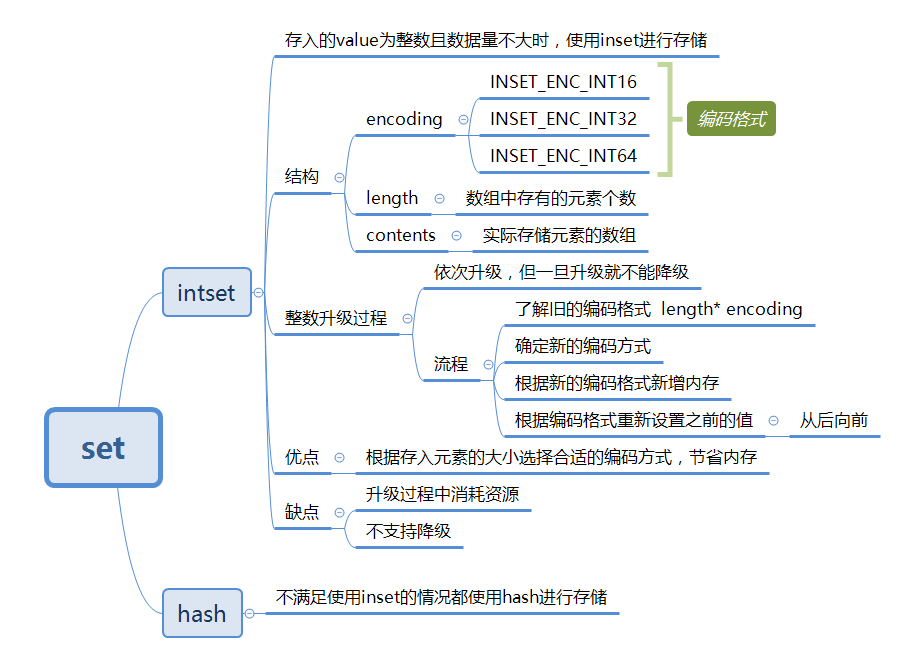
与Java中的HashSet一样,无序且存储元素不重复。其底层有两种实现方式,当value是整数值时,且数据量不大时使用inset来存储,其他情况都是用字典dict来存储。
1|0 inset
Redis中inset的结构定义如下所示:
typedf struct inset{
uint32_t encoding;//编码方式 有三种 默认 INSET_ENC_INT16
uint32_t length; //集合元素个数
int8_t contents[]; //实际存储元素的数组
//元素类型并不一定是ini8_t类型,柔性数组不占intset结构体大小,并且数组中的元
//素从小到大排列
}inset;
#define INTSET_ENC_INT16 (sizeof(int16_t)) //16位,2个字节,表示范围-32,768~32,767
#define INTSET_ENC_INT32 (sizeof(int32_t)) //32位,4个字节,表示范 //围-2,147,483,648~2,147,483,647
#define INTSET_ENC_INT64 (sizeof(int64_t)) //64位,8个字节,表示范 //围-9,223,372,036,854,775,808~9,223,372,036,854,775,807 编码格式encoding:共有三种,INTSET_ENC_INT16、INSET_ENC_INT32和INSET_ENC_INT64三种,分别对应不同的范围。Redis为了尽可能地节省内存,会根据插入数据的大小选择不一样的类型来进行存储。
元素数量length:记录了保存数据的数组contents中共有多少个元素,这样获取个数的时间复杂度就是O(1)。
数组contents:真正存储数据的地方,数组是按照从小到大有序排列的,并且不包含任何重复项。
intset的示意图如下所示:

2|0 inset中整数的升级过程
这个过程可以参考这位小姐姐写的文章,配图食用,效果更加。整体流程总结如下:
- 了解旧的存储格式,计算出目前已有元素占用内存大小,计算规则是length * encoding,如 4* 16=64;
- 确定新的编码格式,当原有的编码格式不能存储下新增的数据时,此时就要选择新的合适的编码格式;
- 根据新的编码格式计算出需要新增的内存大小,然后从尾部将数据插入;
- 根据新的编码格式重置之前的值,此时
contents存在两种编码格式设置的值,就需要进行统一,从插入新数据的起始位置开始,从后向前将之前的数据按照新的编码格式进行移动和设置。从后往前是为了防止数据被覆盖。
优点:根据存入的数据大小选择合适的编码方式,且只在必要的时候进行升级操作,节省内存
缺点:升级过程耗费系统资源,还有就是不支持降级,一旦升级就不可以降级
3|0 总结