1、Collection和Collections的区别?
(1)Collection是一个接口,为集合对象的基本操作提供通用的接口放法。
(2)Collections是一个工具类,里面包含各种对集合的操作放法,是服务于Collection框架的工具类。不能实例化。
如Collections.sort()方法就可以对一个ArrayList对象进行排序。
2、Collection和Map框架结构图
(1)下图均为接口

(2)下图为接口实现类(白色部分为实现类)

3、实现类详解
(1)ArrayList和LinkedList
I ArrayList
ArrayList底层是数组实现,构造ArrayList的时候,默认数组的初始化容量为10,容器为Object[] elementData。向集合添加元素的时候,调用add方法,比如list.add("a");add方法做的操作是:elementData[size++] = e; 然后元素就被存放进了elementData。
源码,add方法中先调用ensureCapacity方法对原数组长度进行扩充,扩充方式为,通过Arrays类的copyOf方法对原数组进行拷贝,长度为原数组的1.5倍+1。
然后把扩容后的新数组实例对象地址赋值给elementData引用类型变量。扩容完毕。这就是ArrayList为可变数组的原理。。。。
1 public class ArrayList<E> extends AbstractList<E> implements List<E> { 2 private transient Object[] elementData; 3 4 public ArrayList(int initialCapacity) { 5 super(); 6 if (initialCapacity < 0) 7 throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); 8 this.elementData = new Object[initialCapacity]; 9 } 10 //Constructs an empty list with an initial capacity of ten. 11 public ArrayList() { 12 this(10); 13 } 14 public boolean add(E e) { 15 ensureCapacity(size + 1); // 扩充长度 16 elementData[size++] = e; // 先赋值,后进行size++。所以是从[0]开始存。 17 return true; 18 } 19 public void ensureCapacity(int minCapacity) { 20 modCount++; 21 int oldCapacity = elementData.length; // 旧集合长度 22 if (minCapacity > oldCapacity) { 23 Object oldData[] = elementData; // 旧集合数据 24 int newCapacity = (oldCapacity * 3)/2 + 1; // 计算新长度,旧长度的1.5倍+1 25 if (newCapacity < minCapacity) 26 newCapacity = minCapacity; 27 // minCapacity is usually close to size, so this is a win: 28 elementData = Arrays.copyOf(elementData, newCapacity); // 这就是传说中的可变集合。用新长度复制原数组。 29 } 30 } 31 public E get(int index) { 32 RangeCheck(index); 33 return (E) elementData[index]; 34 } 35 }
当add()容量够时,就是直接在后面添加,速度很快。
当add()容量不够时,就将新建一个更大的数组,然后把旧数组的内容复制过去。
当在中间位置插入时,会把插入点及后面的数据后移一个位置。然后插入。
当在中间位置删除时,会将删除点后面的数据前移一个位置。
所以说任何时间点,其内存都是连续的,随机索引访问效率很高。
插入,删除效率低。或者容量满时add()效率低。
ArrayList例子:

II LinkedList
LinkedList底层数据结构是基于双向链表的。且头结点中不存放任何数据
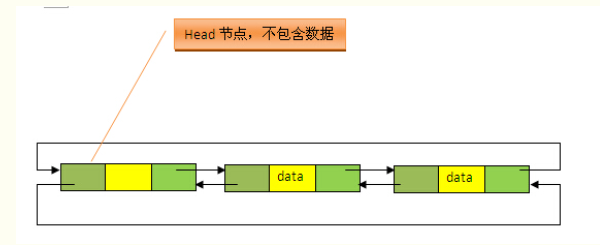
既然是双向链表,那么必定存在一种数据结构——我们可以称之为节点,节点实例保存业务数据,前一个节点的位置信息和后一个节点位置信息,如下图所示:

节点类Entry
private static class Entry<E> { E element; Entry<E> next; Entry<E> previous; Entry(E element, Entry<E> next, Entry<E> previous) { this.element = element; this.next = next; this.previous = previous; } }
节点类很简单,element存放业务数据,previous与next分别存放前后节点的信息(在数据结构中我们通常称之为前后节点的指针)。
LinkedList的add方法
// 将元素(E)添加到LinkedList中 public boolean add(E e) { // 将节点(节点数据是e)添加到表头(header)之前。 // 即,将节点添加到双向链表的末端。 addBefore(e, header); return true; } public void add(int index, E element) { addBefore(element, (index==size ? header : entry(index))); } private Entry<E> addBefore(E e, Entry<E> entry) { Entry<E> newEntry = new Entry<E>(e, entry, entry.previous); newEntry.previous.next = newEntry; newEntry.next.previous = newEntry; size++; modCount++; return newEntry; }
add执行步骤
(1)
其中,header是一个Entry对象,存储了当前节点的previous(前一节点)和next(后置节点),
(2)
初始化一个预添加的Entry实例(newEntry)。
Entry newEntry = newEntry(e, entry, entry.previous);

(3):调整新加入节点和头结点(header)的前后指针。
newEntry.previous.next = newEntry;
newEntry.previous即header(节点一的previous),newEntry.previous.next即header(节点一)的next指向newEntry实例。在上图中应该是“4号线”指向newEntry。
newEntry.next.previous = newEntry;
newEntry.next即header,newEntry.next.previous即header的previous指向newEntry实例。在上图中应该是“3号线”指向newEntry。
添加后续数据情况和上述一致,LinkedList实例是没有容量限制的。
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表,数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,
所以查询速度快,增删较慢。而链表正好相反,由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快
III hashcode
查看Object类的源码可知,hashcode是一个本地方法,
public native int hashCode();
Integer类型数据的求hashcode方法
public static int hashCode(int value) { return value; }
即数字本身
String 类求hashcode方法
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值 ,
1)、HashMap是非线程安全的,HashTable是线程安全的。
2)、HashMap的键和值都允许有null值存在,而HashTable则不行。
3)、因为线程安全的问题,HashMap效率比HashTable的要高。
参考http://www.cnblogs.com/ITtangtang/p/3948610.html#a1