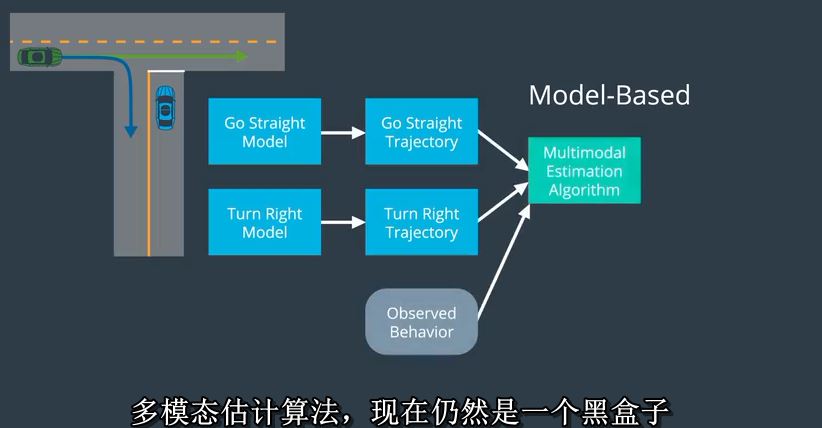
想象一下T形交叉口。蓝色的自动驾驶汽车拉到停车标志,并会左转,但看到这辆绿色的汽车从左边出来。
如果绿色的汽车向右转,这辆蓝色汽车是安全的。但如果绿色汽车正在直行,那么蓝色的汽车应该等待。
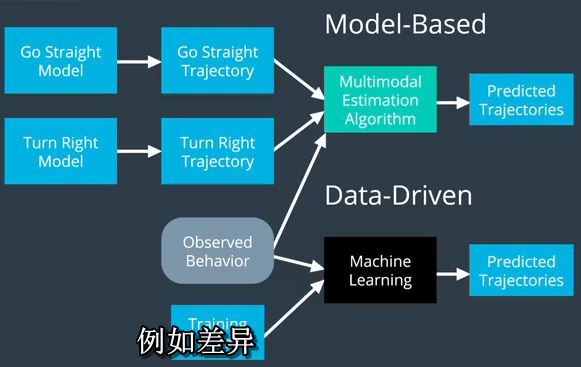
我们用基于模型的方法处理这个问题的方式如下。首先,我们会提出两个流程模型,一个直行,一个右转。
我们会用一些简单的轨迹发生器来弄清楚我们期望看到的是什么轨迹,司机正在直行或向右转。
然后我们会注意目标车辆的实际行为和使用多模态估计算法,现在仍然是一个黑盒子,比较观察到的轨迹和我们对每个模型所期望的轨迹。
然后基于我们的意愿为每个可能的轨迹分配一个概率。
但纯粹基于模型的预测的重要内容是我们有一些可能的行为,每个都有一个数学模型,考虑物体物理性能的运动作为道路交通法律和其他限制所施加的限制。
数据驱动方法呢?
那么纯粹的数据驱动的方法,我们有一个真正的黑匣子算法,这个算法将被训练在大量的训练数据上。
一旦它被训练,我们就安装好了,观察到的行为并让它预测下一步会发生什么。
所以我们可以看到每种方法都有其自身的优势。基于模型的方法结合我们的知识道路交通等物理限制
数据驱动的方法很好,因为它们让我们使用数据提取微妙的模式,否则将被基于模型的方法遗漏。
例如差异在一天中不同时间的交叉口处的车辆行为。这导致了一些有点问题。哪种方法最好。