BloomFilter
概述
- 现在有一个非常庞大的数据,假设全是 int 类型。现在我给你一个数,你需要告诉我它是否存在其中(尽量高效)。
- 我想大多数想到的都是用 HashMap 来存放数据,因为它的写入查询的效率都比较高。但是在内存有限的情况下我们不能使用这种方式,因为很容易导致内存溢出
- 因为只是需要判断数据是否存在,也不是需要把数据查询出来,所以完全没有必要将真正的数据存放进去,Bloom Filter就是为了解决这个问题,它主要就是用于解决判断一个元素是否在一个集合中,但它的优势是只需要占用很小的内存空间以及有着高效的查询效率。
Bloom Filter 原理
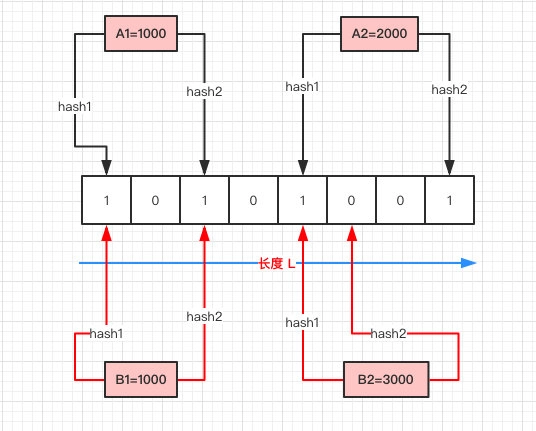
- 首先需要初始化一个二进制的数组,长度设为 L(图中为 8),同时初始值全为 0 。
- 当写入一个 A1=1000 的数据时,需要进行 H 次 hash 函数的运算(这里为 2 次);与 HashMap 有点类似,通过算出的 HashCode 与 L 取模后定位到 0、2 处,将该处的值设为 1。
- A2=2000 也是同理计算后将 4、7 位置设为 1。
- 当有一个 B1=1000 需要判断是否存在时,也是做两次 Hash 运算,定位到 0、2 处,此时他们的值都为 1 ,所以认为 B1=1000 存在于集合中。
- 当有一个 B2=3000 时,也是同理。第一次 Hash 定位到 index=4 时,数组中的值为 1,所以再进行第二次 Hash 运算,结果定位到 index=5 的值为 0,所以认为 B2=3000 不存在于集合中。
布隆过滤有以下几个特点:
- 只要返回数据不存在,则肯定不存在。
- 返回数据存在,但只能是大概率存在。
- 同时不能清除其中的数据。
- 为什么返回存在的数据却是可能存在呢,这其实也和 HashMap 类似。在有限的数组长度中存放大量的数据,即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个数据最后定位到的位置是一模一样的。这时拿 B 进行查询时那自然就是误报了。删除数据也是同理,当我把 B 的数据删除时,其实也相当于是把 A 的数据删掉了,这样也会造成后续的误报。基于以上的 Hash 冲突的前提,所以 Bloom Filter 有一定的误报率,这个误报率和 Hash 算法的次数 H,以及数组长度 L 都是有关的。
实现一个布隆过滤
public class BloomFilters {
/**
* 数组长度
*/
private int arraySize;
/**
* 数组
*/
private int[] array;
public BloomFilters(int arraySize) {
this.arraySize = arraySize;
array = new int[arraySize];
}
/**
* 写入数据
* @param key
*/
public void add(String key) {
int first = hashcode_1(key);
int second = hashcode_2(key);
int third = hashcode_3(key);
array[first % arraySize] = 1;
array[second % arraySize] = 1;
array[third % arraySize] = 1;
}
/**
* 判断数据是否存在
* @param key
* @return
*/
public boolean check(String key) {
int first = hashcode_1(key);
int second = hashcode_2(key);
int third = hashcode_3(key);
int firstIndex = array[first % arraySize];
if (firstIndex == 0) {
return false;
}
int secondIndex = array[second % arraySize];
if (secondIndex == 0) {
return false;
}
int thirdIndex = array[third % arraySize];
if (thirdIndex == 0) {
return false;
}
return true;
}
/**
* hash 算法1
* @param key
* @return
*/
private int hashcode_1(String key) {
int hash = 0;
int i;
for (i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return Math.abs(hash);
}
/**
* hash 算法2
* @param data
* @return
*/
private int hashcode_2(String data) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < data.length(); i++) {
hash = (hash ^ data.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash);
}
/**
* hash 算法3
* @param key
* @return
*/
private int hashcode_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash);
}
}
- 首先初始化了一个 int 数组。
- 写入数据的时候进行三次 hash 运算,同时把对应的位置置为 1。
- 查询时同样的三次 hash 运算,取到对应的值,一旦值为 0 ,则认为数据不存在。
Guava 实现
- Google Guava 库中也实现了该算法,下面来看看业界权威的实现。
@Test
public void guavaTest() {
long star = System.currentTimeMillis();
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
10000000,
0.01);
for (int i = 0; i < 10000000; i++) {
filter.put(i);
}
Assert.assertTrue(filter.mightContain(1));
Assert.assertTrue(filter.mightContain(2));
Assert.assertTrue(filter.mightContain(3));
Assert.assertFalse(filter.mightContain(10000000));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
- 源码分析
- 构造方法中有两个比较重要的参数,一个是预计存放多少数据,一个是可以接受的误报率。我这里的测试 demo 分别是 1000W 以及 0.01。Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 numBits 以及需要计算几次 Hash 函数 numHashFunctions 。
应用场景
- 布隆过滤的应用还是蛮多的,比如数据库、爬虫、防缓存击穿等。
- yahoo, gmail等邮箱垃圾邮件过滤功能