
论文原址:https://arxiv.org/pdf/1809.08545.pdf
github:https://github.com/yihui-he/KL-Loss
摘要
大规模的目标检测数据集在进行ground truth 框标记时仍存在这歧义,本文提出新的边界框的回归损失针对边界框的移动及位置方差进行学习,此方法在不增加计算量的基础上提高不同结构定位的准确性。而学习到的位置变化用于在进行NMS处理时合并两个相邻的边界框。
介绍
在大规模目标检测数据集中,一些场景下框的标记是存在歧义的,十分不利于边界框的标记及边界框回归函数的学习。
图下图(a,c),一些框的标记并不是很准确。当物体被遮挡时,边界框更不清晰,如下图(d)所示。
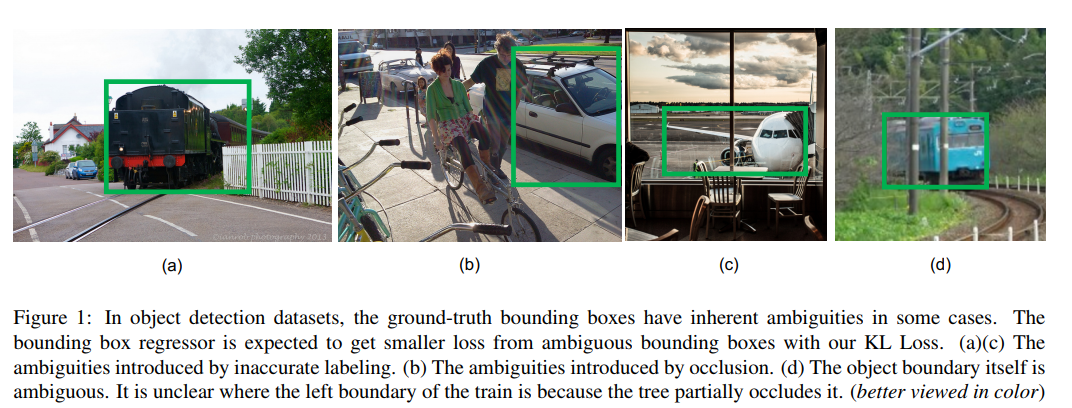
目标检测包含分类及定位是一个多任务的学习问题。Faster R-CNN,Cascade R-CNN及Mask R-CNN依靠边界框回归来进行目标定位。传统的基于Smooth L1损失的边界框回归损失并未考虑ground truth 模糊的情形。一般来说分类的分数越高,其边界框的回归应更为准确,然而,这种情况很少,如下图所示。

本文提出了KL损失用于解决上述问题,本文新提出的边界框损失-KL损失,可以同时学习边界框的回归以及定位的不确定性。为了捕捉边界框预测的不确定性,首先将边界框的预测及ground truth 框分别看作时高斯分布及Dirac delta函数。则新定义的回归损失可以看作是预测分布及真实分布之间的KL散度。KL损失有三个优点:
(1)可以成功步骤数据集中的歧义现象。边界框回归器从有歧义的边界框中得到更小的损失。
(2)学习到的方差在后处理阶段十分有用,本文提出的variance voting通过在NMS时利用学习到的方差作为相邻框的权值来vote出候选框的位置。
(3)学习到的概率分布时具有可解释性的。其影响边界框不确定性的等级。在自动驾驶及机器人上十分有帮助。
相关工作
单阶段检测虽然高效,但是state-of-the-art仍基于双阶段检测。双阶段首先会生成proposal,进而产生大量重叠的边界框,标准的NMS会将类别分数低的,但是较为准确的框给剔除掉。本文的var voting尝试利用相邻的边界框来进行更好的定位。
目标检测的损失函数,UnitBox引入IoU loss函数用于边界框的预测,Focal Loss通过修改标准的交叉熵损失用于处理类别不平衡问题,对于容易分类的样本其权重更低。KL损失可以在训练时调整每个物体的边界方差,可以学习到更多差异的特征。
soft NMS及learning NMS用于改进NMS,相比删除所有类别分数较低的边界框,soft NMS将衰减其他相邻框的检测分数来作为与更高分数框重叠率的连续函数,leaning NMS,提出学习一个新的网络只对boxes及分类分数进行NMS处理。
边界框的增强,MR-CNN首次提出在迭代定位中将框进行merge操作。IoU-Net提出学习预测框与ground truth框之间的IoU,然后,根据学习到的IoU应用IoU-NMS,与IoU-Net不同,本文概率分布的角度对位置方差进行单独学习。因此,本文可以对四个坐标的方差进行单独的学习,而不只是IoU。var voting 通过由KL损失学习到的相邻边界框的方差来对选择的框产生新的位置。
方法
边界框参数化:基于两阶段的检测网络如:Faster R-CNN,Mask R-CNN,如下图所示,本文提出独立的对框的边界进行回归,(x1,x2,x3,x4)代表边界框的4维数组。不同于R-CNN使用的(x,y,w,h)本文使用参数化的(x1,y1,x2,y2),如下

本文重点评估位置的置信度。本文预测一个位置的分布,而不是边界框的位置,分布和混合高斯或者高斯矩阵一样复杂没本文假设四个坐标分布独立,定义了单方差的高斯来进行简化。如下

上述分布由一个全连接层预测得到。ground truth 边界框可以看作![]() 的高斯分布,为狄利克雷 函数,如下
的高斯分布,为狄利克雷 函数,如下

基于KL损失的边界框回归:本文物体定位的目标是通过在N个样本最小化![]() 与
与![]() 之间的KL散度来评估
之间的KL散度来评估![]() ,如下
,如下
![]()
基于KL-损失的边界框回归如下,分类损失不变。

如下图所示,当预测的x_e不准确时,期望网络可以预测更大的方差,进而可以是Lreg拉低。
![]() 此部分与参数
此部分与参数 无关,因此,最终得到如下等式,
无关,因此,最终得到如下等式,
![]()

当方差设置为1时,KL损失退化为标准的Euclidean损失,如下

分别对xe及方差求偏导,得到如下等式,由于方差在分母的位置,因此,在刚开始训练时梯度可能会发生弥散,为了避免这种情况,本文对方差做了log变换,![]() ,则变为如下中间等式。又继续调整等式使其具有smooth L1损失的形式,进而
,则变为如下中间等式。又继续调整等式使其具有smooth L1损失的形式,进而![]() 等式如右下侧。
等式如右下侧。


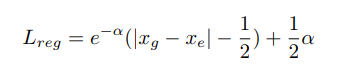
用随机高斯分布对FC层进行初始化,标准偏差及均值分别设置为0.0001及0,因此,KL损失在训练的刚开始时与smooth L1损失相似。
variance voting:根据学习到的相邻框之间的方差来选出候选边界框的位置。作者通过标准NMS或者soft NMS来挑选边界框的位置。挑选出具有最大分数的边界框b,![]() ,其新位置根据自身及相邻边界框计算得到。手Soft-NMS启发,对距离近且较为确定的边界框给其更大的权重,如,x1作为一个坐标,xi作为第i个框的坐标,新坐标的计算公式如下,
,其新位置根据自身及相邻边界框计算得到。手Soft-NMS启发,对距离近且较为确定的边界框给其更大的权重,如,x1作为一个坐标,xi作为第i个框的坐标,新坐标的计算公式如下,

在voting过程中,存在两种相邻边界框的权重较低,一个是具有较大方差的框,另一个是与选定框的IoU值较小。由于具有低分数的框可能更准确,因此,类别分数并未引入到voting中。
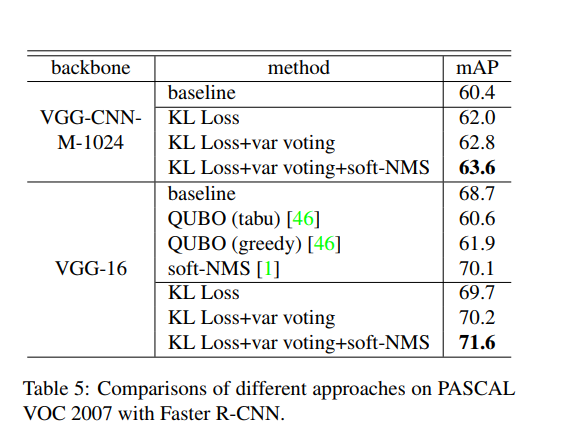
实验




Reference
[1] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Soft-nms – improving object detection with one line of code. In Computer Vision (ICCV), 2017 IEEE International Conference on, pages 5562–5570. IEEE, 2017. 2, 4, 7, 8
[2] Z. Cai and N. Vasconcelos. Cascade r-cnn: Delving into high quality object detection. arXiv preprint arXiv:1712.00726, 2017. 1, 2
[3] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer. cudnn: Efficient primitives for deep learning. arXiv preprint arXiv:1410.0759, 2014. 6
[4] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully convolutional networks. In Advances in neural information processing systems, pages 379–387, 2016. 2