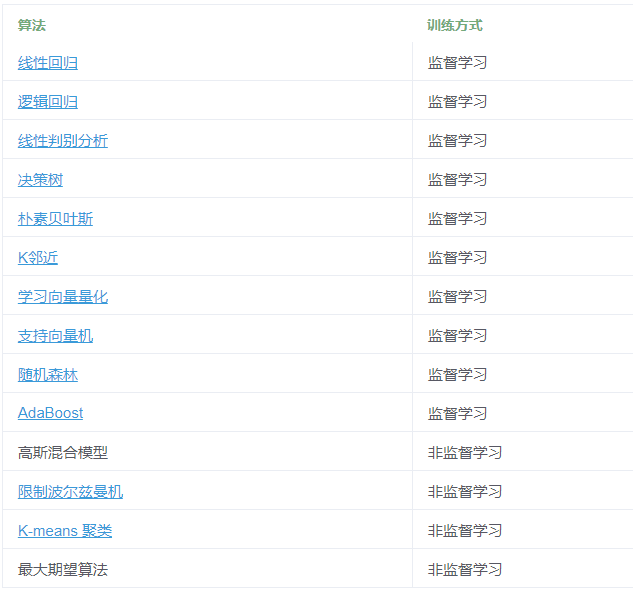
1.什么是机器学习?
像豆瓣、淘宝、QQ音乐这些推荐系统,背后的秘密武器正是机器学习
机器学习是:用机器学习算法来建立模型,并利用规律和模型对未知数据进行预测。
- 监督学习 supervised learning;
- 非监督学习 unsupervised learning;
- 半监督学习 semi-supervised learning;
- 强化学习 reinforcement learning;
- 遗传算法 genetic algorithm
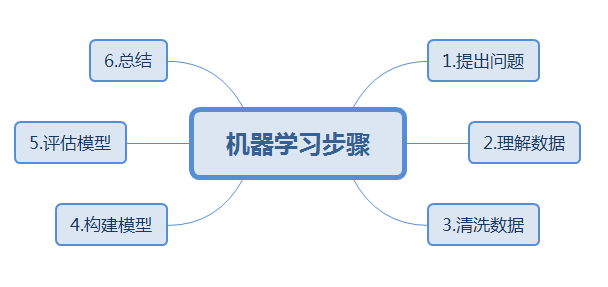
2.机器学习步骤


机器学习的基本步骤 1. 提出问题: 明确是分类问题还是回归问题 2. 理解数据: 2.1 采集数据 sklearn.datasets中有练习数据(数据要有代表性,数据量要合适) 2.2 导入数据 pd.csv... 2.3 查看数据集信息 data.shape查看数据形状;.shape[0]查看行数;.shape[1]查看列数 df.head()查看前几行; df.describe()查看数值数据的描述统计信息; http://df.info()根据行数查看数据是否有缺失值,数据类型是否合适 了解各个字段的含义,目标和特征分别是哪个字段;也可通过可视化了解数据的分布 3. 数据清洗: 3.1 数据预处理:缺失值处理、重复值处理、数据类型的转换、字符串数据的规整 缺失值处理(标签数据无需填充缺失): 数值类型,用平均值取代:data[A].fillna(data[A].mean()) 分类数据,用最常见的类别取代:data[A].value_counts();data[A].fillna("前面得到的最常见的类别");data[A].fillna("U")缺失比较多时,填充代表未知的字符串 使用模型预测缺失值,例如:K-NN 数据归一化/标准化: 模型具有伸缩可变性,如SVM,最好进行标准化,避免模型参数受极值影响;伸缩不变模型,如逻辑回归,最好也进行标准化,可以加快训练速度 归一化/标准化常见两种方法:min-max,化为[0,1]:(x-min(x))/(max(x)-min(x))/preprocessing.MinMaxScaler;适合分别在有限范围内的数据,数值较集中,但min/max不稳定会影响结果 Z-core,化为均值为0,方差为1:(x-mean(x))/std(x)/sklearn.preprocessing.scale(),适合最大/最小值未知,或者有超出取值范围的离散值 3.2 特征提取(特征工程.1) 数值型数据处理:一般可直接使用,或通过运算转化为新的特征 家庭人数可统计分类:df.家庭人数=df.A+df.B+1(自己);df.小家庭=df.家庭人数.map(lambda匿名函数-lambda s : 1 if 2 <= s <= 4 else 0) 分类型数据处理: 两个类别:性别数据分别填充为1、0:df.A=df.A.map({"male":1;"female":0}) 超两个类别:one-hot编码,data'=pd.get_dummies(df.A , prefix='前缀' );pd.concat([data,data'],axis=1) 字符串型-姓名:每一个姓名中都包含了称谓,利用split函数将称谓提取出来;.strip用于移除空格;将称谓进行归类,定义对应字典,利用map函数替换;进行one_hot编码 字符串型-客舱号:a[n]可以取到字符串数据 第“n”个字符;提取之后进行one_hot编码 时间序列数据,一段时间定期收集的数据-可转成年月日 3.3 特征选择(特征工程.2) 计算各个特征和标签的相关性:df '=pd.corr() 查看标签对应的相关系数:df '.标签.sort_values(ascending =False) 根据相关系数的大小选择特征列做为模型输入 4. 构建模型: 4.1 建立训练数据集和测试数据集 选取训练数据和测试数据的特征和标签:.loc选取特征列和标签列;train_test_spilt 划分,通常80%为训练数据集 .shape查看划分结果 4.2. 选择机器学习算法: 导入算法 逻辑回归(logisic regression) 随机森林(Random Forests Model) 支持向量机(Support Vector Machines) Gradient Boosting Classifier K-nearest neighbors Gaussian Naive Bayes 数据降维:PCA,Isomap 数据分类:SVC,K-Means 线性回归:LinearRegression 创建模型 model=LinearRegression() 训练模型 model.fit(train_X , train_y ) 5. 评估模型 model.score(test_X , test_y ),不同的模型指标不一样,分类模型评估准确率 metrics.confusion_matrix:混淆矩阵 homogeneity_score:同质性,每个群集只包含单个类的成员;[0,1],1表示完全同质。 completeness_score:完整性,给定类的所有成员都分配给同一个群集。[0,1],1表示完全完整。 v_measure_score:同质性和完整性的调和平均值 adjusted_mutual_info_score:兰德系数ARI,取值范围[-1,1],值越大,表示与聚类结果与真实越吻合,体现的是两个数据分布的吻合程度 adjusted_mutual_info_score:互信息AMI,取值[-1,1],值越大,与真实情况越吻合。 fowlkes_mallows_score:精确率和召回率的几何平均值,[0,1],越大,越相似。 silhouette_score:轮廓系数,[-1,1]同类别越近,不同类别越远,系数越大。 calinski_harabaz_score:类内部协方差越小,类之间协方差越大,改数值越大,聚类效果越好。 6. 方案实施 model.predict(pred_X),得到预测结果 7.报告撰写
3、协方差和相关系数
确定自变量和因变量之间的相关性
一、简单线性回归
回归分析(Regression Analysis)
研究自变量与因变量之间关系形式的分析方法,它主要是通过建立因变量y与影响它的自变量 x_i(i=1,2,3… …)之间的回归模型,来预测因变量y的发展趋向。
回归分析的分类:
线性回归分析:简单线性回归、多重线性回归
非线性回归分析:逻辑回归、神经网络
回归分析的步骤:
1、根据预测目标,确定自变量和因变量
2、绘制散点图,确定回归模型类型
3、估计模型参数,建立回归模型
4、对回归模型进行检验
5、利用回归模型进行预测
简单线性回归模型
(1)第一步 确定变量
确定因变量和自变量很简单,谁是已知,谁就是自变量,谁是未知,就就是因变量,因此,推广费是自变量,销售额是因变量;
import numpy from pandas import read_csv from matplotlib import pyplot as plt from sklearn.linear_model import LinearRegression data = read_csv( )
(2)第二步 确定类型
绘制散点图,确定回归模型类型
根据前面的数据,画出自变量与因变量的散点图,看看是否可以建立回归方程,
在简单线性回归分析中,我们只需要确定自变量与因变量的相关度为强相关性,即可确定可以建立简单线性回归方程,
求解出推广费与销售额之间的相关系数是0.94,也就是具有强相关性,
从散点图中也可以看出,二者是有明显的线性相关的,也就是推广费越大,销售额也就越大
#画出散点图,求x和y的相关系数 plt.scatter(data.活动推广费,data.销售额) data.corr()
协方差:
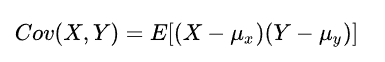
如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积再对这每时刻的乘积求和并求出均值(期望)
相关系数:
1)Pearson相关系数是在原始数据的方差和协方差基础上计算得到,所以对离群值比较敏感,它度量的是线性相关。因此,即使pearson相关系数为0,也只能说明变量之间不存在线性相关,但仍有可能存在曲线相关。
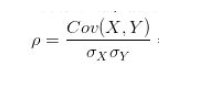
就是用X、Y的协方差除以X的标准差和Y的标准差
(3)第三步 建立模型
估计模型参数,建立回归模型
要建立回归模型,就要先估计出回归模型的参数A和B,那么如何得到最佳的A和B,使得尽可能多的数据点落在或者更加靠近这条拟合出来的直线上呢?
最小二乘法
#估计模型参数,建立回归模型 ''' (1) 首先导入简单线性回归的求解类LinearRegression (2) 然后使用该类进行建模,得到lrModel的模型变量 ''' lrModel = LinearRegression() #(3) 接着,我们把自变量和因变量选择出来 x = data[['活动推广费']] y = data[['销售额']] #模型训练 ''' 调用模型的fit方法,对模型进行训练 这个训练过程就是参数求解的过程 并对模型进行拟合 ''' lrModel.fit(x,y)
(4)第四步 模型检验
对回归模型进行检验
决定系数R平方
用来评估模型的精确度,即回归线的拟合程度;
R平方越高,回归模型越准确;
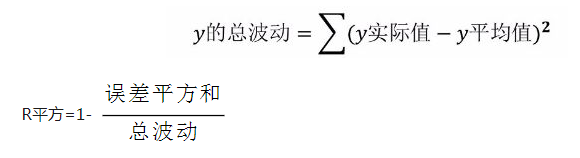
#对回归模型进行检验 lrModel.score(x,y)
解释:判定系数等于相关系数R的平方用于表示拟合得到的模型能解释因变量变化的百分比,R平方越接近于1,表示回归模型拟合效果越好
(5)第五步 模型预测
- 调用模型的predict方法,这个就是使用sklearn进行简单线性回归的求解过程;
用Python实现简单线性回归实例
一、机器学习的步骤:
二、提出问题
学习时间和成绩的关系
(明确是分类问题还是回归问题)
三、理解数据
3.1 获取数据源 本次数据源为自定义数据
data={ '学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25, 2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50], '分数':[10,22,13,43,20,22,33,50,62,48,55,75,62,73,81,76,64,82,90,93] }
3.2查看数据集信息
data.info()
data.shape查看数据形状;
.shape[0]查看行数;.shape[1]查看列数 df.head()查看前几行;
df.describe()查看数值数据的描述统计信息;
data_order=OrderedDict(data)
df = pd.DataFrame(data_order)
df.info()

df.head()
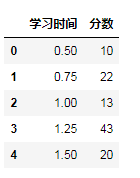
自定义数据集共有两个字段,学习时间和分数,共20条数据
四、清洗数据
数据自定义且格式正确
五、构建模型
#5.1绘制散点图,确定回归模型类型 # 提取特征值 exam_x = df.loc[:,'学习时间'] exam_y = df.loc[:,'分数'] plt.scatter(exam_x,exam_y,color='r',label='exam_score') # 添加坐标标签 plt.xlabel('hours') plt.ylabel('score') #显示图像 plt.show()
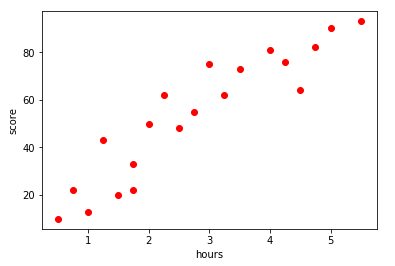
# 从以上散点图可以初步判断,该数据集特征和标签的关系符合正线性回归模型。
# 判断学习时间和成绩的相关性 df.corr()
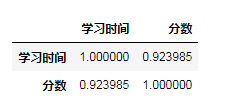
求解出学习时间与成绩之间的相关系数是0.924,也就是具有强相关性,从散点图中也可以看出,二者是有明显的线性相关的,也就是学习时间越长,分数越高
5.2建立训练数据集和测试数据集 分割数据,将数据随机分成训练数据(80%)和测试数据(20%):
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取训练数据(train)和
测试数据(test)
第一个参数:所要划分的样本特征
第2个参数:所要划分的样本标签
train_size:训练数据占比,如果是整数的话就是样本的数量,这里是80%
from sklearn.model_selection import train_test_split x_train , x_test , y_train , y_test = train_test_split(exam_x , exam_y, train_size = 0.8) #输出数据大小 print('原始数据特征:',exam_x.shape , ',训练数据特征:', x_train.shape , ',测试数据特征:',x_test.shape ) print('原始数据标签:',exam_y.shape , '训练数据标签:', y_train.shape , '测试数据标签:' ,y_test.shape)

5.3选择机器学习算法:
# 导入算法 逻辑回归(logisic regression) 随机森林(Random Forests Model) 支持向量机(Support Vector Machines) Gradient Boosting Classifier K-nearest neighbors Gaussian Naive Bayes 数据降维:PCA,Isomap 数据分类:SVC,K-Means 线性回归:LinearRegression 创建模型 model=LinearRegression() 训练模型 model.fit(train_X , train_y )
本分析案例属于强线性相关,选择线性回归算法进行 训练模型
# 第1步:导入线性回归 from sklearn.linear_model import LinearRegression # 第2步:创建模型:线性回归 model = LinearRegression() # 第3步:训练模型 model.fit(x_train , y_train)

上面报错的内容翻译过来就是:
如果你输入的数据只有1个特征,需要用array.reshape(-1, 1)来改变数组的形状
#将训练数据特征转换成二维数组XX行*1列 x_train=x_train.values.reshape(-1,1) #将测试数据特征转换成二维数组行数*1列 x_test=x_test.values.reshape(-1,1) #第1步:导入线性回归 from sklearn.linear_model import LinearRegression # 第2步:创建模型:线性回归 model = LinearRegression() #第3步:训练模型 model.fit(x_train ,y_train)
六、模型评估
6.1、求出线性回归方程
a=model.intercept_ #截距 b=model.coef_ #回归系数 print('最佳拟合线:截距a=',a,',回归系数b=',b)

6.2绘图
# 绘图 import matplotlib.pyplot as plt # 训练数据散点图 plt.scatter(x_train, y_train, color='blue', label="train data") # 测试数据散点图 plt.scatter(x_test,y_test,color='r',label='test data') # 训练数据的预测值 y_train_pred = model.predict(x_train) # 绘制最佳拟合 plt.plot(x_train, y_train_pred, color='black', linewidth=3, label="best line") # 添加图标标签 plt.legend(loc=2) plt.xlabel("Hours") plt.ylabel("Score") plt.show()
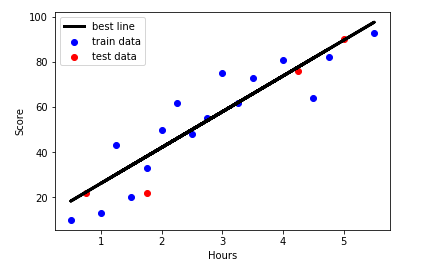
6.3评估模型:决定系数R平方
model.score(x_test , y_test)
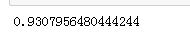
R平方=0时,x变量与y变量无关 R平方=1时,x变量可预测y变量,且没有误差 R平方越大(0到1),回归模型越精确
七、总结
研究问题:学习时间和成绩的关系?
数据来源:自定义数据源共20条数据
特征值和标签分别为:学习时间和成绩
(特征是做出某个判断的证据,标签是结论)
相关系数是0.924,也就是具有强相关性,选择线性回归算法进行 训练模型
评估模型:决定系数R平方为0.93,表示回归模型精准,拟合效果好
结论:学习时间与成绩是强相关性也就是学习时间越长,分数越高