C++对象在内存中如何存储?
把这个问题称为C++对象模型(C++ Object Model)。下面对C++对象模型,进行说明:
要存储的内容
C++对象包括数据成员和函数成员。其中,
数据成员分为:static data members(静态数据成员),nonstatic data members(非静态数据成员);
成员函数分为:static function members(静态函数成员),nonstatic functions members(非静态函数成员),virtual functions(虚函数);
以class Point为例,
class Point {
public:
Point(float xval);
virtual ~Point();
float x() const;
static int PointCount();
protected:
virtual ostream& print(ostream &os) const;
float _x;
static int _point_count;
};
class Point在机器中如何存储data members和function members?
如何存储?
在C++对象模型中,nonstatic data members被配置于每个class object之内,static data members则存放在所有class object之外。static 和 nonstaic function members也存放在所有class object之外。virtual functions则以2个步骤支持:
- 每个class参数一堆指向virtual functions的指针,放在表格中。该表格称为virtual table(vtbl);
- 每个class object被添加了一个指针,指向virtual table。通常该指针称为vptr。vptr的设置和重置都由每个class的constructor/destructor(构造器、销毁器)和copy assignment(拷贝、赋值)运算符自动完成。每个class所关联的type_info object(用来支持runtime type identification, RTTI),也经由virtual table被指出,放在表格第一个slot处;
Point object的存储模型见下:
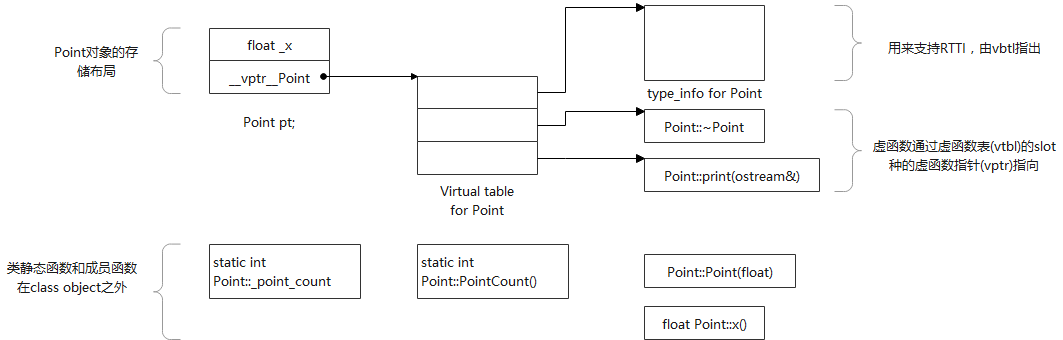
可以看到,
1)static data member放到了class object之外,nonstatic data放到了class object之内;
2)所有的static/nonstatic function members都放到了class object之外;
3)virtual functions都放到了vtbl之中,而vtbl通过class object中插入一个编译器生成的指针vptr(图中__vptr_Point)指向;
4)每个vtbl都包含一个type_info object指针,存放在vtbl[0],指向type_info object(描述对象类型信息);
模型优点:
空间和存取时间效率高;
模型缺点:
如果应用程序代码本身未改变,但用到的class objects的nonstatic data members修改了,那些应用程序代码同样得重新编译。因为nonstatic data members是直接存储在class object中,而class object被应用程序所包含,也不是通过指针指向。
加上继承,如何存储?
- 单一继承
class Library_materiasl {...};
class Book : public Library_materiasl {...};
class Rental_book : public Book {...};
- 多重继承
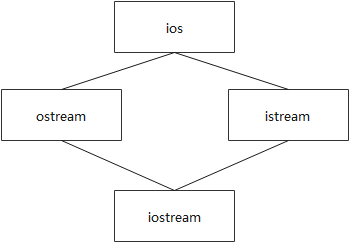
// 早期iostream实现
class iostream : public istream, public ostream {...};
class istream : virtual public ios {...};
class ostream : virtual public ios {...};
早期iostream及其基类关系如下图:
-
继承模型
在存在继承关系时,C++的继承模型又是什么样呢?
这里需要分为两种情况:普通继承,虚继承。 -
普通继承
在普继承情况下(非虚继承),base class subobject的data members被直接存放到derived class object中。
优点:提供对base class members最紧凑而有效的存取;
缺点:base class members的任何改变(增加、移除,或改变类型等),将使得所用到“此base class或其derived class的objects”者都必须重新编译。 -
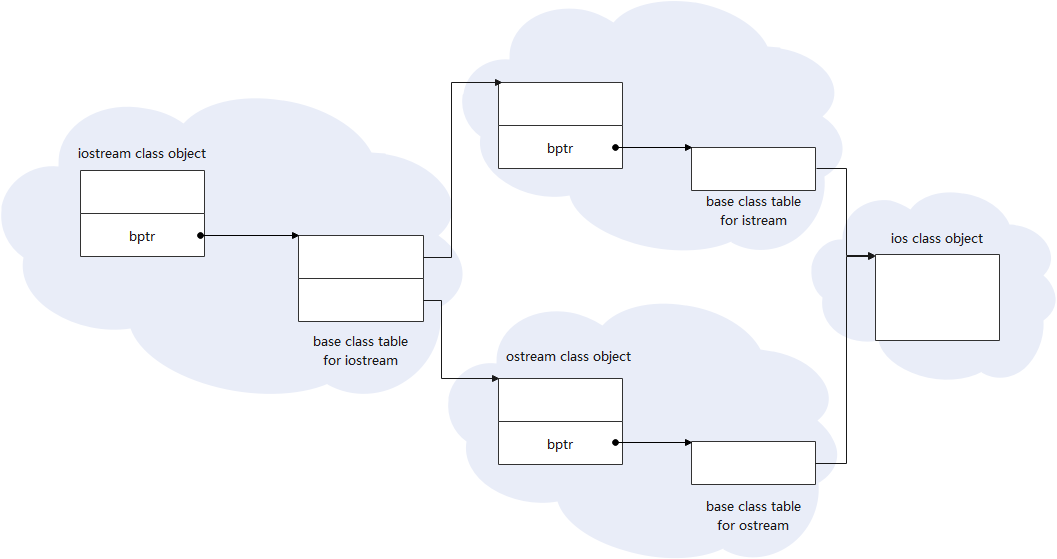
虚拟继承
在虚拟继承情况下,base classes不管在串链(chain)中被派生(derived)多少次,永远只会有一个实体(subobject)。如上面的iostream 只有一个virtual ios base classes的一个实体(继承而来的ios的成员只会有一份),而不会因为多重继承而出现多个virtual ios base classes的实体。 -
虚拟继承下,derived class如何模塑(model)其base class的实体(subobject)?
每个base class可以被derived class object产生出来的base class table内的slot指出,因为每个slot内含一个base class地址。而derived class object中指向这个base class table(基类表)的指针称为bptr(基类表指针)。
这类似于,每个class object都有一个vptr,指向一个vtbl(虚函数表)。不过,这里的vptr换成了bptr,vtbl换成了bptr。
优点:
1)每个class object中对于继承都有一致的表项方式,每个class object都应该在某个固定的位置上安放一个base table指针,与base classes的大小或数目无关;
2)不需要改变class objects本身,就可以放大、缩小,或更改base class table。
缺点:
1)由于间接性而导致的空间和存取时间上的额外负担,串链的深度会导致多次访问基类对象成员;
多重继承iostream对象模型见下:
关键词带来的差异 A keyword distinction
当语言无法区分是声明,还是表达式时,需要一个超越语言范围的规则。
例如,下面的代码是声明(declaration),还是调用(invocation)?
// 不知道是declaration还是invocation, 直到看到整数常量1024才能决定:这是一个invocation
int (*pf)(1024);
// meta-language rule:
// pq的一个declaration,而非invocation
int (*pq)();
关键词困扰 struct, class
- 一致性用法
C支持的struct和C++支持的class之间,有一个观念上的重要差异:struct代表data的集合,class还有data的相应操作(member function)。但关键词本身并不提供这种差异,这依赖于程序员对程序的约定。实际上,在使用上,struct与class没有区别,除了struct的data默认public,class的data默认private。
例如,下面的东西可以说是struct,也可以说是个class。两种声明观念上的意义,取决于对“声明”本身的检验。
// struct 名称(或clas名称)暂时省略
{
public:
operator int();
virtual void foo();
// ...
protected:
static int object_count;
// mumble
};
所谓“取决于对“声明”本身的检验”,是指真正的问题并不在于“使用者自定义类型”(struct/class)的声明是否必须使用相同的关键词,而在于使用class或struct关键词是否给予“类型的内部声明”以某种承诺。
比如,如果用struct实现C的数据萃取的观念,class实现C++的ADT(Abstract Data Type,抽象数据类型)观念,那么“不一致性”是一种错误的语言用法。
例如,下面的代码合法吗?
// 不合法吗?合法,只不过是不一致
class node;
struct node { ... };
当struct表示数据萃取观念时,如果包含member functions,那就是不一致。
struct A
{
int n;
void get_n() { return n; }
};
PS:一致性的用法 是一种风格上的问题,而非语法的问题。
- template不兼容struct
template不打算与C兼容,struct是C的内容,class是C++的内容。如果C++要支持C程序代码,就不得不支持struct,但template不必支持struct。
// 不合法
template <struct T>
class mumble { ...};
// 没问题:明白地使用了class关键词
template <class T>
struct mumble { ... };
策略性正确的struct
- struct, class的数据成员内存布局
struct能保证data members以其声明次序出现在内存布局中,因为它们都默认处于public的access section中。
对于C++,处于同一access section的数据,也能保证以其声明次序出现在内存布局中,多个access sections中的数据则不一定。
// 能保证age, name在内存中布局按其声明次序
struct stumble
{
int age;
char name[1];
};
// 不能保证age, name在内存中布局按其声明次序
class stumble
{
public:
char name[1];
// public operations ...
protected:
// protected operations ...
private:
int age;
};
- 基类和派生类的数据成员内存布局
base classess和derived classes的data members的布局也没有规定谁先谁后。
因此,程序不要依赖不同access section、base classes、derived claess之间的data members的顺序。
如果程序需要一个复杂C++ class的某部分数据,拥有C声明的那种样子,那么那一部分最好抽取出来成为一个独立的struct声明。
将C和C++结合在一起的方法:
1)从C struct 中派生C++部分(不推荐,部分编译器不支持)
struct C_point { ... };
class Point : public C_point { ... };
// C和C++两种方法都可获得支持
extern void draw_line(Point, Point);
extern "C" void draw_rect(C_point, C_point);
draw_line(Point(0, 0), Point(100, 100));
draw_rect(Point(0, 0), Point(100, 100));
2)将C和C++组合到一起,而非继承(推荐)
struct声明可以将数据封装起来,并保证拥有于C兼容的空间布局。不过,这项保证只在组合(composition)的情况下,才存在。如果是继承关系,而非组合,编译器会决定是否应该有额外的data members被安插到base struct subobject之中。
struct C_point {...};
class Point {
public:
operator C_point() { return _c_point; }
// ...
private:
C_point _c_point;
// ...
};
对象的差异 An object distinction
C++程序设计模型直接支持三种程序设计典范(programming paradigms):
- 程序模型 (procedural model)
过程式程序设计,比如处理字符串,使用字符数组作为参数,确定需要哪些过程,选择合适的算法(这里是标准C函数库中的str*\函数集)
char boy[] = "Danny";
char *p_son;
...
p_son = new char[strlen(boy) + 1];
if (!strcmp(p_son, boy))
take_to_disneyland(boy);
- 抽象数据类型模型(abstract data type model, ADT)
将一组逻辑上相关的数据和操作(public接口)封装到一起提供。如下面的String class:
class String
{
char *str;
String(){...}
String(const String &s) {...}
operator=(){...}
...
};
String girl = "Anna";
String daughter;
...
// String::operator=();
daughter = girl;
...
// String::operator=();
if (girl == daughter)
take_to_disneylan(girl);
- 面向对象模型(object-oriented model)
此模型中,有一些彼此相关的类型,通过一个抽象的base class(提供共通的接口)被封装起来。
例如,Library_materials class的例子中,subtypes如Book、Video、Compact_Disc、Puppet、Laptop等都可以从Library_materials派生而来。而凡是基类对象可以出现的地方,派生类对象都能出现。
void check_in(Library_materials *pmat)
{
if (pmat->late())
pmat->fine();
pmat->check_in();
if (Lender *plend = pmat->reserved())
pmat->notify(plend);
}
在面向对象模型中,只有通过pointer或reference(引用)的间接处理,才能支持OO程序设计所需要的多态特性。如果是直接使用对象本身进行存取,会丧失子类扩展的那部分数据和功能。
比如,下面例子中,直接将Book对象转化为基类Library_materials对象,会导致Book对象book被裁剪,值保留Library_materials那部分。
Library_materials thing1;
// class Book: public Library_materials { ... };
Book book;
// book会被裁剪,只保留Library_materials那部分
thing1 = book;
// 调用的是Library_materials::check_in(), 而非book::check_in()
thing1.check_in();
如果是通过base class的pointer或reference来完成多态:
// OK: thing2参考到book
Library_materials &thing2 = book;
// OK: 调用的是Book::check_in()
thing2.check_in();
注意:void *指针也可以支持多态,但并不是语言级别的支持,需要程序员通过明确的转型操作类管理。
- C++如何实现支持多态?
步骤:
1)经由一组隐含的转化操作,如把一个derived class指针转化为一个指向其public base type的指针;
2)经由virtual function机制,调用实际对象绑定的虚函数;
3)经由dynamic_cast和typeid运算符,将基类指针转化为派生类指针;
class Shape {
public:
virtual void rotate();
};
class Circle : public shape {
public:
virtual void rotate() override;
};
// 步骤1)
shape *ps = new Circle;
// 步骤2)
ps->rotate();
// 步骤3)
if (circle *pc = dynamic_cast<circle *>(ps)) ...
注意:dynamic_cast可以将基类指针转换为派生类指针或引用,前提是这个基类指针或引用 指向的对象实际上是派生类对象,否则转换会导致未定义行为。
需要多少内存才能表现一个class object?
一般而言,要有:
- 其nonstatic data members的总和大小;
- 加上任何由于alignment(字对齐)的需求而填补上去的空间(可能存在于members之间,也可能存在于集合体边界);
alignment是将数值调整到某数的整数倍。在32bit计算机上,通常aligment为4byte,以使bus“运输量”达到最高效率。 - 加上为了支持virtual而由内部产生的任何额外负担(overhead);
通常指虚函数表指针vptr,虚基类指针bptr。
指针的类型 The Type of a Pointer
一个指向类对象的指针,与一个指向int的指针或者数组指针,有何不同?
从内存角度来说,没有任何不同。三者都需要足够内存来存放一个机器地址(通常是个word,不同机器上长度可能不同),差异也不在于指针表示方法,或指针值不同,而是所寻址出来的object类型不同,i.e. “指针类型”会告诉编译器如何解释某个特定地址中的内存内容极其大小。
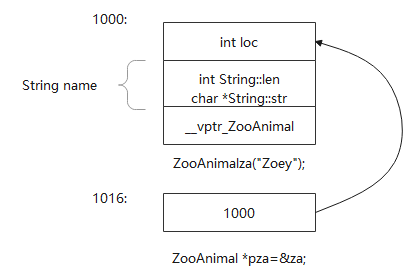
例如,下面ZooAnimal指针指向的class object类型是ZooAnimal类型对象,编译器会根据其类型解释特定地址1000开始的内存、长为16byte的空间为ZooAnimal class object空间。
class String {
int len;
char *str;
String(){...}
String(const String &s) {...}
operator=(){...}
};
class ZooAnimal {
public:
ZooAnimal();
virtual ~ZooAnimal();
//...
virtual void rotate();
private:
int loc;
String name;
};
ZooAnimal za("Zoey");
ZooAnimal *pza = &za;
加上多态之后对象的差异
例,定义一个Bear,作为一种ZooAnimal。可以通过public继承完成。
class Bear : public ZooAnimal {
public:
Bear();
~Bear();
// ...
void rotate(); // 继承ZooAnimal的virtual
// ...
protected:
enum Dances {...};
Dances dances_known;
int cell_block;
};
Bear b("Yogi");
Bear *pb = &b;
Bear &rb = *pb;
b、pb、rb会是怎样的内存需求和布局?
pointer,reference都只需要一个word空间(32位机上是4byte)。Bear object需要24bytes:ZooAnimal的16bytes + Bear定义的8bytes。
Derived class(Bear)的object(b)和pointer(pb)、reference(rb)可能的内存布局:
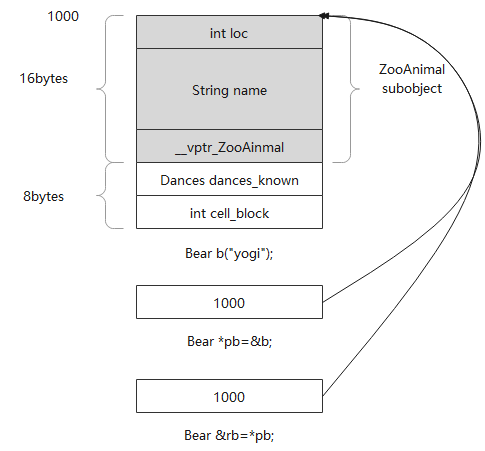
假设Bear object放在地址1000处,一个Bear指针和一个ZooAnimal指针有何不同?
如下面代码中&b 为1000,那么指向同一个地址&b的pz和pb有什么区别?
Bear b;
ZooAnimal *pz = &b;
Bear *pb = &b;
相同点是pz和pb都指向Bear object的第一个byte,差别是:pb涵盖的地址范围包括整个Bear object,pz涵盖的地址范围只包括Bear object中的ZooAnimal subobject部分。
i.e. 2个指针能访问的范围不同,取决于指针类型。通过pz无法访问属于Bear那部分(成员数据和成员函数),只能访问属于ZooAnimal的那部分。
参考
[1]李普曼侯捷. 深度探索C++对象模型#:#Inside the C++ object model[M]. 电子工业出版社, 2012.