被封ip的风险,设置合理的爬取间隔,每爬20页便随机歇1~5秒。 2 if page%20 == 0: 3 time.sleep(random.random()*5)
二、数据爬取
1 from bs4 import BeautifulSoup 2 import requests 3 import pandas 4 from simple_proxy import ProxyIPWormXiCi; 5 from header import proxy, Header; 6 7 def dealwithKey(info): 8 for k in info: 9 if '层' in k: 10 info['楼层']=info.pop(k) 11 elif '进门' in k: 12 info['朝向']=info.pop(k) 13 elif '程度' in k: 14 info['装修']=info.pop(k) 15 16 def get_house_detail(url): 17 try: 18 info={} 19 info_adj={} 20 res=requests.get(url) 21 soup=BeautifulSoup(res.text,'html.parser') 22 # soup = proxy(main_url); 23 info['标题']=soup.select('.title h1')[0].text.strip() 24 info['总价']=soup.select('.price_esf ')[0].text.strip() 25 for item in soup.select('.trl-item1'): 26 key = item.select('.font14')[0].text.strip() 27 value=item.select('.tt')[0].text.strip() 28 info[key]=value 29 dealwithKey(info) 30 return info 31 except Exception: 32 print("此页异常:{}".format(url)); 33 return None; 34 35 36 #用item做为循环变量名,代表当前网页class为trl-item1的所有标签节点 37 #key表示item标签下所有class为font14的标签节点文本内容 38 #print(key) 39 #value示item标签下所有class为tt的标签节点文本内容 40 #将info里面所有key赋值给value 41 # k=#创建列表变量k,为了统一字段(有的“楼层”,有的“中层(地20上共3层”) 42 #info_adj= #利用dict(zip(list1,list2))创建新的字典(调整字段后的) 43 #返回info_adj 44 45 def dfb(main_url, houseary): 46 res = requests.get(main_url, headers=Header().headers) #获取上海在售二手房源网页首页(http://esf.sh.fang.com/)的响应包,命名为res 47 soup = BeautifulSoup(res.text, 'html.parser') # 创建BeautifulSoup对象对res响应包进行解析,结果命名为soup 48 # soup = proxy(main_url);#使用代理ip爬取 49 domain1 = 'http://esf.sh.fang.com/' 50 for house in soup.select('.shop_list dl dd h4 a'):#循环遍历获取网页首页所有房源详细内容页的url,循环变量名为house(提示:检查定位路径定位查找的节点是否为空) 51 url = domain1+house['href']#利用domain与存储房屋详细内容的相对url的标签节点构建房屋的url 52 # print(url)#打印输出查看url 53 # dfb1(url) 54 info = get_house_detail(url) 55 print("info:{}".format(info)); 56 if info != None: 57 houseary.append(info) 58 return houseary; 59 60 if __name__ == "__main__": 61 main_url = 'http://esf.sh.fang.com/house/i3'; 62 xici_ip = ProxyIPWormXiCi("http"); #调用同学写好的代理ip,本人直接用 63 xici_ip.get_pages_ips(xici_ip.start_page, ); 64 houseary = []; 65 for i in range(1,100): 66 print("当前第:{}".format(i)); 67 houseary = dfb(main_url + str(i) + "/", houseary); 68 if len(houseary) == 0: 69 print("稍后再试,请从第{}页开始".format(i)); 70 break; 71 df = pandas.DataFrame(houseary)#将获取到的所有房屋信息转换成数据框的结构 72 df.to_csv('house.csv', mode="a", encoding="ANSI");
这是我获取数据,总共12479条:

三、数据分析
1. 地理位置
找二手房房,第一个看的肯定是地理位置。毕竟每个人都想住的地方离公司近一些,这样就不用花费太多时间在通勤上。虽然大家都默认在一线城市工作的通勤时间单程普遍为1小时左右。但是如果能够住的近一点,不用花那么多时间在路上,这样幸福感肯定会提高。
先来看一个总体二手房价格水平:
- 静安&卢湾&黄浦&海淀地区,租房价格是最贵的,平均价格皆接近十万元(每平方)
- 闵行&宝山&嘉定&闵行&松江&青浦&奉贤,因为浦东新区,其房租价格也不便宜,平均皆接近五万元(每平方)
- 卢湾&闸北等地区,作为新崛起的著名城市地区,其则便宜有些可以达到旧中心价格,也有和浦东新区差不多


由上图可得,各地区的均价基本都在20000以上,其中闵行的房源数最多,但均价中等,为46959元/平方,这或许与闵行作为商业区有关系,2018年,实现社会消费品零售总额942.14亿元,比2016年增长5.6%。至年末,闵行区共有各类市场113个。闵行区现有1个国家级社区商业示范社区(闵行区百联南方购物中心);4个市级社区商业示范社区(闵行区百联南方购物中心、七宝社区商业中心、春申万科城商业街、闵行区莘庄镇仲盛世界商城社区);4个上海特色商业街区(虹梅路休闲街、七宝老街、十尚坊休闲餐饮街、虹泉路韩国街)。
由上图可以看出,均价在40000-60000之间的房屋数量最多,同时15000-20000这个价位之间房屋数少的可怜。
据上海市统计局的数据,2018年全市居民月人均可支配收入为64183元。。
上海二手房的出售收入比,惊人地接近60%。很多人一生一大半的收入,都花在了买房上,人生就这样被锁定在贫困线上。
统计数据也表明,上海买二手房人群收入整体偏低。47%的人,年薪在10万以下。就这样,第一批90后扛过了离婚、秃头、出家和生育,终于还是倒在了买房面前。
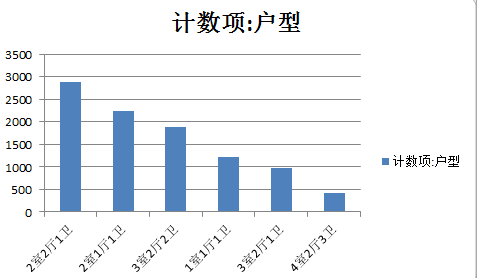
2. 户型
年轻人在看房屋物理信息的时候,首先关注的可能是户型。因为房屋户型的格局在很大程度上决定了租客的生活方式。例如,如果房子是4室0厅,那说明,这个房子会是比较拥挤和阴暗的,在洗漱问题上会比较紧张;如果房子3室一厅,带厨房和卫生间,带阳台,那就说明这个房子的采光比较好,整体明亮宽敞,是一个比较合适的居住环境;有的房屋不带厨房,那就说明之后做饭就不太可能了。
所以有过租房经验的年轻人,能够从户型上看出一些房屋的真实居住情况;而对追求安静舒服想要自己的控件的租客来说,1室户是最好的选择。由于政策对群租房的限制,所以现在房子的户型多为3室一厅,最多4室。
当然,随着越来越多的租客想要独立的空间,1室户的房源也越来越多。
3. 楼层
楼层其实和电梯的关联度比较高。老小区一般楼层较低,但是没有电梯。但是新小区的话,楼层高,有电梯。所以如果有电梯的话,年轻人对楼层的要求度不高。反而对电梯的要求度更高,毕竟现在谁愿意爬楼梯呢?
当然也会有人考虑某些楼层段的房屋空气质量不好,但这些在租房的情况下是少数,更多的是买房的时候会考虑中低层的楼房。

4. 朝向/装修
大家都知道房子要坐北朝南,这样才能有阳光、采光好、温度好。但对于租房的年轻人来说,房子的朝向似乎并没有那么重要,毕竟大家白天更多时间都在公司上班,关心朝向的唯一作用可能就是好不好晒衣服。但也没有谁特意选择某一个朝向的房屋。
而且现在在建造房子的时候,楼栋间的间隔都经过计算,不管哪个方向的房屋,都不存在因为朝向不好就非常潮湿阴暗的问题。毕竟现在窗户大、有空调就已经能解决这两个问题了。

关于装修,现在租房平台上的房源的装修都是已经装修过,至少看的过去。对于是精装还是简装,相信大部分年轻人还是更关心精装比简装贵多少钱。
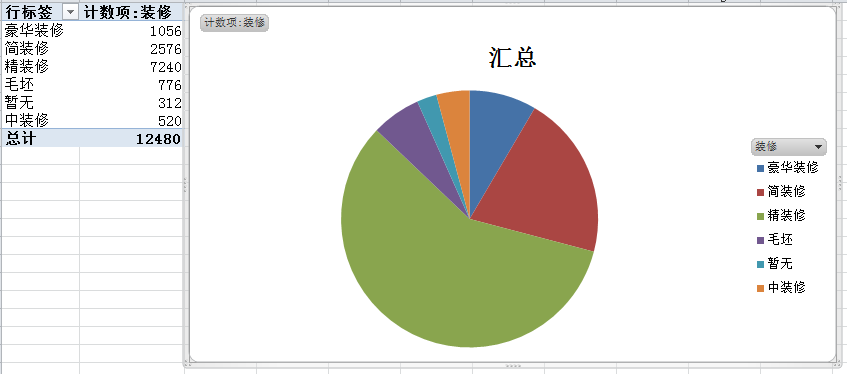
总的来说,朝向和装修都是租客关心的若因素。所以大部分租房平台并不会展示“装修”这一信息。还有一点就是现在的装修成本和装修难度已经大大降低了,从淘宝上购买自己喜欢的装饰物,参照一些照片,自己动手,不管是北欧风还是Ins风,都不是什么复杂的事情。
6.
1 # -*- coding: utf-8 -*-
2 import jieba # 加载停用表
3 import pandas as pd
4 from wordcloud import WordCloud
5 import matplotlib.pyplot as plt
6 # 分解
7 article = open("fuli.txt", "r", encoding='utf-8').read()
8 jieba.add_word('近地铁')
9 jieba.add_word('精装')
10 jieba.add_word('降价)
11 jieba.add_word('带家电')
12 jieba.add_word('电梯')
13 jieba.add_word('采光')
14 jieba.add_word('出行方便')
15 jieba.add_word('拎包入住')
16 jieba.add_word('诚心出售')
17 jieba.add_word('户型正')
18 jieba.add_word('花园')
19 jieba.add_word('急售')
20 jieba.add_word('楼层好')
21 jieba.add_word('1室1厅')
22 jieba.add_word('景观')
23 jieba.add_word('随时')
24 jieba.add_word('品质小区')
25 jieba.add_word('朝南')
26 jieba.add_word('低价')
27 jieba.add_word('视野阔')
28 jieba.add_word('房型正')
29 jieba.add_word('位置好')
30 jieba.add_word('绿化带')
31 jieba.add_word('诚售')
32 jieba.add_word('产权')
33 jieba.add_word('环境安静')
34 jieba.add_word('配套完善')
35 words = jieba.cut(article, cut_all=False) # 统计词频
36 stayed_line = {}
37 for word in words:
38 if len(word) == 1:
39 continue
40 else:
41 stayed_line[word] = stayed_line.get(word, 0) + 1
42 print(stayed_line) # 排序
43 xu = list(stayed_line.items())
44 # print(xu)
45 #存到csv文件中
46 pd.DataFrame(data=xu).to_csv("fuli.csv",encoding="utf_8_sig")
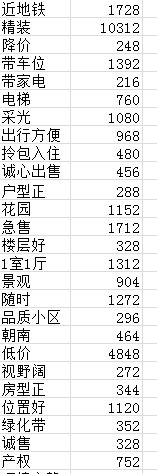

7. 结论描述
- 上海价格受地理因素严重影响,越靠近内环租房价格越贵。
- 三四环附近如海淀、朝阳等区域,企业聚集人流量大,租房价格仍然居高不下
- 对于买二手房一族,租房比较实惠的地方在丰台顺义昌平等地区,并且最好离附近地铁站有一定距离,借助共享单车或步行完成最后一公里路程,至少能给自己节省30%的经济支出
- 至于房屋朝向、高低楼层等因素,现在有其他因素(比如:空调,烘干机等工具)实在不必过多考虑