redis 数据结构之 SDS (简单动态字符串)
sds -->{
int len, // 记录buf数组已使用字节的数量
int free,// 记录buf数组中未使用的字节量
char buf[] //字节数组,用于保存字符串 注:用字节长度表示存储字符串
}
从上面可以看出sds获取长度的时间复杂度为o(1),不用像c字符串一样需要遍历获取长度
但是sds这样的数据结构也会增加一字节的开销用于记录长度
sds 很棒的设计是:
杜绝缓冲区溢出:
sds的buf[] 分配策略采用:当执行相关sds命令时,sds api 会先检查sds的空间是否满足修改要求,如果
杜绝缓冲区溢出:
sds的buf[] 分配策略采用:当执行相关sds命令时,sds api 会先检查sds的空间是否满足修改要求,如果
不满足则 api 会自动将sds的空间扩展至执行修改所需空间大小。然后在执行实际修改操作,但是如果仅仅使buf
长度为满足执行修改所需要求的话,那么下次修改时仍需扩容,这就会频繁的涉及到系统调用,需要占系统资源,对于性能会有很大影响。所以会在扩容时,指定一片为使用的区域,而这个区域的长度则由free 决定
下面是free的分配测略
下面则要重点介绍 sds空间分配策略:
1:空间预分配
1:空间预分配
如果修改后len属性的值小于1MB,则会分配一个和len长度相同的未使用的空间,此时len=free
如果修改后len属性的值大于1MB,则会分配1MB大小未使用的空间,此时free=1MB
2:惰性空间释放:
比如当sds api执行 sdstrim时会将释放出来的字节空间指定到free当中以备下次使用,这样可以缩短字符串所需内存重分配策略
比如当sds api执行 sdstrim时会将释放出来的字节空间指定到free当中以备下次使用,这样可以缩短字符串所需内存重分配策略
对于redis当中的String对象
String 类型除了记录保存到数据外,还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了,这样会使得使用的String对象看起来就没有很高的高效性。这也是使用String对象的一个缺点
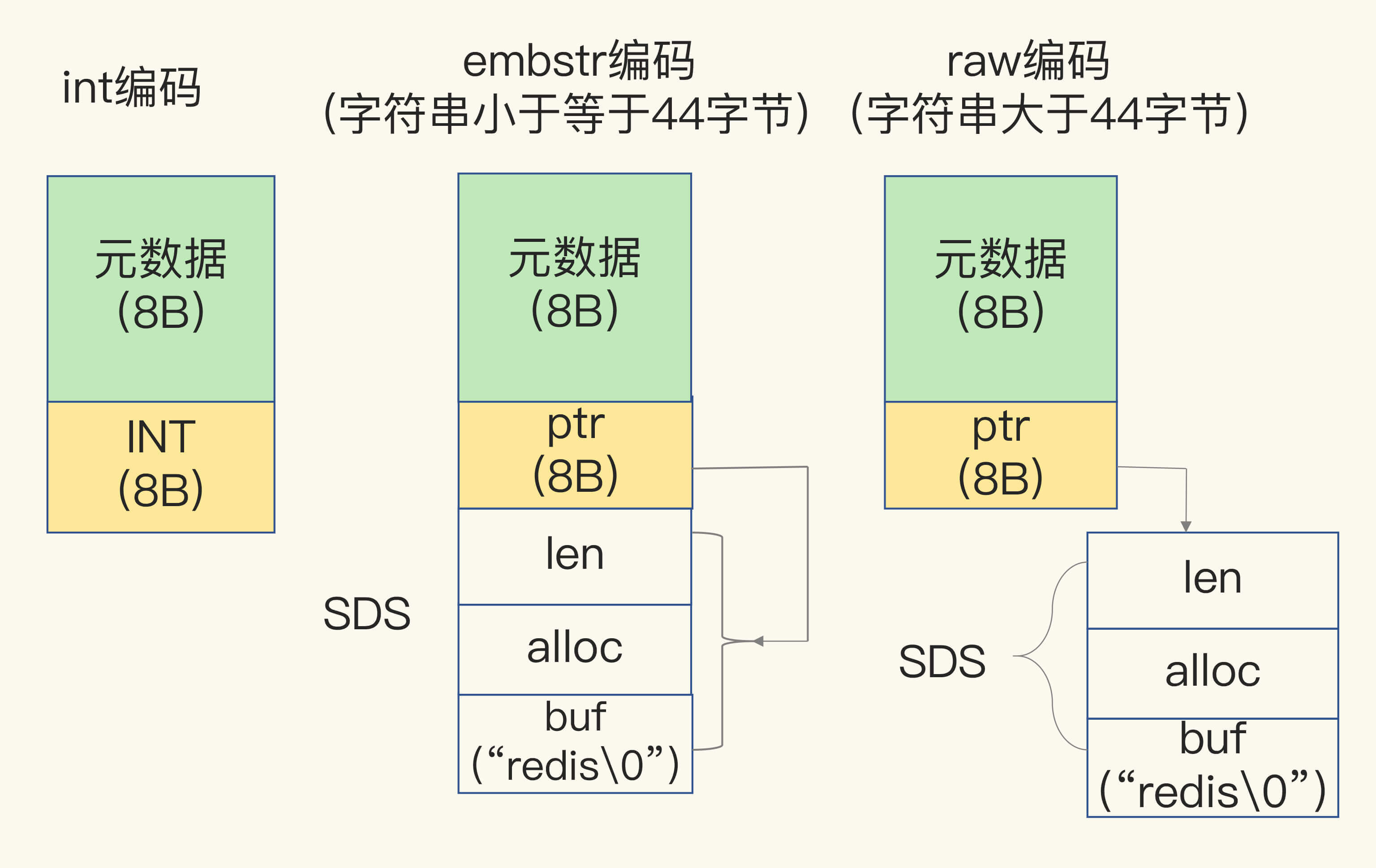
当保存 64 位有符号整数时,String 类型会把它保存为一个 8 字节的 Long 类型整数,这种保存方式通常也叫作 int 编码方式。而保存的数据中包含字符时,String 类型就会用简单动态字符串(SDS)结构体来保存。
为了节省内存空间,Redis 还对 Long 类型整数和 SDS 的内存布局做了专门的设计:
当保存的是 Long 类型整数时,值(字符串对象) 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
当保存的是字符串数据,并且字符串小于等于 44 字节时,值(字符串对象)中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。
当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。