
论文源址:https://arxiv.org/abs/1612.08242
代码:https://github.com/longcw/yolo2-pytorch
摘要
本文提出YOLO9000可以检测9000多个类别。改进的YOLOv2在VOC与COCO数据集上表现较好。通过使用多尺寸的训练方法,同一个YOLOv2模型可以在多尺寸上进行实现,准确率与速度上得到很好的权衡。超过了基于ResNet的Faster R-CNN和SSD。提出了标检测及分类的联合训练方法。基于此方法,同时,在COCO检测数据集及ImageNet分类数据集上训练YOLO9000,联合训练同时可以让YOLO9000对没有标记的目标进行检测。
介绍
目标检测的常规目标:快,准确,识别较多类别的物体。大多数基于DNN的目标检测方法仍限制于小样本的目标物体检测。与分类及标记等其他任务相比,目标检测的数据集数量还是有限。检测数据标签的制作要比分类任务的难得多,因此,检测数据集得规模无法像分类数据集那样。
本文提出了基于大量分类数据集得基础上进行扩展应用到检测系统中。利用分类中得分层视野可以将不同得数据集进行组合。
提出了联合训练算法可以基于分类和检测数据同时训练object detectors。利用标记得图像进行精确定位的学习,同时利用分类图片增加模型的鲁棒性。
首先改进了基础YOLO检测系统为YOLOv2,然后使用数据集融合及联合训练算法训练得到可以检测9000个类别的模型。
Better
YOLOv1存在大量的不足。与Fast R-CNN相比YOLOv1存在大量的定位误差,同时,相比基于region-proposal的方法,YOLOv1的召回率过低。因此,本文致力于在保持分类准确率的基础上提高召回率及精确定位的增强。
计算机视觉的相关网络逐渐趋于更大,更深。更好的检测效果依赖于训练更大的网络或者多个模型的组合。本文致力于实现快速的进行精准检测。本文并未增大网络的尺寸,相反,对网络进行简化更容易学习表征信息。本文尝试的改进方法如下。
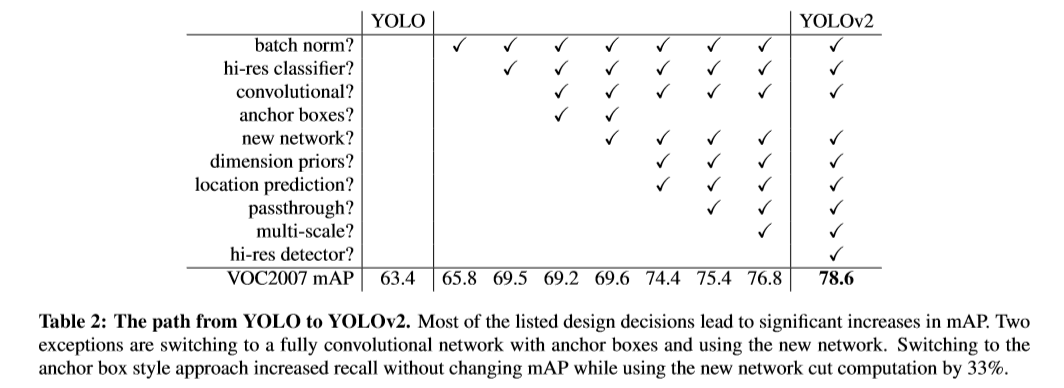
Batch Normalization
BN可以在没有添加其他正则方法的条件下有效的加快收敛。在YOLO的卷积层中添加BN可以提高2%的mAP,同时,BN可以对网络正则化,移除dropout同时使网络不发生过拟合。
High Resolution Classifier
以前的分类器大多在ImageNet上进行预训练,自AlexNet开始,输入图片大小小于256x256。YOLOv1的输入尺寸为224x224,然后增加至448用于检测。因此,网络需要进行目标检测学习的同时调整适应新的输入分辨率。
YOLOv2首先在ImageNet上微调分类网路,输入大小为448x448,迭代10次。因此,网络可以在此时间段针对更高分辨率的输入调整卷积核。最后微调网络用于检测。高分辨率的输入提高4%的mAP。
Convolutional With Anchor Boxes
YOLOv1直接用全连接层预测边界框的坐标,而Faster R-CNN通过手动挑选的方式预测边界框。仅使用只有卷积层的RPN预测anchor boxes的偏移和confidence。由于预测层为卷积层,因此,RPN预测feature map中每个位置处的偏移。对偏移量进行预测而不是直接预测坐标简化了问题,同时,使网络更易于学习。
本文将YOLO的全连接层移除,使用anchor boxes 预测边界框。首先,移除一个pooling层,使卷积层输出的feature map分辨率更高。同时,调整网络的输入为416x416而不是448x448。从而fetaure map中会产生奇数个位置,从而只有一个中心单元。对于目标,尤其是大目标,通常会占据图像的中心,因此,最好有一个中心位置对目标进行预测,而不是附近的四个点。YOLO卷积层下采样率为32,因此,对于416x416的输入,输出的feature map最终为13x13。
当进行anchor boxes移动时,在空间位置上结构类别预测机制,预测每个anchor box的类别和对象。对于目标的预测仍然是ground truth 与proposed boxes的IOU,类别预测是存在目标物条件下该类别的条件概率。
使用anchor boxes会使准确率小幅度降低。YOLO没张图只预测98个boxes,而本文超过1000个boxes。使用anchor前后,map69.5变为69.2,recall由81%提升为88%因此,有很大的提升空间。
Dimension Clusters
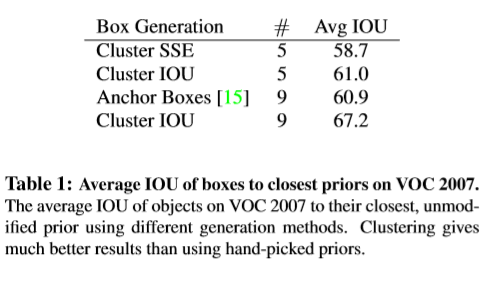
当使用anchor时遇到两个问题。box的维度很难进行手工挑选。 网络可以学习适当地调整boxes,但是如果人为的挑选一些更好的先验,则对网络来说更容易学习到一个好的预测。本文并未手工挑选,而是采用k-means聚类自动的挑选较好的box作为先验。如果使用欧几里得距离作为标准的k-means则大框产生的误差要比小的大很多。而本文主要时想获得好的IOU分数,而与框的大小无关。因此,基于下式进行距离计算。
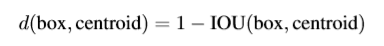
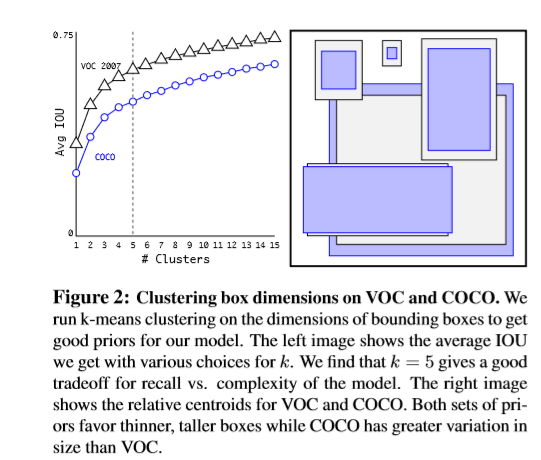
本文选用不同的k值进行k-means运算。实验发现k=5时,模型的复杂度较低,且有一个较好的召回率。聚类得到的中心与手工挑选的先验明显不同。聚类后的box更短,更高。
Direct location prediction
当YOLO使用anchor 的另一个问题是,早期迭代过程中模型的不稳定性,大部分来自于box位置的预测。基于region proposal预测值tx,ty,则坐标中心(x,y)按如下方式计算。
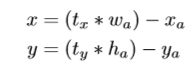
上述式子无条件限制,因此,可以不开率预测盒子的位置,任何anchor box可以在图像上的任意一点结束 。由于随机初始化,因此,模型需要很长时间才可以稳定并能合理的预测位移。
本文并未预测位移,而是遵循YOLO,预测相对于网络单元相对位置的坐标。同时,通过使用逻辑回归将网络的预测即距离ground truth的边界限定为0至1。每个单元网络预测5个边界框。对于每个边界框,网络预测5个坐标,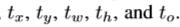 ,如果单元格偏移图像的左上角为(cx,cy)同时,先验框的宽和高为pw,ph,则对应的最终框预测值为
,如果单元格偏移图像的左上角为(cx,cy)同时,先验框的宽和高为pw,ph,则对应的最终框预测值为
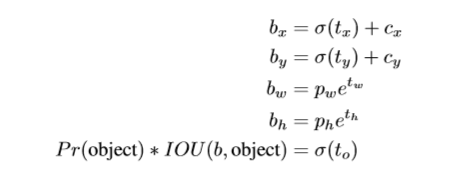
通过聚类和边界框中心位置的预测,提升mAP5%。
Fine-Grained Features
改造过的YOLO在13x13的feature map上进行检测。 对较大的物体该尺寸足够,但细粒度特征更利于小物体的定位。Faster R-CNN与SSD在网络的feature map上运行RPN从而得到一系列分辨率的feature map。本文只添加了一个直通层,从前层网络中得到26x26的feature map。直通层直接将高分辨率的feature map与低分辨率的feature map按通道进行相邻像素拼接。从而将26x26x512的feature map变为13x13x2048的feature map从而可以与原始的feature map进行拼接。提升了1%的效果。
Multi-Scale Training
原始的YOLO采用448x448的输入分辨率,添加了anchor box后,改变分辨率为416x416,然而,YOLOv2只使用了卷积层和pooling层,可以任意改变输入的尺寸大小。对YOLOv2进行训练使模型对不同的输入具有鲁棒性。
相对于固定尺寸输入,本文每迭代几次进行网络的变化。每进行10个批次,网络随机选择一个新的图片尺寸大小。由于,网络下采样率为32,因此,选择的输入大小都为32的倍数。


Faster
本文两个目标:(1)准确率高(2)速度快 。大多数检测网络基于VGG-16进行特征提取,VGG-16准确分类准确率高,但相对复杂。处理一张224x224的输入图片需要进行30.69billion次浮点运算。YOLO基于GoogleNet结构,比VGG-16要快很多,但准确率要比VGG-16要低一些。
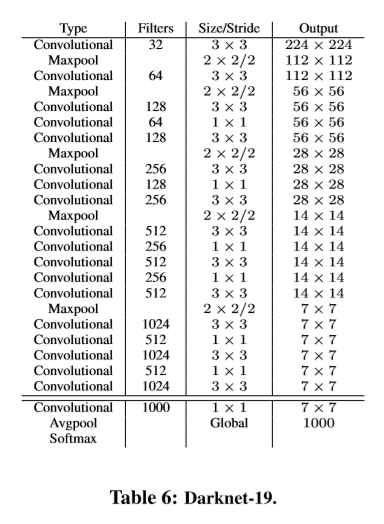
Darknet-19: 本文提出新的分类网络用于YOLOv2,使用大多数为3x3的卷积核,同时每次池化操作后将通道数进行加倍。并借鉴NIN中的全局平均池化操作。将1x1的卷积核置于3x3的卷积核之间用于特征压缩。同时,使用BN稳定训练,加速模型的收敛并对模型进行正则化。
本文最终模型Darknet-19有19层卷积层核5层最大池化层,结构如下。
training for classification: 在标准ImageNet(1000个类别)上进行训练160轮,基于SGD优化算法,学习率为0.1,polynomial 衰减率为4,权重衰减为0.0005,动量为0.9.先在224x224得输入上进行训练,然后再448x448输入上进行训练。
training for detection:移除最后一个卷积层,然后接上三个3x3x1024的卷积层,最后接一个1x1xnum_of_outputs的卷积层。对于VOC包含20个类别,每个图片预测5个box,每个box预测5个值,因此num_of_outputs为5*(20+5)=125,同时添加了一个直通层用于细粒度特征的分析。
Stronger
本文提出了检测与分类的联合训练机制,本文使用于标记检测的图像来学习有关明确检测的信息,像边界框的坐标及对常见目标进行分类。通过带有标记的图片来增大检测的类别数。
在训练时,将检测与分类数据进行混合。当遇到用于检测标记的图像时,可以通过反向传播来优化YOLOv2的整体损失函数。而遇见分类的图片时,只能优化分类部分的结构。这种方法存在一个挑战,用于检测的数据集的类别比较常见,数量较少,而用于分类的数据集的类别数目要多很多。ImageNet中包含一百多个狗的品种。
大多数分类方法采用softmax得到所有类别的概率分布。而基于softmax的一个前提假设是类别之间是相互独立的。而混合数据集中的类别并不是相互独立的比如说两个类别“狗”,“泰迪犬”,但是相关的。本文通过使用一个多标记模型,排除互斥这个条件。此方法忽略了数据的所有结构信息,比如,COCO数据集的所有类别都是互斥的。
多层分类
ImageNet的标记来自WordNet,一种用于构建概念及相关性的语言数据集。在WordNet中,不同种类的犬都为归为一类。大多数分类来说,数据的标签结构是已知的,而对于组合数据集来说,结构信息更加重要。
WordNet的结构为一个有向图而不是一棵树,因为语言结构是复杂的。比如,狗即是犬又是家畜,同时在WordNet中出现。本文并未使用完整的图结构,而是从ImageNet中的概念构建出一个分层树进而简化问题。
为了构建树,检查ImageNet中的名词,并查看他们从WordNet 图到根节点的路径,许多同义词通过图形的路径只有一条,首先,先将这些路径添加到树中,然后迭代的查看剩下的名词,尽可能少的添加树的生长路径。因此,如果一个名词存在两个路径,选择较短的路径添加到树中。
最终得到了WordTree,一个基于视觉概念的分层模型。预测树中每个节点处的条件概率,从而获得给定同义词的下位词的同义词的概率。如下,在terrier节点处的预测。

如果想要计算特定节点的绝对概率,只需要按照树中到根节点的路径同时,乘上一个条件概率,按如下方式计算。

为了验证此方法,使用ImageNet 1000个类别建立WordTree训练Darknet-19的模型。为了建立WordTree1k,添加了1000到1369扩展标签空间的所有中间节点。训练期间,将gtound truth的标记接到树上,比如如果一副图像被标记为秋田犬,则他也会得到一个狗和哺乳动物的标记。为了计算条件概率,模型预测了带有1369个值得向量,并且我们计算了所有同义词的softmax值,如图。虽然可能对狗品种无法进行精确分类,但仍会以一个高置信度返回狗这个类别。

此方法也同样适用于检测。将假设每个图片都存在目标这个假设排除。使用YOLOv2得目标预测器获得概率值。
检测器预测一个边界框及一个树得概率。遍历树,在每次分离时,选择置信度最高得路径。直到达到某个阈值,预测出目标的类别。
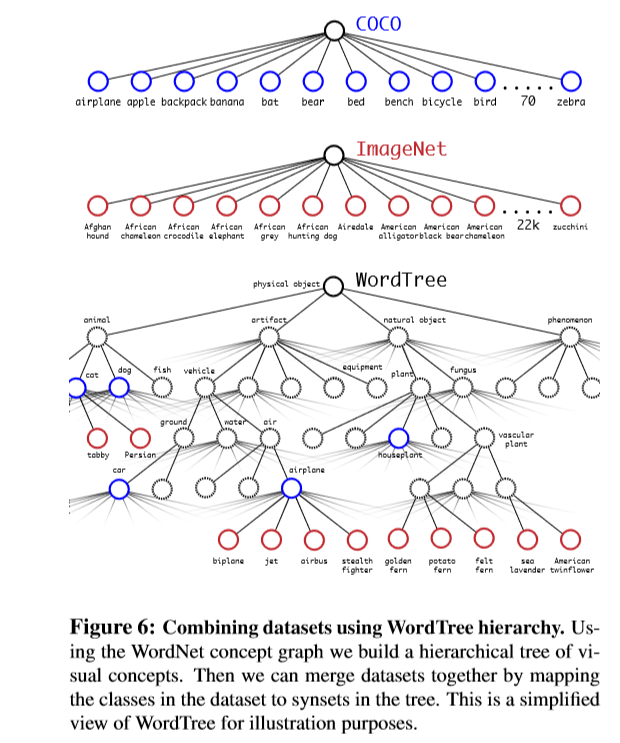
Dataset combination with WordTree
使用WordTree以合理的方式将多个数据集组合在一起,将数据集中的类别映射到树中的同义词集中。如下图。
Joint classification and detection
利用WordTree将数据集进行组合。用COCO的检测数据集结合整个ImageNet的全部数据包含9000个类别将检测与分类进行联合训练。WordTree包含9418个类别。ImageNet相对于较大。因此,对COCO进行过采样操作实现数据集的平衡。使ImageNet控制在4倍多的数量。
使用YOLOv2的基本构架,选择3个先验而不是原来的5个。限制输出的大小。当遇见一个检测图像,对损失函数进行正常的反向传播。对于分类损失,只对同一层级的类别的损失进行优化。当送入的为一个分类的图片。只对分类损失函数进行反向传播。只需找到预测该类别概率最高的边界框,然后只计算其预测树上的损失。同时,假设,预测框与ground truth 至少有0.3的IOU,基于此假设对损失函数进行反向传播。
基于联合训练,网络可以使用从COCO检测数据中学习的能力检测目标,从ImageNet中学习的分类能力对目标进行较广范围的分类。
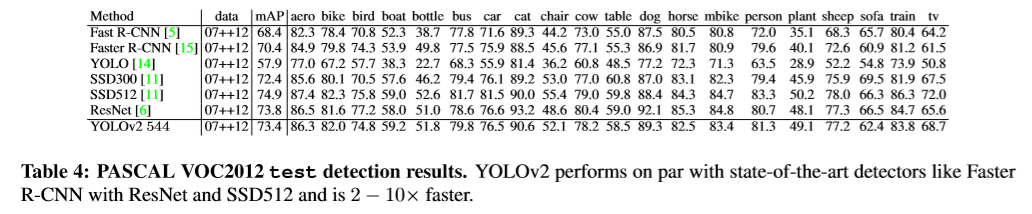
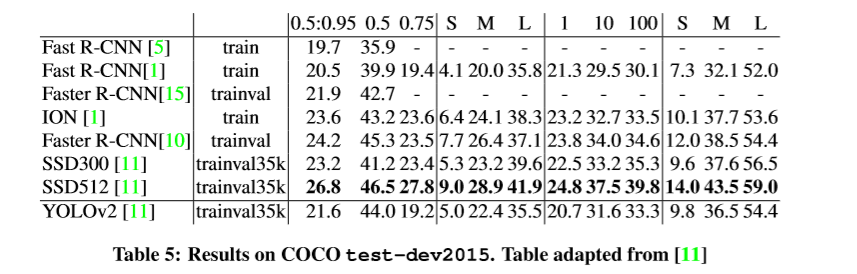
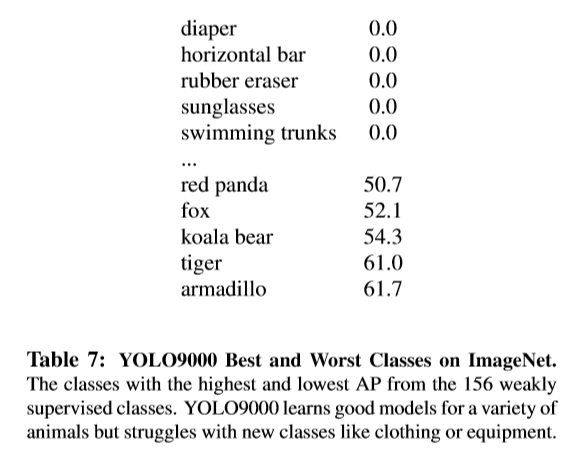
测试结果如下
Reference
[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks. arXiv preprint arXiv:1512.04143, 2015. 6
[2] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE, 2009. 1
[3] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303– 338, 2010. 1
[4] P. F. Felzenszwalb, R. B. Girshick, and D. McAllester. Discriminatively trained deformable part models, release 4. http://people.cs.uchicago.edu/ pff/latent-release4/. 8
[5] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015. 5, 6
[6] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learningforimagerecognition. arXivpreprintarXiv:1512.03385, 2015. 2, 5, 6