收到ES的告警,在1小时内意外分配了碎片,从而导致集群状态 Green > Yellow > Red > Yellow > Green 频繁切换?在此期间,ES不可访问,并且调用API开始返回非200的状态码。
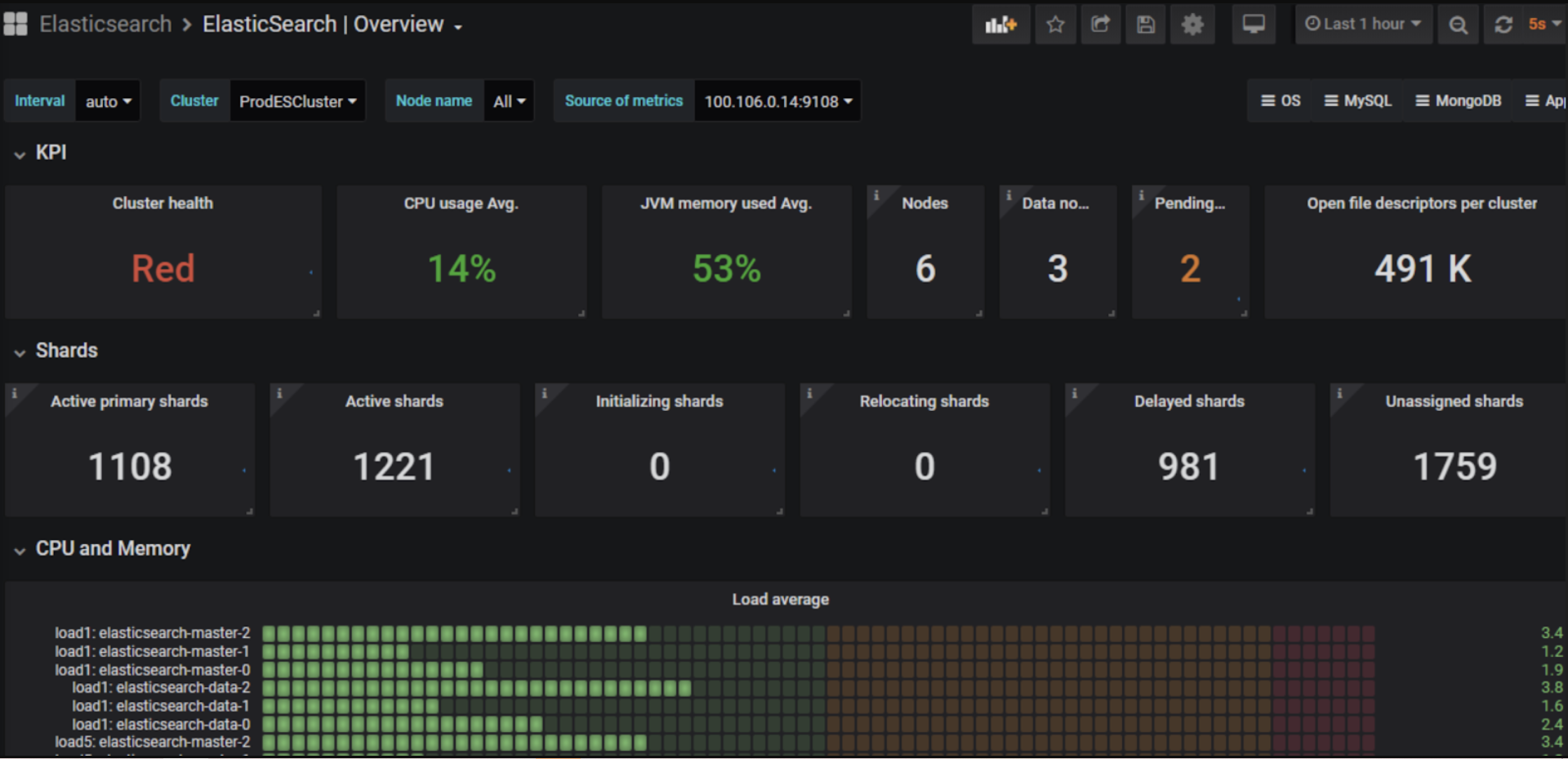
环境
3个主节点和3个工作节点。
错误分析
GC锯尺图
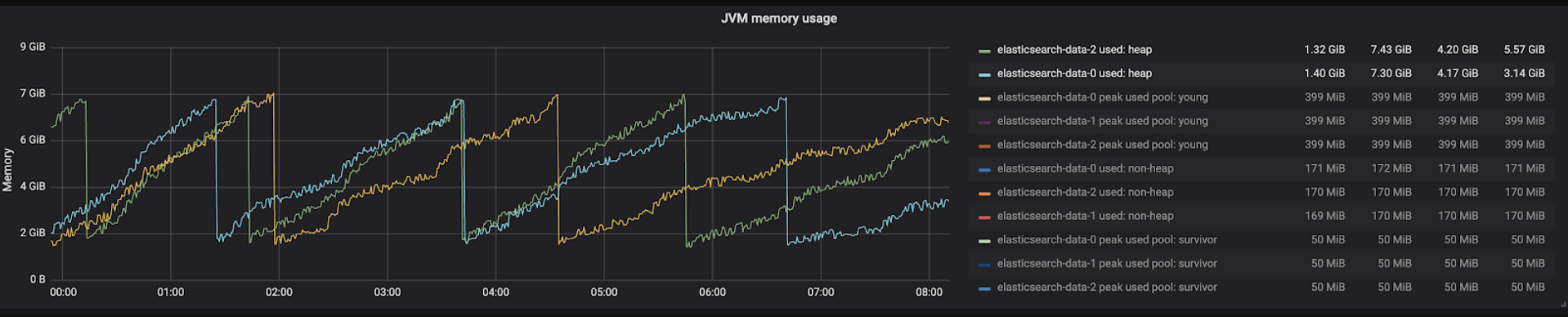
这种锯尺模式的原因是,ELasticsearch在执行某些操作搜索查询,写入查询,刷新,刷新操作等,频繁的创建新对象,JVM需要不断往堆上分配内存,但是,这些对象大多数都比较短暂,很快就会被堆的young区域中的GC收集。GC完成后,在内存使用图表中看到它下降。
注意:大多数Elasticsearch对象都是短暂的,并且由Young区域的GC收集。
对象的高分配率导致性能问题
GC日志提供了一种捕获应用程序分配对象频率的方法。虽然高分配率不一定是问题,但它们可能导致性能问题。要查看这是否影响应用,可以比较收集之后和下一个收集之前的young 一代的大小。
例如,以下三条GC日志显示该应用程序正在以约12.48GB /秒的速度分配对象。
[31.087s][info ][gc ] GC(153) Pause Young (Normal) (G1 Evacuation Pause) 3105M->794M(3946M) 55.590ms
[31.268s][info ][gc ] GC(154) Pause Young (Normal) (G1 Evacuation Pause) 3108M->798M(3946M) 55.425ms
[31.453s][info ][gc ] GC(155) Pause Young (Normal) (G1 Evacuation Pause) 3113M->802M(3946M) 55.571ms
在31.087和31.268之间分配了2314M(3108M-794M),在31.268和31.453之间分配了另外2315M(3113M-798M)。每200毫秒或12.48GB /秒大约可消耗2.3GB。根据应用程序的行为,以该速率分配对象可能会对其性能产生负面影响。
对象的高分配导致频繁收集
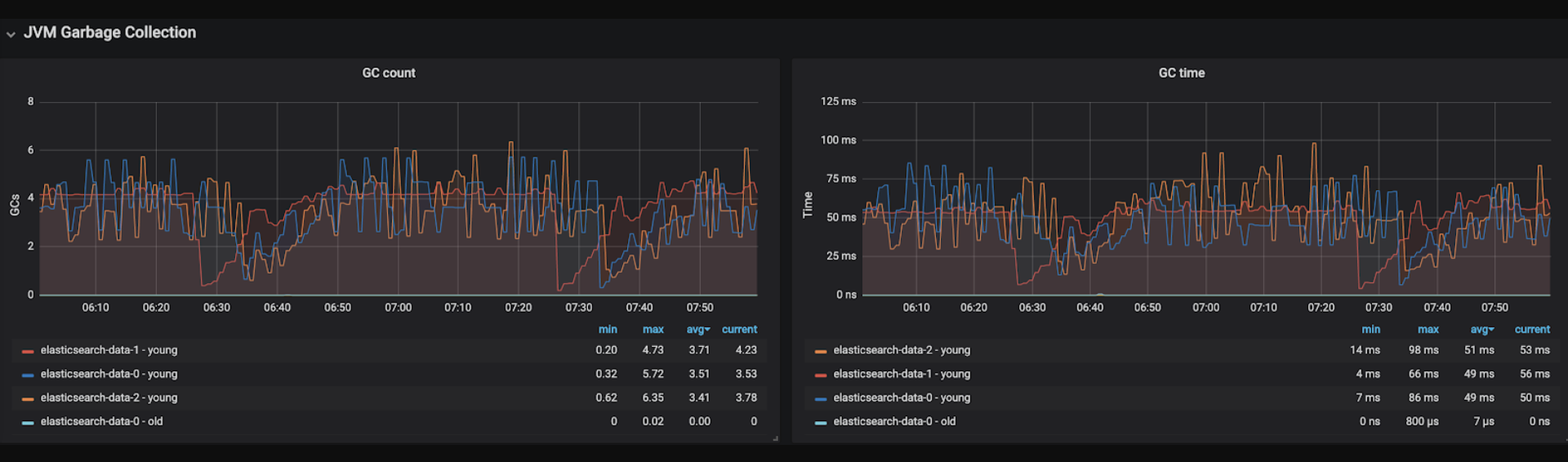
我观察到Garbage Collector每隔1分钟执行一次,这是由于Elasticsearch自己的程序(例如对分片的搜索查询)导致对象分配率很高,而3个worker节点上的许多分片会导致很多对象高频。同样,执行Garage Collector时,也会导致“ Stop the World State”(停止世界状态)意味着主弹性搜索工作人员的主线程停止。当弹性搜索的主线程长时间不响应时,elasticsearch主节点将假定工作节点已离开群集,并在其他节点之间重新分配分片。
以下是从Elasticsearch日志中获得的示例错误:

解决方案
以前,我为每个索引设置“ 2个具有6个副本的主节点”,这会导致大量分片,而更多的分片意味着对每个分片进行更多的并行读取操作,从而导致频繁创建更多的对象。Elasticsearch建议每个节点有600个分片。
因此,我决定进行以下更改:
- 2主节点和1个副本
- work节点从3增加到5
增加工作节点的原因
首先,随着工作节点数量的增加,我们能够在每个节点上保持最小的碎片数。
其次,以前(在每个工作节点上)有3个并行的垃圾收集器不得不处理大量垃圾收集,但是对于5个垃圾收集器,垃圾收集的任务被划分了。
第三,将碎片划分为5个节点,通过搜索查询创建的对象也将划分为5个节点。因此,在每个节点上,频繁的对象计数减少,从而减少了垃圾收集器执行的频率。