结构推理网络:基于场景级与实例级目标检测
原文链接:https://arxiv.org/abs/1807.00119
代码链接:https://github.com/choasup/SIN
Yong Liu, Ruiping Wang, Shiguang Shan, Xilin Chen. Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships. published in CVPR 2018
摘要
上下文信息对视觉识别准确率的提高上有着十分重要的意义。本文中,作者不仅考虑了一张图片中物体的外观特征,同时考虑了图片中的场景信息和物体之间的联系这两种上下文信息。通过将图片中的物体作为图模型中的一个节点,目标物之间的联系作为图模型中的边进而将目标检测问题转变为结构推理的问题。结构推理网络是在经典的检测网络上结合一个用于推理物体状态的图模型结构形成的检测器。该模型结构在PASCAL VOC 和 MS COCO数据集目标检测任务的提升上发挥了很大的作用。
相关工作
现阶段基于卷积神经网络的目标检测大致被分为两大类,一个是基于区域建议框的两阶段检测,另一个是单阶段检测。随着深度学习的发展,两阶段检测逐渐占主要地位,其代表方法有R-CNN, Fast R-CNN, Faster R-CNN等。其第一步是产生大量的候选框,第二步是将将这些框分类为前景和背景。R-CNN是从候选区域中提取出特征并用线性SVM进行分类。
为了提高速度,Fast R-CNN提出了一个ROI-polling操作来从共享卷积层中提取每一个候选框的特征向量。Faster R-CNN将前半部分区域框的生成和后半部分的分类器结合到一个卷积网络中。单阶段的目标检测像YOLO和SSD都能够以一定的准确率实现实时检测。对一张图片中的不同目标进行检测往往被认为是相互独立的任务,虽然上述方法大多对明显的物体分类效果较好,但是对于自身特征模糊的小物体检测效果并不理想。
本文提出的结构将场景信息与物体之间的关系信息进行模型化处理,并根据结构预测出图片中的物体。在深层网络上增加一个图模型结构并通过使用结构推理技术来完成结构预测任务。
本文方法
本文的目标是通过挖掘丰富的上下文信息来改善检测模型。重点考虑了物体之间的联系和场景信息等来进行模型的设计。该模型用于在不同的场景和目标物体之间迭代的传播信息。整体结构框架图如下:
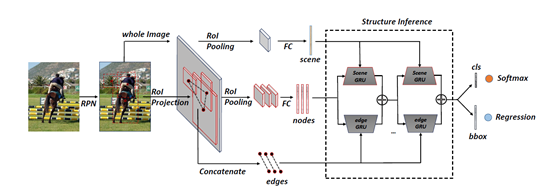
首先,从一张输入图片中得到一定数量的感兴趣区域(ROIs),针对每一个感兴趣区域将其调整成固定大小的特征图,然后通过一个全连接层将其映射为特征向量作为图模型中的一个节点。作者将整张图片进行上述相同的处理操作作为场景信息,然后,将每对感兴趣区域映射变换后进行级联作为图模型里的边元素。结构推理方法用于迭代更新节点的状态,节点的最后一个状态被用来预测相关感兴趣区域的类别及其位置。整个框架在Faster R-CNN的基础上进行改进并进行端到端的迭代训练。
图模型

作者将一副场景图片转变为一个图模型结构,V代表建议框池(proposals),s代表场景信息,E代表每两个节点之间的关系。经过区域建议网络(RPN)后会有成千上完个包含检测目标的区域框(proposals),通过使用非最大值抑制处理进而获得一定数量的感兴趣区域(ROIs)。
信息的传递
对于每个节点来说,相互信息交流的关键是对来自场景和其他节点的信息进行编码处理,由于单个节点会接到不同种类的输入信息,因此,需要设计一种记忆机制的融合函数,可以记录节点自身的细节信息并结合输入的信息从而得到有意义的表述。循环神经网络的一个关键是允许先前的输入信息的记忆以网络内部状态形式存在,进而影响网络的输出。
门循环单元(GRU)是一种轻量级而且高效的循环神经网络。结构图如下。

图中ht代表先前的隐层状态,h~ 代表一个新的隐层状态,ht+1 代表更新的状态,结构中包含两个门,一个为更新门z,用于决定更新的状态是否被新的隐层状态所更新,重置门r用于决定先前的隐层状态是否被忽略。使用的是逻辑sigmoid 函数作为其激活函数。
本文使用GRU将不同的信息编码为物体的状态。对于场景信息的编码,用物体的细节信息初始化GRU,将场景信息作为输入。GRU单元可以忽略与场景无关物体的部分信息,同时使用场景信息来增强部分目标的位置类别等状态。对于来自其他目标物信息的编码,将目标物的细节信息作为GRU的初始化,将来自其他节点的融合信息作为GRU的输入。该GRU会选择相关的信息来更新目标物体的隐层状态。当目标物状态更新,物体之间的联系也会发生改变,随着更新迭代增加,模型也会更加稳固。
结构推理
一系列的场景GRU和边GRU被用来传播来自场景和其他节点的信息。然后节点按如下图进行更新。

上图左侧为scene GRU部分,用目标物的特征作为初始化,用场景信息也就是整张图片的特征图作为输入,通过学习其关键的门函数来选择有效信息对节点进行更新。
右侧为edge GRU部分,用于编码来自其他物体的信息。前提是要先计算得到一个融合的信息,针对每个节点,edge GRU会选择融合信息的一部分来更新该节点,由于不同物体的作用不一样,因此,本文将每对物体映射为一个纯量的权重,代表物体之间的联系。融合信息按如下方式计算得到:
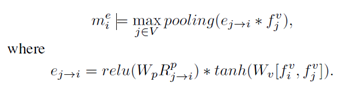

这里不选用均值池化操作的原因是防止大量不相关的ROIs对融合信息产生影响。
R代表视觉信息,将每对RoI的空间位置信息进行变换级联操作。对于一个节点,将来自Scene GRU的输出和来自Edge GRU的输出进行取均值操作,作为该节点的状态。
在接下来的迭代操作中,Scene GRUs 会将更新的后的节点状态作为隐层状态,将固定尺寸的场景特征作为输入,用于计算下一个节点的状态。Edge GRUs会下一对物体的之间的关系信息作为输入,用于计算下一个隐层状态。最后,上述融合后的信息被用来进行目标物体的分类和框回归。
结果
本文结构推理网络在PASCAL VOC 和MS COCOl两个数据集上进行了测试。使用了在ImageNet预训练得到的VGG-16模型,在训练和测试阶段选择128个盒子作为目标物体的建议池(proposals)。将Fastet R-CNN按照原始公开的参数训练作为评判基准。动量,权重衰减,batch size采用与Faster R-CNN相同的设置。在使用VOC2007 trainval 和VOC2012 trainval联合训练并在VOC2007 test 数据集上进行测试时,前80k步采用的学习率为5x10-4 ,在后50k步中,学习率调整为5X10-5 ,在使用VOC2007 trainvaltest 和VOC2012 trainval联合训练并在VOC2012 test 数据集上进行测试时,前100k步采用的学习率为5x10-4 ,在后70k步中,学习率调整为5X10-5 ,在使用COCO train训练并在COCO2015 dev-test 数据集上进行测试时,前350k mini-batches步采用的学习率为5x10-4 ,在后200k mini-batches步中,学习率调整为5X10-5 。
结果如下:

在VOC 2007 test 上得到更高的mAP 76%

在VOC 2012 test上得到mAP为73.1%

在COCO test-dev设置IOU为0.5上实现了23.2的分数
结论
本文提出了结合场景信息和物体之间联系的检测方法。为了更加有效地利用这些信息,提出了结构推理网络。实验表明,在与场景高度相关的类别上检测效果很好。针对物体之间关系的实例级对物体的定位检测发挥了很重要的作用。
参考文献
[1] B. Alexe, N. Heess, Y. W. Teh, and V. Ferrari. Searching for objects driven by context. In NIPS, 2012.2