
论文原址:https://arxiv.org/abs/1703.10295
github:https://github.com/lachlants/denet
摘要
本文重新定义了目标检测,将其定义为用于评估一个规模较大但较为稀疏的的边界框依赖性的概率分布。随后,作者确定了一个评价稀疏分布的机制,Directed Sparse Sampling并将其应用至end-to-end的检测模型当中。该方法扩展了以往SOTA检测模型,并提高了eval 速率同时减少了人工设计。该方法存在两个创新点, I: 基于角点的感兴趣区域评估器 II: 基于CNNN模型的反卷积结构。最终得到的模型,去掉了人为设计reference boxes的工作量,进而对场景进行适应。
介绍
前向神经网络在随机梯度下降的优化方法条件下,通过随机初始化可以得到很好的收敛性能,同时,特定设计的网络结构通过训练机制可以很好的提高模型对未遇见的数据的泛化能力。许多方法介绍其对图像中轴对齐目标实例的回归与分类的能力。
本文的重点不是在于提高模型的准确率,而是提高模型的检测性能。本文贡献如下:
I. 一种改进的理论用于解释当代的检测模型,并设计了一个通用的框架进行描述,如Directed Sparse Sampling
II. 创新的设计了一种更快的感兴趣区域评估器,其并不需要手工设计参考框。
III. 创新性的进行反卷积应用并提高了evaluation的速度。
IV. 本文方法的六点强化,在较广的标准中取得较好的检测性能。
V. 基于 Theano框架开源了代码。
相关工作
在基于区域的卷积检测模型中。一张图片首先经过Selective search ,RPN等region proposal算法。该算法产生的感兴趣区域,然后将其进行rescale到固定维度后送入到基于CNN的分类器中。CNN对感兴趣目标区域赋一个概率或者一个NULL的类别(不存在的情况下),并通过线性回归得到一个改进的边界框。该方法虽然准确率较高但需要占用较大的计算量(Multiple full CNN evaluations 及预处理) 。CNN大部分的计算量发生在前几层。Fast R-CNN通过应用一个较浅层的CNN作用到图像中,然后对每个区域,提取其固定尺寸的特征用于最后的分类。Faster R-CNN区域建议算法结合到CNN中形成了end-to-end的方法,改进了时间效率,同时,region proposal 与分类共享相似的特征。然而,基于区域的CNN检测算法仍无法满足实时的性能要求。
在YOLO中,不适用基于区域的region proposal方法,而是选择一个预定义的矩形格子的检测器。实际上,YOLO是将区域分类问题融合到RPN当中。基于该方法,CNN一次就可以产生所有detector的输出,节省了大量的训练及测试时间。SSD通过模型设计及改进的训练方法,使得到的结果与基于区域的方法相当。SSD中根据场景认为的设计一些区域来包含图像中的目标,这点与Faster R-CNN的区域建议框相类似。而本文认为,手工设计限制了不同问题的适应能力。
上述方法的主要区别在于模型如何对待及区分待分类的区域。基于R-CNN的方法通过一些预处理算法采样稀疏的区域,并对这些区域进行标准化处理。而基于YOLO的方法通过手工预定义的检测器进行密集的采样,同时,并未对其区域并未进行标准化处理。密集的方法与当代的实现相适应,相比,稀疏采样在时间上有一定的优势。然而,本文提出了一种新的方法,该方法对于基于区域的稀疏方法缓解训练,使具有场景适应能力,并提高了分类的准确率。而对于非基于区域的模型提高了其训练及evaluate的速度。
Probabilistic Object Detection
本文针对多分类的目标检测问题简历概率模型,首先评估如下概率分布。![]() ,其中
,其中![]() ,一个随机变量,一个类别为
,一个随机变量,一个类别为![]() 或者NULL类别的概率,该实例由
或者NULL类别的概率,该实例由![]() 产生,其中I为输入图片。上述公式存在一个前提条件就是,每个边框中一个类别只有一个实例占据边框。因此上述定义并不使用据实例级别的处理。但可以作为比如NMS算法的输入等。
产生,其中I为输入图片。上述公式存在一个前提条件就是,每个边框中一个类别只有一个实例占据边框。因此上述定义并不使用据实例级别的处理。但可以作为比如NMS算法的输入等。
给定一个合适的神经网络设计,![]() 可以通过一个给定边界框标记的训练数据集进行评估。然而单独边框的数量由
可以通过一个给定边界框标记的训练数据集进行评估。然而单独边框的数量由![]() 确定,其中(X,Y)代表图片中的位置,(W,H)表示边框维度的范围。这种原始的方法变得十分棘手。在ImageNet数据集中,1000个类别,224x224的图像,包含有效的边框基于上述分布大于为629x1e9个数值或者以32位浮点精度存储2.5TB的计算量。这对于当代硬件是一个十分棘手的问题。
确定,其中(X,Y)代表图片中的位置,(W,H)表示边框维度的范围。这种原始的方法变得十分棘手。在ImageNet数据集中,1000个类别,224x224的图像,包含有效的边框基于上述分布大于为629x1e9个数值或者以32位浮点精度存储2.5TB的计算量。这对于当代硬件是一个十分棘手的问题。
在定位准确性可接受的损失的情况下,对输出的边界框进行下采样是一种有效的方法。比如,通过精心的数据依赖性的手工设计,基于Faster R-CNN及YOLO的方法可以将分布降采样到1e4到1e5个边框的级别。这些框通过对一个局部区域更可能为边框的部分进行线性回归来进行增强。
相比于大规模的下采样,本文利用一种现象,由于模糊等因素,本文期望边框中很小的子集包含类别实例而不是NULL。因此,本文建立了一一种基于最强回归能力的CNN用于评估在实时的操作唤醒中的高度稀疏分布![]() 。
。
Directed Sparse Sampling (DSS)
本文使用Directed Sparse Sampling 来表示应用于两阶段CNN的联合优化方法。其中一个stage用于评估用户定义的感兴趣的值肯能发生的位置。另一个stage用于稀疏的区分定义的值,比如,基于R-CNN的检测模型,对更可能包含非NULL类别的框进行评估,然后,对这些边框进行分类。
Corner-based RoI Detector
这里介绍了用于高效感兴趣区域评估的边框角点评估的概念。通过评估一张包含实例的图片中每个像素存在四个角点类型之一的概率来实现。![]() ,变量t为一个二值变量代表角点类型之一存在。其代表输入图片中位置(x,y)有出现角点中一个类型
,变量t为一个二值变量代表角点类型之一存在。其代表输入图片中位置(x,y)有出现角点中一个类型![]() 的概率。本文认为由于自然中的移动不变性的原因,可以通过在数据集上进行训练得到的一个标准的CNN对角点的分布进行评估。
的概率。本文认为由于自然中的移动不变性的原因,可以通过在数据集上进行训练得到的一个标准的CNN对角点的分布进行评估。
有了定义后的角点分布,通过对边框中的每个角点使用朴素贝叶斯分类器来评估边框B中包含实例的概率。
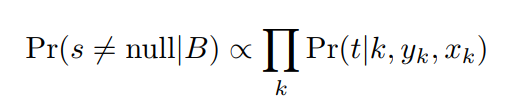
其中,![]() ,表示边界框的位置与每个角点类型k的联系。为方便,定义了一个具有最大非NULL类别概率
,表示边界框的位置与每个角点类型k的联系。为方便,定义了一个具有最大非NULL类别概率![]() 的NXN的边界框作为采样边界框作为采样边框
的NXN的边界框作为采样边界框作为采样边框![]() 。变量N参考了计算以及内存需求模型可以检测的最大的数量。当潜在的非NULL边框建立后。从corner detector得到的预定义长度的特征向量传送到最终的分类阶段。因此,最终分类阶段的函数形式为
。变量N参考了计算以及内存需求模型可以检测的最大的数量。当潜在的非NULL边框建立后。从corner detector得到的预定义长度的特征向量传送到最终的分类阶段。因此,最终分类阶段的函数形式为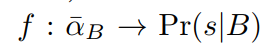
其中,![]() 为单独由采样边框
为单独由采样边框![]() 定义的特征向量。该特征与每个边框是相互独立的,这很重要。否则,如果
定义的特征向量。该特征与每个边框是相互独立的,这很重要。否则,如果![]() 是相同的,则分类器将得不到任何区分边界框之间的信息。构建特征向量的方法仍然值得讨论,本文通过在预定义的位置处将最近的相邻采样特征进行串联。特征向量中忽略了边框的中心位置,因此,分类器可能会分不清图像的偏移。
是相同的,则分类器将得不到任何区分边界框之间的信息。构建特征向量的方法仍然值得讨论,本文通过在预定义的位置处将最近的相邻采样特征进行串联。特征向量中忽略了边框的中心位置,因此,分类器可能会分不清图像的偏移。
Training
训练时,网络首先,初始化前向传播产生采样边框Bs。然后,本文结合ground truth boxes对采样框Bs进行增强,进而随机生成样本。然后,对增强的采样边框样本传播其![]() 用于生成最终的分类分布
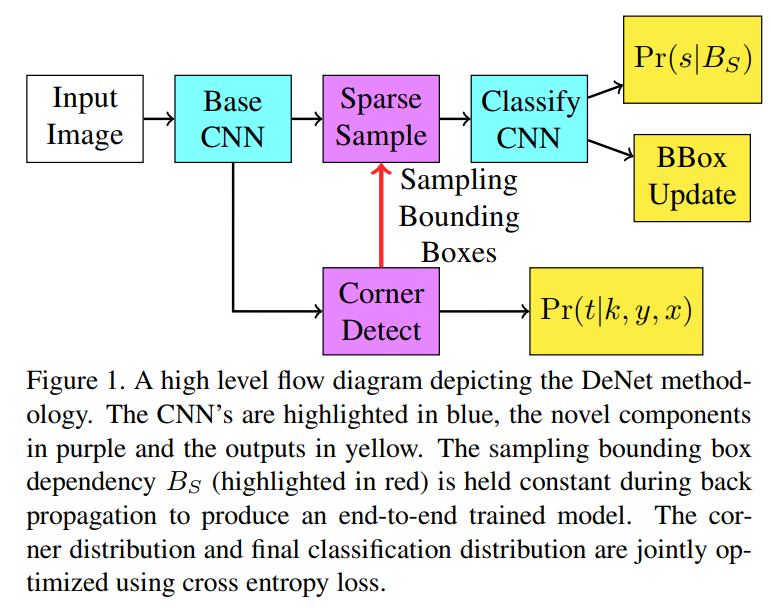
用于生成最终的分类分布![]() ,同时更新边框的参数。在进行梯度下降时,为了能够进行end -to -end训练,采样边框Bs保持固定。因此,可以结合边框的分类以及评估任务对角点检测网络进行优化。在基于SGD的反向传播过程中,前向传播算法是一个十分重要的预处理过程。DeNet网络并未引入任何时间上的损失。流程如下
,同时更新边框的参数。在进行梯度下降时,为了能够进行end -to -end训练,采样边框Bs保持固定。因此,可以结合边框的分类以及评估任务对角点检测网络进行优化。在基于SGD的反向传播过程中,前向传播算法是一个十分重要的预处理过程。DeNet网络并未引入任何时间上的损失。流程如下
DeNet模型同时优化角点概率分布,最后的分类分布及边框回归,损失如下
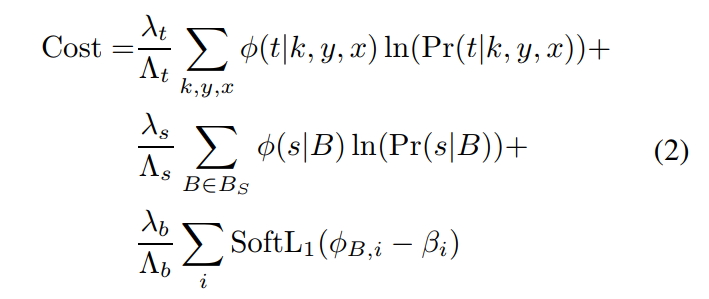
![]() 表示corner 及 分类分布的ground truth,
表示corner 及 分类分布的ground truth,![]() 表示边框的ground truth。
表示边框的ground truth。![]() ,为人为定义的常量,用于控制上述各个成分的重要度。
,为人为定义的常量,用于控制上述各个成分的重要度。![]() 将每个成分标准化为1。角点分布
将每个成分标准化为1。角点分布![]() ,将每个ground truth 的实例角点映射至corner map中的一个位置上,超过边界的角点被舍弃。检测分布
,将每个ground truth 的实例角点映射至corner map中的一个位置上,超过边界的角点被舍弃。检测分布![]() 通过计算采样边框Bs及groundtruth box之间的IoU得到。通常,回归目标边框
通过计算采样边框Bs及groundtruth box之间的IoU得到。通常,回归目标边框![]() 通过选择IoU最大的ground truth来确定。
通过选择IoU最大的ground truth来确定。
检测模型
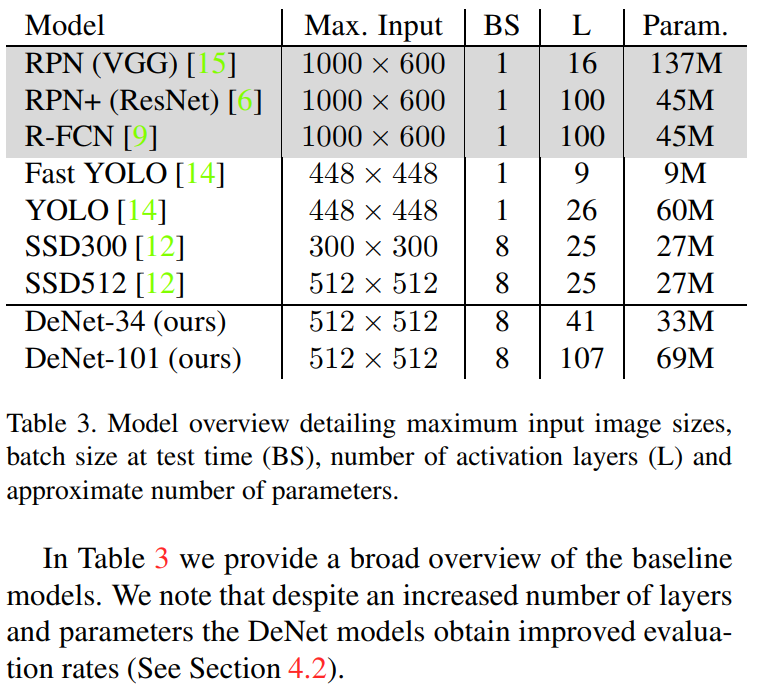
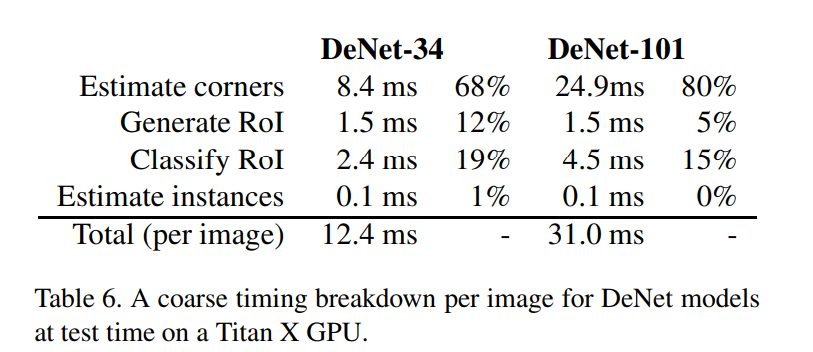
残差神经网络已被证实可以在大规模的数据集上表现较强的回归能力。本文分别选择ResNet-34,ResNet101作为base来搭建DeNet-34及DeNet-101两种模型。对每个基本模型,调整输入大小为512x512,移除最后的均值池化及全连接层,同时在角点检测器后增加了两个反卷积层。角点检测器用于生成交角点分布,同时,通过在每个位置学习一个Fs特征的映射来产生一个特征采样map。反卷积层引入在base model中丢失的空间信息。因此,feature map及角点分布可以在更大的空间分辨率上进行定义计算。Corner detector 后面接着是稀疏层。用于观察由corner detector检测出的角点,同时生成一系列采样边框即RoIs。RoI用于产生来自feature sampling maps的NxN的特征向量。本文从4.2M个有效边框中采样NxN个白内框。通过提取与7x7网格相关的最相近的采样特征即边框的宽及高来构建特征向量。生成一个7x7xFs+2个值的特征向量。作为边框角点最相邻的特征采样maps有相同的大小的分辨率,因此,使用相邻采样也足够。最后,特征向量传入到一个较低的全连接网络中用于产生最终的分类,并对每个采样RoI微调边框。表一表二代表新添加的层,如下

Conv: 一系列2D卷积作用在输入激活层中。filter 权重通过正态分布进行初始化![]() ,其中,nf代表filters的数量(nx,ny)代表其空间外形。每个卷积后面接着BN,ReLU。
,其中,nf代表filters的数量(nx,ny)代表其空间外形。每个卷积后面接着BN,ReLU。
Deconv: 应用一个可学习的反卷积(上采样)操作,后面接着ReLU激活。其等价于放大了两个维度然后应用一个卷积层。
Corner: 基于softmax函数来评估一个角点分布,同时产生一个采样feature map。
Sparse:根据角点分布顶一个采样边框同时从采样feature maps上得到一个固定的采样特征。
Classifier: 基于softmax函数将激活层映射为目标概率分布同时产生边框目标。
Skip Layer Variant
将DeNet模型增加一个跳跃结构。本文中,将base 模型的最后一层输出与Deconv层进行连接,二者具有相同的空间维度。每个skip 层执行一种线性映射,在激活层 之前将二者的feature maps进行相加操作。
Wide Variant
通过另外的Deconv及Skip层将一个128x128的空间分辨率用于角点及特征采样maps。将N增加至48产生2304个RoIs。该方法由于增加了CPU的分类负担进而造成了一定时间上的损耗。
训练细节
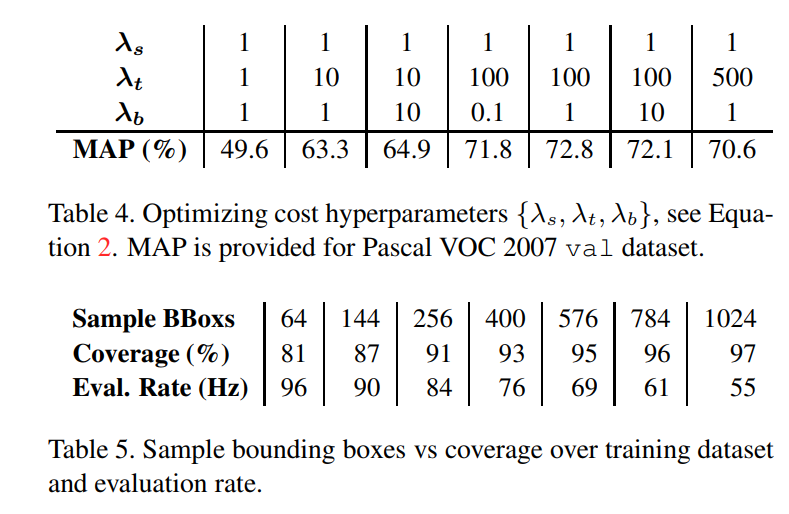
优化方法:Nesterov style SGD initial learning rate: 0.1 momentum: 0.9 weight decay: 0.0001 batch size: 128
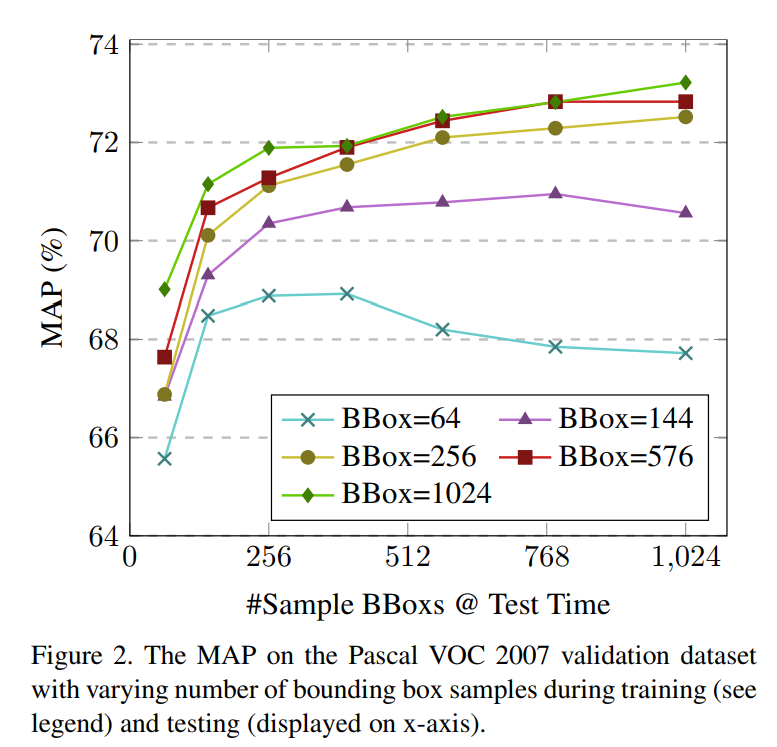
Identifying Sampling Bounding Boxes(RoIs)
用于快速搜索非NULL边框中角点分布的简便算法
1. 搜索关于角点![]()
![]() 的角点分布,
的角点分布,![]()
2. 对于每个角点类型,选择可能性最大的M个角点![]()
3. 通过匹配CM中的top-left及bottom-right角点来产生一系列独立边框。
4. 通过最上面的等式1计算得到每个边框为非NULL的概率。
5. 重复2,3操作作用于top-right,bootom-left角点。
6. 通过概率对边框进行排序,并选择N^2个最大的用于生成采样边框Bs。
由于大量角点落于步骤1中,因此,相比传统的检测所有可能的边界框,本文方法速度更快。
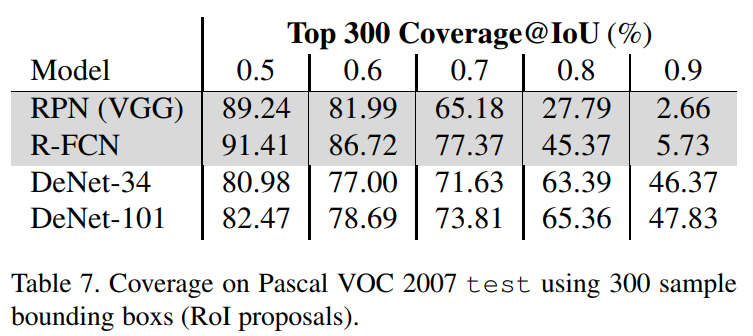
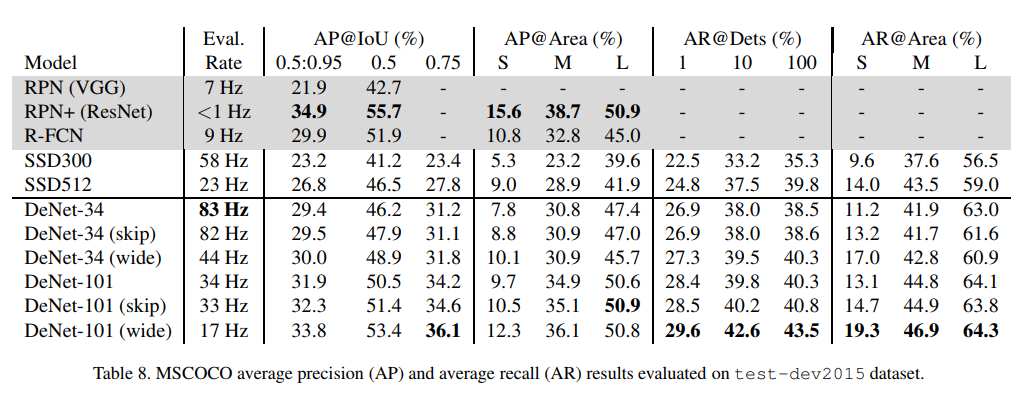
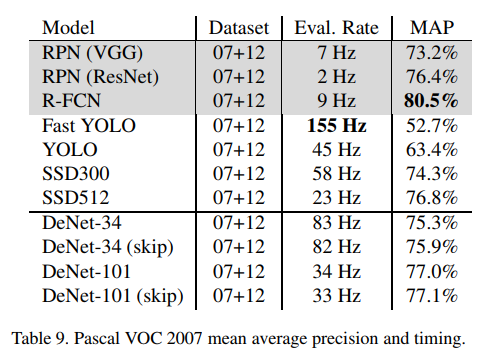
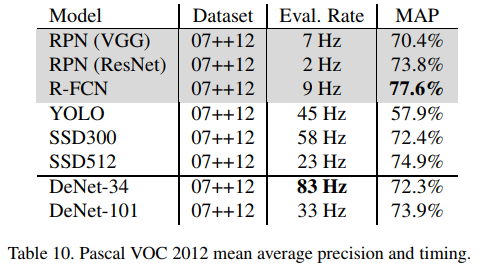
Results
Reference
[1] M. Everingham, L. Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. Int. J. Comput. Vision, 88(2):303–338, June 2010. 2, 3, 7, 8
[2] G. Ghiasi and C. C. Fowlkes. Laplacian pyramid reconstruction and refinement for semantic segmentation. In European Conference on Computer Vision, pages 519–534. Springer, 2016. 4
[3] R. Girshick. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, pages 1440–1448, 2015. 2, 3
[4] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Regionbased convolutional networks for accurate object detection and segmentation. IEEE transactions on pattern analysis and machine intelligence, 38(1):142–158, 2016. 1, 2