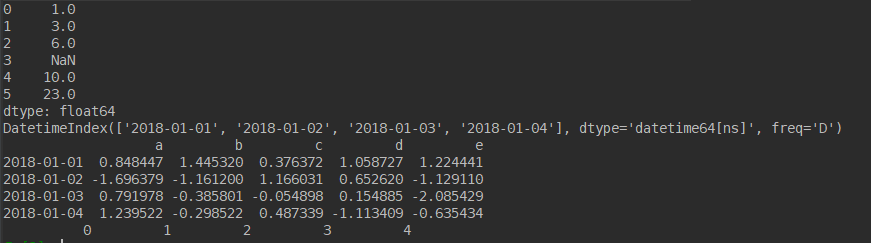
import numpy as np import pandas as pd s = pd.Series([1, 3, 6, np.nan, 10, 23]) print(s) dates = pd.date_range('20180101', periods=4) print(dates) df = pd.DataFrame(np.random.randn(4, 5), index=dates, columns=['a', 'b', 'c', 'd', 'e']) print(df) df = pd.DataFrame(np.random.randn(4, 5)) print(df)
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False) 是一维数组
pandas.DataFrame([data, index, columns, dtype, copy])具有标记轴(行和列)的二维大小可变,可能异构的表格数据结构。 其中index代表行,colums是列
DataFrame:
DataFrame可以从字典形式或者pandas中组建

values属性

describe()方法

transpose()方法和T属性是转置
sort_index()方法,对index进行排序 其中 axis为0是对行排序,ascending是倒叙还是顺序

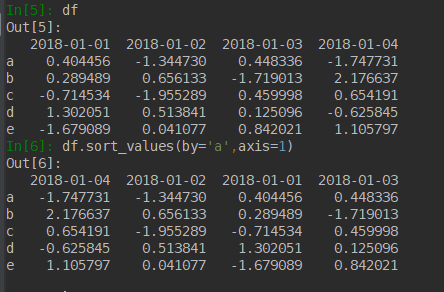
sort_values()方法,对值进行排序 其中 axis为0是对列排序,ascending是倒叙还是顺序
选择数据:
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6,4),index =dates, columns=['A', 'B', 'C', 'D']) print(df.A,df['A']) print(df[0:3]) print(df['20180101':'20180103'])
这四种选择方法都是可以的
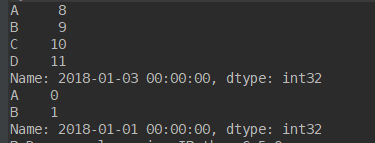
select by label 即 loc
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6,4),index =dates, columns=['A', 'B', 'C', 'D']) print(df.loc['20180103']) print(df.loc['20180101',['A','B']])
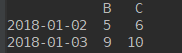
print(df.loc['20180101':'20180102',['A','B']])
select by position: iloc
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) print(df.iloc[[1, 2], [1, 2]]) print(df.iloc[1:3,4:5])
mixed selection:ix
已经被移出了
Boolean indexing
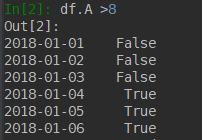
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) print(df[df.A>8])
首先我们看df.A>8是什么
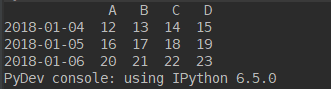
设置值:
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) df.iloc[2,2] = None #位置 df.loc['20180101','B'] = -1 #标签 df.B[df.A>4] = -2 #逻辑 df['F'] = np.nan df['G'] = pd.Series([1,2,3,4,5,6],index=df.index) #添加上一个Series
丢去损失数据
dropna()
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) df.iloc[0, 1] = np.nan df.iloc[1, 2] = np.nan print(df) print(df.dropna(axis=0, how='any'))
其中的how是方法,any代表只要有nan就丢弃,all代表行/列 全部都是nan才丢掉
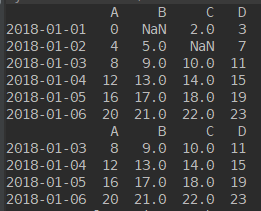
fillna()
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) df.iloc[0, 1] = np.nan df.iloc[1, 2] = np.nan print(df) print(df.fillna(value=0))

isnull() 是否为Nan,返回一个Boolean向量
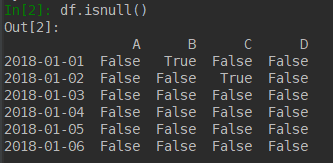
可以配合np.any配合使用,检查是否有Nan
import numpy as np import pandas as pd dates = pd.date_range('20180101', periods=6) df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) df.iloc[0, 1] = np.nan df.iloc[1, 2] = np.nan print(df) print(np.any(df.isnull()) == True)
打印出True
储存和读取:
import numpy as np import pandas as pd data = pd.read_csv('1.csv') data.to_pickle('1.pickel')
合并concat:
ignore_index
import numpy as np import pandas as pd df1 = pd.DataFrame(np.ones([2,3])*0, columns=['a','b','c']) df2 = pd.DataFrame(np.ones([2,3])*1, columns=['a','b','c']) df3 = pd.DataFrame(np.ones([2,3])*2, columns=['a','b','c']) print(df1) print(df2) print(df3) res = pd.concat([df1,df2,df3]) print(res) res = pd.concat([df1,df2,df3], ignore_index=True) print(res)

第一次是没有设置ignore_index 它的排序是010101。第二次就是0到5了
join
参数join模式默认的是outer如下:
import numpy as np import pandas as pd df1 = pd.DataFrame(np.ones([3,4])*0, columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones([3,4])*1, columns=['b','c','d','e']) print(df1) print(df2) res = pd.concat([df1,df2]) #默认join='outer' print(res)
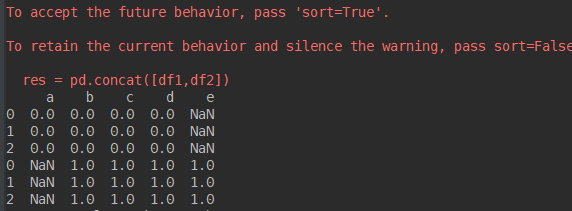
抛出了一个warning,在没有'a'标签的情况下填充NaN
当把join属性转化为inner
import numpy as np import pandas as pd df1 = pd.DataFrame(np.ones([3,4])*0, columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones([3,4])*1, columns=['b','c','d','e']) print(df1) print(df2) res = pd.concat([df1,df2],join='inner') print(res)
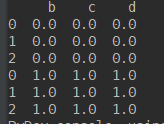
这时候pandas在合并时做裁剪
join_axis()
import numpy as np import pandas as pd df1 = pd.DataFrame(np.ones([3,4])*0, columns=['a','b','c','d'],index=[1,2,3]) df2 = pd.DataFrame(np.ones([3,4])*1, columns=['b','c','d','e'],index=[2,3,4]) print(df1) print(df2) res = pd.concat([df1,df2], axis=1) print(res) res = pd.concat([df1, df2],axis=1, join_axes=[df1.index]) print(res)

join_axis 决定了合并时依照哪个数据的index或者coloums,在没有设置这个参数的情况下他把 1 2 3 4都写进,没有的用Nan填充,当我们把join_axis设置成df1的index,只保留了tf的 1 2 3
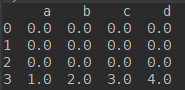
append() 按照行增加数据
import numpy as np import pandas as pd df1 = pd.DataFrame(np.ones([3,4])*0, columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones([3,4])*1, columns=['a','b','c','d']) res = df1.append(df2,ignore_index=True) print(res)
它也有ignore_index参数
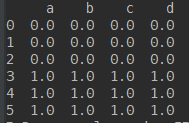
并入一个Series
import numpy as np import pandas as pd df1 = pd.DataFrame(np.ones([3,4])*0, columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones([3,4])*1, columns=['a','b','c','d']) s1 = pd.Series([1,2,3,4], index=['a','b','c','d']) res = df1.append(s1, ignore_index=True) print(res)
merge()
on参数:指明连接键
import pandas as pd left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']}) right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) print(left) print(right) res = pd.merge(left, right, on='key') print(res)
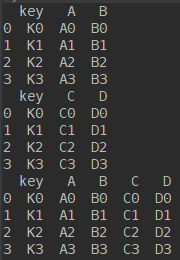
how参数 inner(省却) or outer
import pandas as pd left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']}) right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'], 'key2': ['K0', 'K0', 'K0', 'K0'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) print(left) print(right) res = pd.merge(left, right, on=['key1', 'key2'], how='inner') # default for how='inner' res = pd.merge(left,right) print(res)

当我们设置成inner时,只保留key1和key2相同部分。舍去不相同不部分
当改成outer时
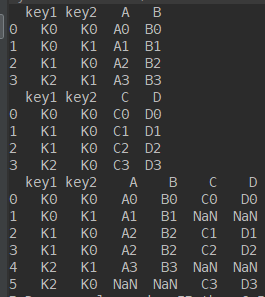
改成right 或者 right也是同理的,是以左边或者右边为基准了
indicator参数
显示合并方式,默认是False , 当传入参数是字符串时。相当于自定义了名称
import pandas as pd df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']}) df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]}) print(df1) print(df2) res = pd.merge(df1, df2, on='col1', how='outer', indicator=True) print(res) # give the indicator a custom name 自定义indicator名称 res = pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column') print(res)

left_index和right_index参数
之前的合并都是按照columns 当设置left_index和right_index参数时,merge()会按照index来合并
import pandas as pd # merged by index left = pd.DataFrame({'A': ['A0', 'A1', 'A2'], 'B': ['B0', 'B1', 'B2']}, index=['K0', 'K1', 'K2']) right = pd.DataFrame({'C': ['C0', 'C2', 'C3'], 'D': ['D0', 'D2', 'D3']}, index=['K0', 'K2', 'K3']) print(left) print(right) # left_index and right_index res = pd.merge(left, right, left_index=True, right_index=True, how='outer') print(res) res = pd.merge(left, right, left_index=True, right_index=True, how='inner') print(res)

suffixes更改合并后的键名称
import pandas as pd # merged by index # handle overlapping boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]}) girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]}) res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='outer') print(res)

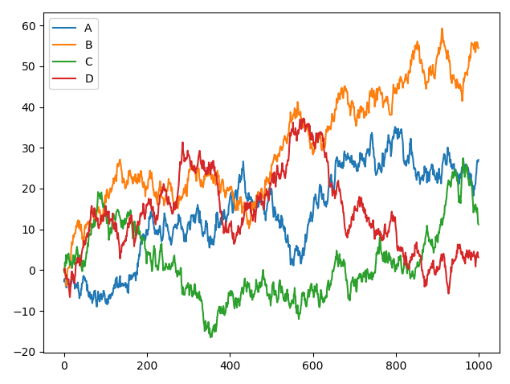
可视化plot
import pandas as pd import numpy as np from matplotlib import pyplot as plt data = pd.DataFrame(np.random.randn(1000,4), columns=list('ABCD')) data = data.cumsum() data.plot() plt.show()
plot.scatter()
import pandas as pd import numpy as np from matplotlib import pyplot as plt data = pd.DataFrame(np.random.randn(1000, 4), index=np.arange(1000), columns=list("ABCD")) data = data.cumsum() # plot methods: # 'bar', 'hist', 'box', 'kde', 'area', scatter', hexbin', 'pie' ax = data.plot.scatter(x='A', y='B', color='DarkBlue', label="Class 1") data.plot.scatter(x='A', y='C', color='LightGreen', label='Class 2', ax=ax) plt.show()
这边把data.plot.scatter中的ax参数设置成了ax,让他们在同一张图中
