1.吞吐量和延时
吞吐量:吞吐量指的是cpu的利用时间,计算公式是 运行用户代码时间 / (用户代码时间 + 垃圾收集时间),吞吐量越大说明cpu的利用率越大.
延时:延时指的是停顿时间,用户代码不能执行的时间,STW
吞吐量优先和延时优先
吞吐量优先适用于运算任务之中,只是在乎CPU的利用时间,可以更快地完成运算任务.
延时优先更适用于交互任务中,更短的等待时间可以提高用户的体验
吞吐量和延时之间的关系
用GC来说
想要更大的吞吐量就要避免没必要的GC,但是总有避免不了的GC,这个避免不了的GC要处理的垃圾就会变多,处理过程变得复杂,停顿时间就会变长.
想要更短的挺短时间就要增多GC的次数,让每次需要处理的垃圾都平均起来,但是GC次数变多就回到了原点,吞吐量下降了.
垃圾收集器(每个垃圾收集器都没有明确的好与不好,只有适合和不适合)
1.Serial收集器
一个单线程的垃圾收集器,适用STW必须暂停用户进程,当进行垃圾收集的时候是无法对外提供服务的,同时进行垃圾回收的时候适用单线程.
适用场景:新生代
优点:简单而高效,专注于垃圾回收,没有线程上下文切换的资源浪费
2.parNew收集器
是Serial的多线程版本,在新生代GC的时候适用多线程进行垃圾回收,同时是唯一一个能与CMS收集器一起适用的垃圾收集器
适用场景:新生代
优点:能和CMS收集器一起适用,同时在多个CPU的时能有更高效的收集效率
3.Parallel Scavenge收集器
一个吞吐量优先的垃圾收集器,新生代垃圾收集器,收集也是使用多个线程.
适用场景:新生代(使用复制算法)
优点:提供两个参数用于精确地控制吞吐量,分别是控制最大垃圾收集停顿时间 -XX:MaxGCPauseMillis参数和直接设置吞吐量大小: -XX:GCTimeRatio参数.
自带GC自适应调节策略 -XX:+UseAdaptiveSizePolicy参数开启之后,不需要关注新生代eden和s0和s1之间的比例,还有晋升老年代的对象的大小 -XX:PretenureSizeThreshold,虚拟机会自动进行调整为了更好的提高吞吐量。
4.Serial Old收集器
从名字上看就是Serial的老年代垃圾收集器,使用单线程标志-整理算法
适用场景:老年代
优点:标志整理算法自带的空间连续
5.ParallelOld收集器
一款吞吐量优先的老年代垃圾收集器,同时使用多线程的标记-整理算法
使用场景:老年代(标记-整理算法)
优点:吞吐量优先可以充分利用CPU,在一些注重吞吐量和CPU资源敏感的情况下可以事用Parallel Scanvenge和ParallelOld的组合
6.CMS收集器
第一款在进行垃圾收集的时候可以对外提供服务,同时是一款延时优先的垃圾收集器。
使用场景:老年代(标记-清除算法)
优点:在进行垃圾收集的时候可以对外提供服务,同时他是延时优先的,在交互类型中用户会有一个良好的体验。
流程图
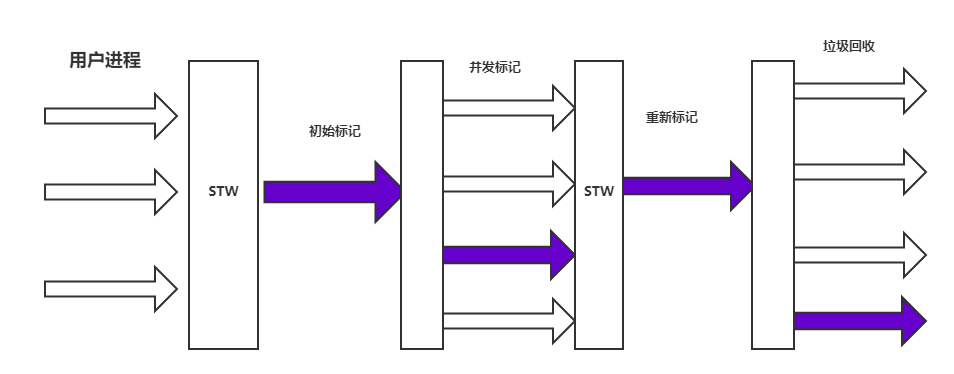
初始标记:单线程就是标记一下GCRoots能够直接到达的对象
并发标记:和用户线程并发的进行GCRoots的可达性分析
重新标记:标记在并发标记过程中用户线程造成的更改
并发清除:和用户进行并发的进行垃圾回收
明显缺点:
1.CPU过于敏感,清除线程的数量 = (cpu个数 + 3) / 4 (cpu 个数 > 4)资源占用率随着cpu个数升高而降低(cpu个数 < 4) 资源占用就会比较高
2.无法处理浮动垃圾
3.cms使用标记清除算法,自带的就是空间碎片问题
7.G1垃圾收集器
将jmm分成了一个个的Region,一般是2048个,大小由堆大小确定
停顿时间优先的,为了替代CMS而出现的,弥补了CMS的大部分缺点,同时可以自己设置停顿时间,在停顿时间里面进行回收,回收垃圾最多的Region
使用分代算法,每个Region分为E,S,O等区域同时有一个H区存储大对象,默认大小超过Region的一半就会进入H区
特点:
1.并发并行:充分利用多个CPU,使用并发来继续执行用户线程
2,分代收集
3.空间整合:基于标记-整理算法
4.可预测的停顿