刚刚开始玩爬虫,想爬点简单的稍微有点意思的,一开始想爬那啥小视频的~但是我还是忍住了哈哈哈。
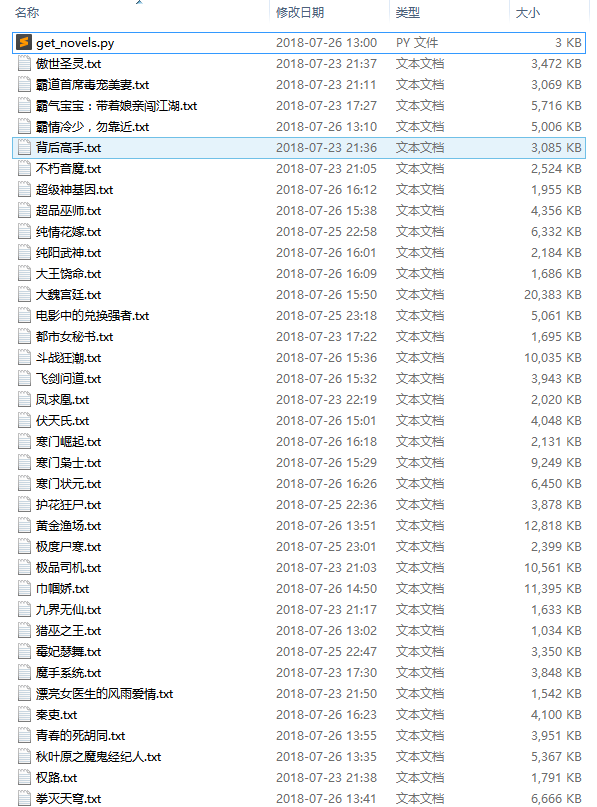
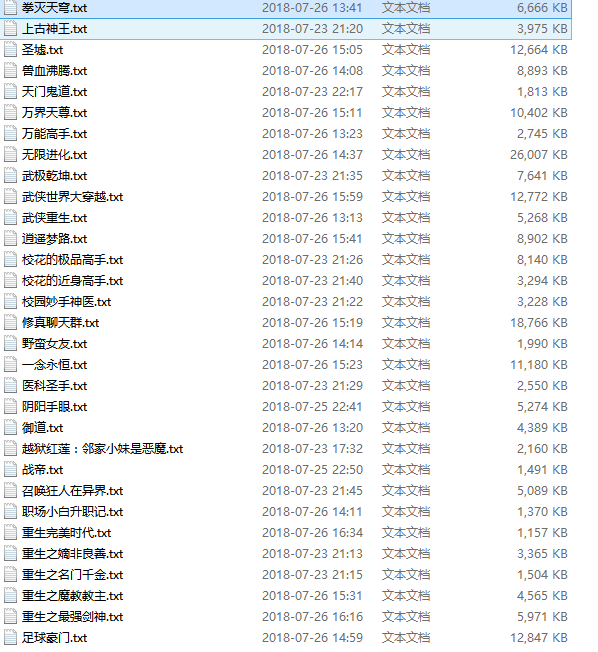
所以就随便找个静态小说网站,爬了点全本小说。
不多,60几本,平均一本不到十兆的样子。
很慢。。真的很慢。。跑了好久。。改了好几回参数。。忽略可耻的时间。。23号其实是25号。。
中途也出现了很多很多错误。。
当个笑话看看就得了,抛个砖~
毕竟是往前又迈了一步~开心
真的得好好地系统的学习一下爬虫,比如现在我在看 崔庆才,崔先生写的《Python3 网络爬虫开发实战》感觉很棒棒。。要加油!
主要用了 requests,BeautifulSoup,其他还用到了 urljoin 合并网址
1 # -*- coding:UTF-8 -*- 2 from bs4 import BeautifulSoup 3 from urllib.parse import urljoin 4 import requests 5 import sys 6 7 8 class Downloader(object): 9 def __init__(self): 10 self.server = 'http://www.biquge.com.tw/quanben/' 11 self.novel_urls = [] 12 self.novel_names = [] 13 self.chapter_urls = [] 14 self.nums = 0 15 16 def get_novels_info(self): 17 req = requests.get(self.server) 18 html_doc = req.content.decode('gbk', 'ignore') 19 soup = BeautifulSoup(html_doc, 'html.parser') 20 spans = soup.find_all('span', class_='s2') 21 for span in spans: 22 self.novel_urls.append(span.find('a').get('href')) 23 self.novel_names.append(span.find('a').get_text()) 24 25 def get_download_urls(self, index): 26 self.chapter_urls.clear() 27 req = requests.get(self.novel_urls[index], timeout=5) 28 html_doc = req.content.decode('gbk', 'ignore') 29 soup = BeautifulSoup(html_doc, 'html.parser') 30 a = soup.find('div', id='list').find_all('a') 31 for each in a: 32 url = urljoin(self.novel_urls[index], each.get('href')) 33 self.chapter_urls.append(url) 34 35 36 def get_content(self, url): 37 req = requests.get(url) 38 html_doc = req.content.decode('gbk', 'ignore') 39 soup = BeautifulSoup(html_doc, 'html.parser') 40 texts = soup.find_all('div', id='content') 41 chapter_name = soup.find('div', class_='bookname').find('h1').text 42 content = (chapter_name + ' ' + texts[0].text).replace('xa0', '') 43 return content 44 45 def writer(self, path, content): 46 with open(path, 'a', encoding='utf-8') as f: 47 f.writelines(content) 48 f.write(' ') 49 50 51 def main(): 52 dl = Downloader() 53 dl.get_novels_info() 54 for i in range(35, len(dl.novel_names)): 55 try: 56 dl.get_download_urls(i) 57 print('开始下载 ' + dl.novel_names[i] + ' ...') 58 for j in range(len(dl.chapter_urls)): 59 dl.writer(dl.novel_names[i] + '.txt', dl.get_content(dl.chapter_urls[j])) 60 sys.stdout.write(" 已下载: %.3f%%" % float(j / len(dl.chapter_urls) * 100) + ' ') 61 sys.stdout.flush() 62 print(" " + dl.novel_names[i] + " 下载完成。") 63 except TimeoutError: 64 print(" " + dl.novel_names[i] + "打开失败。") 65 except requests.exceptions.ConnectionError: 66 print(" " + dl.novel_names[i] + "下载失败。") 67 68 69 if __name__ == '__main__': 70 main()