一、简述Hadoop平台的起源、发展历史与应用现状。
1.起源:
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
总结起来,Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变关系
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
2.发展历史
说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google。Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的GFS(Google File System),从此文件系统进入分布式时代。
除此之外,Google在GFS上如何快速分析和处理数据方面开创了MapReduce并行计算框架,让以往的高端服务器计算变为廉价的x86集群计算,也让许多互联网公司能够从IOE(IBM小型机、Oracle数据库以及EMC存储)中解脱出来,例如:淘宝早就开始了去IOE化的道路。然而,Google之所以伟大就在于独享技术不如共享技术,在2002-2004年间以三大论文的发布向世界推送了其云计算的核心组成部分GFS、MapReduce以及BigTable。Google虽然没有将其核心技术开源,但是这三篇论文已经向开源社区的大牛们指明了方向,一位大牛:Doug Cutting使用Java语言对Google的云计算核心技术(主要是GFS和MapReduce)做了开源的实现。
后来,Apache基金会整合Doug Cutting以及其他IT公司(如Facebook等)的贡献成果,开发并推出了Hadoop生态系统。Hadoop是一个搭建在廉价PC上的分布式集群系统架构,它具有高可用性、高容错性和高可扩展性等优点。由于它提供了一个开放式的平台,用户可以在完全不了解底层实现细节的情形下,开发适合自身应用的分布式程序。
2004年12月。Google发表了MapReduce论文,MapReduce允许跨服务器集群,运行超大规模并行计算。Doug Cutting意识到可以用MapReduce来解决Lucene的扩展问题。
Google发表了GFS论文。
Doug Cutting根据GFS和MapReduce的思想创建了开源Hadoop框架。
2006年1月,Doug Cutting加入Yahoo,领导Hadoop的开发。
Doug Cutting任职于Cloudera公司。
2009年7月,Doug Cutting当选为Apache软件基金会董事,2010年9月,当选为chairman。
3.应用现状(各大企业开发自己的发行版,并为Apache Hadoop贡献代码列举发展过程中重要的事件、主要版本、主要厂商;国内外Hadoop应用的典型案例。)
Hadoop在国内主要以互联网公司为主,下面主要介绍大规模使用Hadoop或研究Hadoop的公司。
(1)百度
百度在2006年就关注了Hadoop并开始调研和使用,截止2012年,总的集群规模超过7个集群,单集群超过2800台机器节点,Hadoop机器总数超过15000台机器,总的存储容量超过100PB,已经使用的超过74PB,每天提交的作业数目超过6600个,每天的输入数据量已经超过7500TB,输出超过1700TB。
百度的Hadoop集群为整个公司的数据团队大搜索团队社区产品团队广告团队,以及LBS团体提供统一的计算和存储服务,主要应用包括:
数据挖掘与分析
日志分析平台
数据仓库系统
推荐引擎系统
凤巢广告特征抽取与建模
点击计费和反作弊
用户行为分析系统
网盟策略的流式计算
同时百度在Hadoop的基础上还开发了自己的日志分析平台、数据仓库系统,以及统一C++编程接口,并对Hadoop深度改造,开发了Hadoop C++扩展HCE系统。
(2) 阿里巴巴
阿里巴巴的Hadoop集群截止2012年大约3200台服务器,物理CPU大约30000核心,总的内存100TB,总的存储容量超过60PB,每天的作业数目超过150000个,每天hive query查询大于6000,每天扫描数据量约为7.5PB,每天扫描文件数约为4亿,存储利用率大概为80%,CPU利用率平均65%,峰值可以达到80%。阿里的Hadoop集群拥有150个用户组,4500个集群用户,为淘宝、天猫、一淘、聚划算、CBU、支付宝提供底层的基础计算和存储服务,主要应用包括:
数据平台系统
搜索支撑
广告系统
数据魔方
量子统计
淘数据
推荐引擎系统
搜索排行榜
同时为了便于开发,还开发了WEB IDE继承开发环境,使用的相关系统包括:Hive,Pig,Mahout,Hbase等。
(3) 腾讯
腾讯也是使用Hadoop最早的中国互联网公司之一,截止2012年底,腾讯的Hadoop集群机器总量超过5000台,最大单集群约为2000个节点,并利用Hadoop-hive构建了自己的数据仓库系统TDW,同时还开发了自己的TDW-IDE基础开发环境。腾讯的Hadoop为腾讯各个产品线提供基础云计算和云存储服务,支撑的领域包括以下产品:
腾讯社交广告平台
搜搜SOSO
拍拍网
腾讯微博
腾讯罗盘
QQ会员
腾讯游戏支撑
QQ空间
朋友网
腾讯开放平台
财付通
手机QQ
QQ音乐
(4)奇虎360
奇虎360主要使用Hadoop-hbase作为其搜索引擎so.com的底层网页存储架构系统,360搜索的网页可到千亿记录,数据量在PB级别。截止2012年底,其Hbase集群规模超过300节点,region个数大于10万个,使用的平台版本为:
HBase版本:facebook 0.89-fb
HDFS版本: facebook Hadoop-20
奇虎360在Hadoop-Hbase方面的工作主要为了优化减少Hbase集群的启停时间,并优化减少RS异常退出后的恢复时间。
(5)华为
华为公司也是Hadoop重要贡献公司之一,排在Google和Cisco的前面,华为在Hadoop的HA方案,以及HBASE领域有深入研究,并已经向业界推出了自己的基于Hadoop的大数据解决方案。
(6) 中国移动
中国移动于2010年5月正式推出大云BigCloud1.0,集群节点达到了1024。中国移动的大云基于Hadoop的MapReduce实现了分布式计算,并利用了HDFS来实现分布式存储,并开发了基于Hadoop的数据仓库系统HugeTable,并行数据挖掘工具集BC-PDM,以及并行数据抽取转化BC-ETL,对象存储系统BC-ONestd等系统,并开源了自己的BC-Hadoop版本。
中国移动主要在电信领域应用Hadoop,其规划的应用领域包括:
经分KPI集中运算
经分系统ETL/DM
结算系统
信令系统
云计算资源池系统
物联网应用系统
Email
IDC服务等
(7) 盘古搜索
盘古搜索主要使用Hadoop集群作为搜索引擎的基础架构支撑系统,截止2013年初,集群中机器数量总计超过380台,存储总量总计3.66PB,主要的应用包括:
网页存储
网页解析
建索引
Pagerank计算
日志统计分析
推荐引擎等
(8)即刻搜索(人民搜索)
即刻搜索也使用Hadoop作为其搜索引擎的支撑系统,截止2013年,其Hadoop集群规模总计超过500台节点,配置为双路6核心CPU,48G内存,11*2T存储,集群总容量超过10PB,使用率在78%左右,每天处理读取的数据量约为500TB,峰值大于1P,平均约为300TB。
即刻搜索在搜索引擎中使用sstable格式存储网页并直接将sstable文件存储在HDFS上面,主要使用Hadoop pipes编程接口进行后续处理,也使用streaming接口处理数据,主要的应用包括:
网页存储
解析
建索引
推荐引擎
二、MySql和Hadoop的安装与配置的截图。
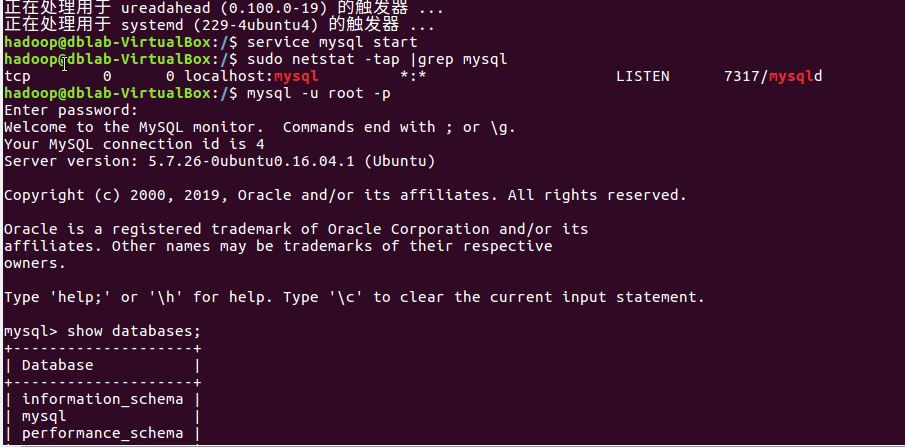
1.成功安装MySql并检测是否可以开启
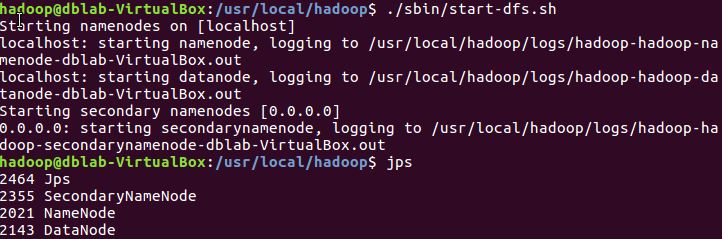
2.成功安装Hadoop并开启,用jps查节点开启情况
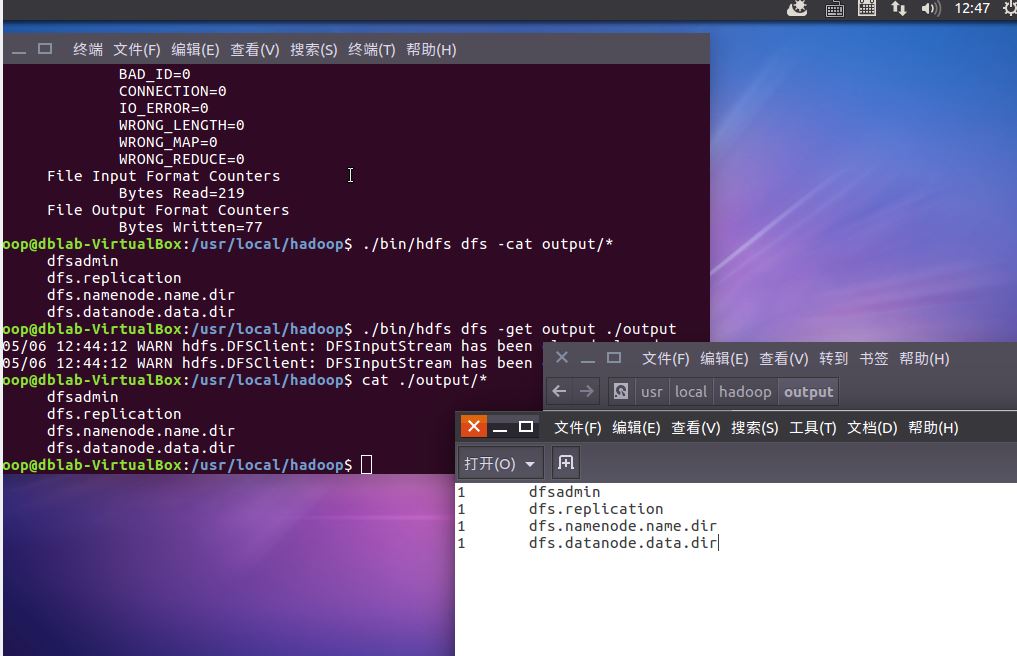
3.配置完Hadoop伪分布式查看位于hdfs的输出结果并下载到本地查看