我们都知道,Redis是由C语言编写的。在C语言中,字符串标准形式是以空字符�作为结束符的,但是Redis里面的字符串却没有直接沿用C语言的字符串。主要是因为C语言中获取字符串长度可以调用strlen这个标准函数,这个函数的时间复杂度是O(N),由于Redis是单线程的,承受不了这个时间复杂度。
1|0 Redis中string的存储方式
在上一篇文章中,我们介绍了Redis的RedisObject的数据结构,如下所示:
typedef struct redisObject {
// 对外的类型 string list set hash zset等 4bit
unsigned type:4;
// 底层存储方式 4bit
unsigned encoding:4;
// LRU 时间 24bit
unsigned lru:LRU_BITS;
// 引用计数 4byte
int refcount;
// 指向对象的指针 8byte
void *ptr;
} robj;对于不同的对象,Redis会使用不同的类型来存储。对于同一种类型type会有不同的存储形式encoding。对于string类型的字符串,其底层编码方式共有三种,分别为int、embstr和raw。
int:当存储的字符串全是数字时,此时使用int方式来存储;embstr:当存储的字符串长度小于44个字符时,此时使用embstr方式来存储;raw:当存储的字符串长度大于44个字符时,此时使用raw方式来存储;
使用object encoding key可以查看key对应的encoding类型,如下所示:

对于embstr和raw这两种encoding类型,其存储方式还不太一样。对于embstr类型,它将RedisObject对象头和SDS对象在内存中地址是连在一起的,但对于raw类型,二者在内存地址不是连续的。

2|0 SDS
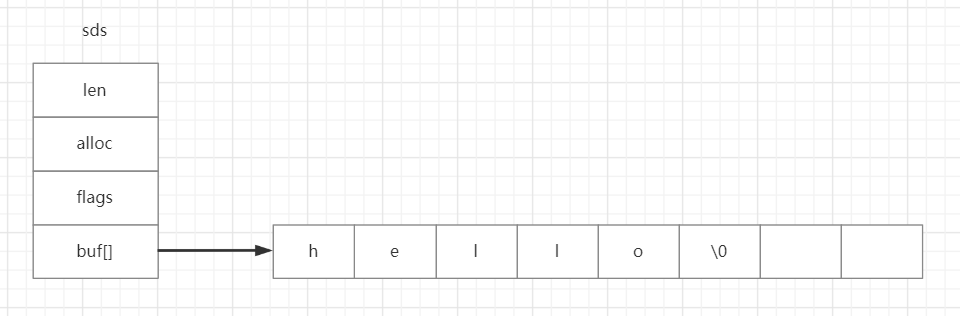
在介绍string类型的存储类型时,我们说到,对于embstr和raw两种类型其存储方式不一样,但ptr指针最后都指向一个SDS的结构。那什么是SDS呢?Redis中的字符串称之为Simple Dynamic String,简称为SDS。与普通C语言的原始字符串结构相比,sds多了一个sdshdr的头部信息,sdshdr基本数据结构如下所示:
struct sdsshr<T>{
T len;//数组长度
T alloc;//数组容量
unsigned flags;//sdshdr类型
char buf[];//数组内容
}可以看出,SDS的结构有点类似于Java中的ArrayList。buf[]表示真正存储的字符串内容,alloc表示所分配的数组的长度,len表示字符串的实际长度,并且由于len这个属性的存在,Redis可以在O(1)的时间复杂度内获取数组长度。
为了追求对于内存的极致优化,对于不同长度的字符串,Redis底层会采用不同的结构体来表示。在Redis中的sds.h源码中存在着五种sdshdr,分别如下:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};上面说了,Redis底层会根据字符串的长度来决定具体使用哪种类型的sdshdr。可以看出,sdshdr5明显区别于其他四种结构,它一般只用于存储长度不会变化,且长度小于32个字符的字符串。但现在一般都不再使用该结构,因为其结构没有len和alloc这两个属性,不具备动态扩容操作,一旦预分配的内存空间使用完,就需要重新分配内存并完成数据的复制和迁移,类似于ArrayList的扩容操作,这种操作对性能的影响很大。
上面介绍sdshdr属性的时候说过,flag这个属性用于标识使用哪种sdshdr类型,flag的低三位标识当前sds的类型,分别如下所示:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4 同时,注意到在每个sdshdr的头定义上都有一个attribute((packed)),这个是为了告诉gcc取消优化对齐,这样,每个字段分配的内存地址就是紧紧排列在一起的,Redis中字符串参数的传递直接使用char*指针,其实现原理在于,由于sdshdr内存分配禁止了优化对齐,所以sds[-1]指向的就是flags属性的内存地址,而通过flags属性又可以确定sdshdr的属性,进而可以读取头部字段确定sds的相关属性。
sds的逻辑图如下所示:
3|0 sdshdr的优势
相比较于C语言原始的字符串,sdshdr的具备一些优势。
3|1 长度获取
由于sdshdr中存在len这个属性,所以可以在O(1)的时间复杂度下获得长度;而传统的C语言得使用strlen这个标准函数获取,时间复杂度为O(N)。
3|2 避免频繁的内存分配
原始的C语言一直使用与长度匹配的内存,这样在追加字符串导致字符串长度发生变化时,就必须进行内存的重新分配。内存重新分配涉及到复杂算法和系统调用,耗费性能和时间。对于Redis来说,它是单线程的,如果使用原始的字符串结构,势必会引发频繁的内存重分配,这个显然是不合理的。
因而,sds每次进行内存分配时,都会通过内存的预分配来减少因为修改字符串而引发的内存重分配次数。这个原理可以参数Java中的ArrayList,一般在使用ArrayList时都会建议使用带有容量的构造方式,这样可以避免频繁resize。
对于SDS来说,当其使用append进行字符串追加时,程序会用 alloc-len 比较下剩下的空余内存是否足够分配追加的内容,如果不够自然触发内存重分配,而如果剩余未使用内存空间足够放下,那么将直接进行分配,无需内存重分配。其扩容策略为,当字符串占用大小小于1M时,每次分配为len * 2,也就是保留100%的冗余;大于1M后,为了避免浪费,只多分配1M的空间。
通过这种预分配策略, SDS 将连续增长 N 次字符串所需的内存重分配次数从必定 N 次降低为最多 N 次。
3|3 缓冲区溢出
缓冲区溢出是指当某个数据超过了处理程序限制的范围时,程序出现的异常操作。原始的C语言中,是由编码者自己来分配字符串的内存,当出现内存分配不足时就会发生缓存区溢出。而sds的修改函数在修改前会判断内存,动态的分配内存,杜绝了缓冲区溢出的可能性。
3|4 二进制安全
对于原始的C语言字符串来说,它会通过判断当前字符串中是否存在空字符�来确定是否已经是字符串的结尾。因而在某些情况下,如使用空格进行分割一段字符串时,或者是图片或者视频等二进制文件中存在�等,就会出问题。而sds不是通过空字符串来判断字符串是否已经到结尾,而是通过len这个字段的值。所以说,sds还具备二进制安全这个特性,即可以安全的存储具有特殊格式的二进制数据。
4|0 总结
