dates=pd.date_range('20160728',periods=6) #创建固定频度的时间序列 df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) #创建6*4的随机数,索引,列名称。 df2=pd.DataFrame({'A':pd.Timestamp('20160728'),'B':pd.Series(1)})#字典创建Dataframe,假如字典的数据长度不同,以最长的数据为准。 df2.dtypes #查看各行的数据格式 df2.head() df2.tail(5) #查看前、后几列 df.columns df.value #查看列名、value df.describe() #查看描述性的统计,比如每一列的count、mean、std... df.T df.sort(columns='C') #转秩、排序 df['A'] df[1:3]#选择A列数据,选择1-2行数据,切片操作得到的是行数据。 df.loc[:,['A','B']] #选择多列数据 df.loc['20160728':'20160730',['A','B']] #选择局部区域 df.at[dates[0],'A'] #选择某个值 df.iloc[3] df.iloc[1,1]#提取第四行数据,取第2行第2列的这个数 df.iloc[3:5,0:2] #像array一样切片操作 df.iloc[[1,2,4],[0,2]] #提取不连续的行和列 df.iat[1,1]#专门取某个数,效率比较高 df[(df.D>0)&(df.C<0)] #选择D列数据大于0的行 df[['A','B']][(df.D>0)&(df.C<0)]#选择D列数据大于0的行,只返回A,B两列 df['D'].isin(alist)#alist是一个预先定义的列表,把要筛选的值写到列表中,查找D数据中含有alist的值 os.getcwd()#获得当前的工作目录 df=pd.read_csv('',encoding='gbk',sep=',')#读取csv文件 counts=df[u'专业名称'].value_counts() #计数统计 plt=counts.plot(kind='bar').get_figure() plt.savefig('d/plot.png') #画图 good=df[df[u'高考分数']>520] #筛选 good_counts=good[u'专业名称'].value_counts() per=good_counts/counts #计算百分比,直接利用矩阵的除法 df.groupby('A').first() #按A列分组,输出每一组的第一行数据 df.groupby(['A','B']) #按两列分组 #创建函数,作为分组标准。 下例:如果列名是abem中的之一,就分为组别v反之为w def get_type(letter): if letter.lower() in 'abem': return 'v' else: return 'w' grouped=df.groupby(get_type,axis=1) import pandas.util.testing as tm colors=tm.choice(['red','green'],size=10) foods=tm.choice(['eggs','ham'],size=10) #随机创建两个数组 index=pd.MultiIndex.from.arrays([colors,foods],names=['color','food']) #创建MultiIndex对象,然后创建DataFrame对象 df.pd.DataFrame(np.random.randn(10,2),index=index) print df.query('color=="red"') #查询 grouped=df.groupby(level='food')#在分组中使用索引 df.index.names=[None,None] print df.query('ilevel_0=="red"')#删除了索引名称,只能使用ilevel_0表示第一个索引
grouped=df.groupby(level=1) grouped.aggregate(np.sum) #计算各组的总和 print grouped.aggregate(np.sum).reset_index()#将索引转化为列向量 df.groupby(level=['color'],as_index=False).sum()#能达到一样的效果 print grouped.size()#返回每个组的数据量 print grouped.discribe()#返回各组数据的描述性信息 #transformation标准化数据 import pandas as pd import numpy as np index=pd.date_range('20140101',periods=100) ts=pd.Series(np.random.normal(0.5,2,100),index) print ts.head() key=lambda x:x.month zscore=lambda x:(x-x.mean())/x.std() transformed=ts.groupby(key).transform(zscore) print type(transformed) print transformed.groupby(key).mean() print transformed.groupby(key).std()
#使用agg grouped=df.groupby(level='color').agg(['SUM':np.sum,'MEAN':np.mean,'STD':np.std]) #通过lambda匿名函数来进行特殊计算 print grouped['a'].agg({'lambda':lambda x:np.mean(abs(x))})
#按月分组 key =lambda x:x.month grouped=ts.groupby(key).agg({'SUM':np.sum,'MEAN':np.mean,'STD':np.std}) print grouped #索引不是日期 df.groupby(df['date'].apply(lambda x:x.month)).first() df.set_index('date')#或者将date设置为索引 #如果日期是字符串形式存储的 date_string =('2010-09-01','2020-01-01') a=pd.Series([pd.to_datetime(date) for date in date_string])
#增加列 df['c']=pd.Series(np.random.randn(10),index=df.index) df.insert(1,'e',df['a'])#在a列后面插入e列 del df['c'] #删除列c df2=df.drop(['a','b'],axis=1)#df数据不变,删除后的数据放入df2中 b=df.pop('b') df.insert(0,'b',b)#移动,pop移除之后再插入
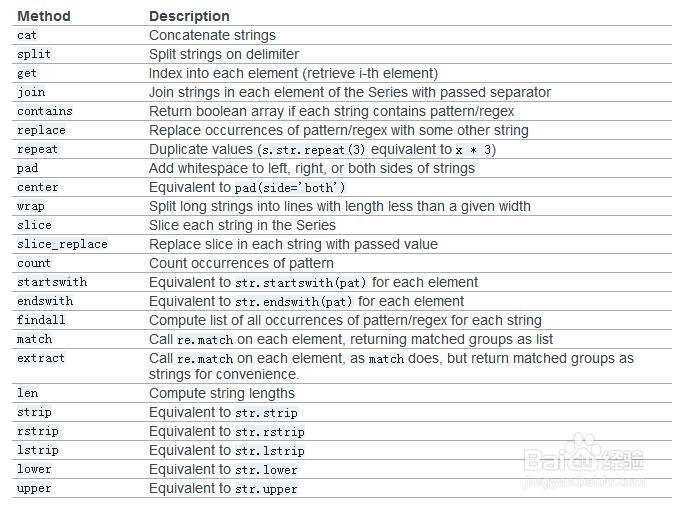
#字符串操作 s=pd.Series(list('ABCDEF') s.str.lower() s.str.upper()#大小写 s.str.len() s.str.split('_').str.get(1) #获取切割后的某个元素 s.str.replace('^a|b$','X',case=False)#替换,第一个参数是正则表达式,第二个是要替换的字符串 s=pd.Series(['a1','a2','b1','b2',c]) s.str.extract('([ab])(d)?') #使用extract方法提取数字:第一个参数是正则表达式,括号表示要提取的部分,结果是a 1,a 2,b 1,b 2,NaN NaN,无法匹配的 s.str.extract('(?P<letter>[abc])(?P<digit>d)') #输出的结果包含变量名 pattern=r'[a-z][0-9]' print s.str.contains(pattern,na=False)#匹配字符串,na参数用来说明出现NaN数据时匹配成True还是False s.str.match(pattern,as_index=False)#严格匹配字符串 s.str.endswith('l',na=False) #等效于contains('l$',na=False) s.str.startwith('l',na=False)#等效于contains('^l',na=False)
#读写数据库 import MySQLdb con=MySQLdb.connect(host="localhost",db="") sql="SELECT * FROM..." df=pd.read_sql(sql,con,index_col='id') con2=execute('DROP TABLE IF EXISTS wheather') pd.io.sql.write_frame(df,"wheather",con2)
#缺失值数据处理 df=pd.DataFrame(np.random.randn(5,3),index=list('abcde'),columns=['one','two','three']) df.ix[1,:-1]=np.nan #在简单的运算中,遇到缺失值,运算结果也是缺失值,在描述性统计中,Nan都是作为0进行运算 #df.loc[:,['one','three']] df.fillna(0) #用0填充缺失值 df.fillna('missing') 用字符串代替缺失值 df.fillna(method='pad')#用前一个数据代替NaN df.fillna(method='bfill',limit=1)#用后一个数据替代NaN,限制每列只能替代一个NaN df.fillna(df.mean()['one':'two'])#用平均数代替,选择one,two两列进行缺失值处理 df.dropna(axis=0) #删除含有NaN的行,axis=1 删除列 df.interpolate() #使用插值来估计NaN 如果index是数字,可以设置参数method='value' ,如果是时间,可以设置method='time' df.replace({1:11,2:12})