安装xlsx包
#装之前先装jdk,配置环境变量 install.packages("xlsx")

代表安装成功
必须先加载包然后再使用包
library()
$提取符号
当一个函数里需要返回多个值(比如有变量,有向量,有矩阵)时,我们要用list,而不是return,
这时如果想提取某个变量的结果,就需要用到$,默认情况下,对于 `list`, `environment` 这两种对象,`$`可以提取(extract)出里面的元素。
必知必会的函数
x<-c(7,5,8,9,2) #最大值 max(x) #最小值 min(x) #同时获取最大值和最小值 range(x) #后一项减去前一项 diff(x) #极差 diff(range(x)) #累加和 cumsum(x) #累计乘积 cumprod(x) #累计求最大值 cummax(x) #累计求最小值 cummin(x) #基于矩阵和数据框的函数 #循环:显式循环、隐式循环 #显式:for、while、repeat #隐式:apply、lapply、sapply #apply #构造矩阵m m<-matrix(1:12,nrow = 3,byrow = T) #计算矩阵的每一行的和 # 1代表行,2代表列 apply(m,1,sum) #计算矩阵的每一列的均值 apply(m,2,mean) #lapply #构造一个列表 # l是逻辑向量 x<-list(a=1:10,beta=exp(-3:3),l=c(T,F,F,T)) #把mean函数作用到x的每一个元素上 lapply(x,mean) #sapply #s代表简化,简化的是返回数据的数据结构 sapply(x,mean) sapply(3:6,seq) sapply(sapply(3:6,seq),sum)
写入excel文件
#plyr、openxlsx、xlsx install.packages("rJava") install.packages("xlsxjars") install.packages("plyr") install.packages("openxlsx") #装之前先装jdk,配置环境变量 install.packages("xlsx") library(xlsx) library(openxlsx) library(plyr) pkp<-data.frame(pm=rep(c("A",2:10,"J","Q","K"),times=4), hs=rep(c("红桃","黑桃","梅花","方块"),each=13), ds=rep(1:13,times=4), stringsAsFactors = F) #按照花色切分数据框 pkp_lst<-split(pkp,pkp$hs) #构造写入函数 xr<-function(x){ x_n<-unique(x$hs) xlsx::write.xlsx(x,file = "扑克牌分类数据.xlsx", sheetName=x_n, row.names=F, append=T) }
l_ply(pkp_lst,xr)
openxlsx写入Excel
l#分三步:创建工作簿--添加工作表--保存工作簿
#第一步:创建工作簿
#openxlsx写入Excel #分三步:创建工作簿--添加工作表--保存工作簿 #第一步:创建工作簿 wb<-openxlsx::createWorkbook() #第二步:创建一个新的写入函数 xr<-function(x){ x_n<-unique(x$hs) openxlsx::addWorksheet(wb,sheetName = x_n) openxlsx::writeData(wb,x_n,x) } l_ply(pkp_lst,xr) #第三步:保存工作簿 openxlsx::saveWorkbook(wb,"openxlsx-pkp.xlsx")
R的记号体系
值的选取:对于数据框,提取其中数据的语法为data.frame[i,j]
括号内有两个索引参数,逗号分隔,索引参数用来告诉R用来提取哪些值:第一个索引选择相应的行,第二个索引选择相应的列。
六种索引编写方式: #索引开始于1
正整数:返回第i行第j列的元素,要提取多个值,使用正整数向量代替单一整数作为索引;
负整数:将返回不包含负整数索引所对应的元素;
零:返回一个空对象;
空格:提取空格所在索引位置代表维度的所有元素;
逻辑值:匹配索引值为TRUE的位置并提取出相应元素,而忽略所有索引值为FALSE的位置
名称:被索引对象有名称属性时,常见于从数据框中提取列。
练习:用pkp数据练习数据值的选取。
#R的记号体系 #i代表行索引,j代表列索引 data.frame[i,j] #正整数索引 #取第四行第二列的数据 pkp<-data.frame(pm=rep(c("A",2:10,"J","Q","K"),times=4), hs=rep(c("红桃","黑桃","梅花","方块"),each=13), ds=rep(1:13,times=4), stringsAsFactors = F) # pkp[4,2] #取第四行到第六行,第三列的数据 pkp[4:6,3] pkp[4:6,3,drop=F] #取第四行和第六行,第三列的数据 pkp[c(4,6),3] #取第四行到第六行,第二列到第三列的数据 pkp[4:6,2:3] #负整数索引 #不要第四行到第六行的数据, #要第二列到第三列的数据 pkp[-(4:6),2:3] #零索引 pkp[0,0] #空格索引 #取第二行到第三行,所有列的数据 pkp[2:3, ] pkp[2:3,] pkp[2:3,1:3] #逻辑值索引 x<-c(7,9,2,5,8) #取x>3的值 x[x>3] #取x^2>4x的值 x^2 4*x x^2>4*x x[x^2>4*x] #取牌面信息为K的牌 pkp[pkp[,1]=="K",]
> #取牌面信息为K的牌 > pkp[,1]=="K" [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [9] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE [17] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [25] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE [33] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE [41] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [49] FALSE FALSE FALSE TRUE > pkp[pkp[,1]=="K",] pm hs ds 13 K 红桃 13 26 K 黑桃 13 39 K 梅花 13 52 K 方块 13
#名称索引 names(pkp) pkp[,"hs"] pkp[,c("hs","ds")]
> names(pkp) [1] "pm" "hs" "ds" > pkp[,"hs"] [1] "红桃" "红桃" "红桃" "红桃" "红桃" "红桃" "红桃" [8] "红桃" "红桃" "红桃" "红桃" "红桃" "红桃" "黑桃" [15] "黑桃" "黑桃" "黑桃" "黑桃" "黑桃" "黑桃" "黑桃" [22] "黑桃" "黑桃" "黑桃" "黑桃" "黑桃" "梅花" "梅花" [29] "梅花" "梅花" "梅花" "梅花" "梅花" "梅花" "梅花" [36] "梅花" "梅花" "梅花" "梅花" "方块" "方块" "方块" [43] "方块" "方块" "方块" "方块" "方块" "方块" "方块" [50] "方块" "方块" "方块" > pkp[,c("hs","ds")] hs ds 1 红桃 1 2 红桃 2 3 红桃 3
m[3,2] m[5] pkp[1] x[c(3,5)]
> x[c(3,5)] [1] 2 8 > # 3行2列 > m[3,2] [1] 10 > # 只有一个数字时,按照一纬的结构走1、5、9、2、6、10、 > m[5] [1] 6 > # 数据框本质是列表,取列表第一个元素 > pkp[1] pm 1 A
#在同一个维度上,不能同时使用 #正整数索引和负整数索引 x[c(-3,5)] pkp[3:4,-1]
> #在同一个维度上,不能同时使用正整数索引和负整数索引
> x[c(-3,5)]
Error in x[c(-3, 5)] : only 0's may be mixed with negative subscripts
> #数据框二维结构可以使用正整数索引和负整数索引
> pkp[3:4,-1]
hs ds
3 红桃 3
4 红桃 4
$和[[]]----提取内容
在R里面,有两种对象可以使用$和[[]]:数据框和列表。
使用方法:
$示例:pkp$value。
$解读:当使用$时,R会原封不动地提取元素,因此得到的对象不再是一个列表对象。
[[]]示例:pkp[[1]]
[[]]解读:如果使用双中括号,R则返回元素值,而不是它的列表结构。
# pkp_lst$黑桃
列表 x<-list(1:10,exp(-3:3),c(T,F,F,T)) x[[1]] #[]具有结构不变性 x[1] pkp$hs
> #$和[[]] > pkp_lst$黑桃 pm hs ds 14 A 黑桃 1 15 2 黑桃 2 16 3 黑桃 3 > x<-list(1:10,exp(-3:3),c(T,F,F,T)) > x[[1]] [1] 1 2 3 4 5 6 7 8 9 10 > #[]具有结构不变性 > x[1] [[1]] [1] 1 2 3 4 5 6 7 8 9 10 > pkp$hs [1] "红桃" "红桃" "红桃" "红桃" "红桃" "红桃" "红桃"
#命名向量
xx<-c(7,8,9)
names(xx)<-c("a","b","c")
xx<-c(a=7,b=8,c=9)
letters
names(xx)<-letters[1:3]
xx["a"]
#去除命名向量的名称属性
unname(xx["a"])
xx[["a"]]
xx[[1]]
> xx["a"]
a
7
> #去除命名向量的名称属性
> unname(xx["a"])
[1] 7
> xx[["a"]]
[1] 7
> xx[[1]]
[1]
R的记号体系总结:
#R的记号体系总结:
#()函数的触发器
#{}是由若干条程序组成的代码块
#[],[[]],$执行的是索引的操作
就地修改
就地改值:首先明确描述想要修改的数值,然后用赋值符<-更改这些值。这样R会在原始对象内部对这些值进行修改。
两个注意点:
创建一个原先对象中并不存在的新值,R会自动将对象的长度延伸以适应这个新值。它的这个用途在于提供了一种为数据集添加新变量的绝佳方法。
如果将NULL赋给从数据框中提取的变量,则相当于将该变量从数据框中删除。
> #生成一个长度为6,元素都为0的向量
> x<-numeric(6)
> x[3]<-5
> x[4:5]<-c(1,2)
> x
[1] 0 0 5 1 2 0
> x[]<-100
> x
[1] 100 100 100 100 100 100
> x[]<-c(2,3)
> x
[1] 2 3 2 3 2 3
> x<-x+100
> x
[1] 102 103 102 103 102 103
> x[1:length(x)]
[1] 102 103 102 103 102 103
> x[7]
[1] NA
> x[8]<-90
> x
[1] 102 103 102 103 102 103 NA 90
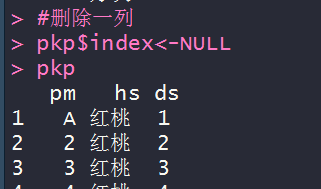
> #pkp新增一列
> pkp$index<-1:52
> pkp
pm hs ds index
1 A 红桃 1 1
2 2 红桃 2 2
3 3 红桃 3 3
逻辑表达式
逻辑取子集:R会返回索引值向量中TRUE的位置所对应的值。
目标:通过逻辑测试的方法自动生成这些TRUE和FALSE。
逻辑测试:R的七种逻辑运算符
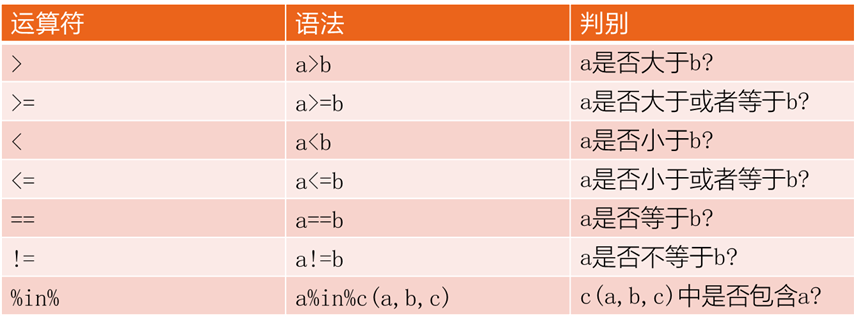
> 7!=8 [1] TRUE > 7!=c(1:8) [1] TRUE TRUE TRUE TRUE TRUE TRUE FALSE TRUE > c("小明","小花","小亮")%in%c("小刚","小明") [1] TRUE FALSE FALSE > x<-c("小明","小花","小亮") > y<-c("小刚","小明") > #找x里边有,但是y里边没有的 > x[!x%in%y] [1] "小花" "小亮" > #找x里边有,y里边也有的 > x[x%in%y] [1] "小明" > #找y里边有的,但是x里边没有的 > y[!y%in%x] [1] "小刚" > #将pm信息为3的,ds修改为100 > pkp$pm=="3" [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE [9] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE [17] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [25] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE [33] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [41] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE [49] FALSE FALSE FALSE FALSE > pkp$ds[pkp$pm=="3"]<-100 > pkp pm hs ds 1 A 红桃 1 2 2 红桃 2 3 3 红桃 100 4 4 红桃 4
布尔运算符:布尔运算符是类似于与和或这样的运算符。
R的六种布尔运算符
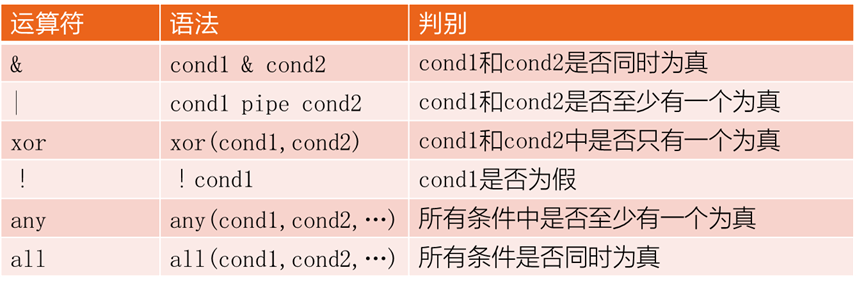
#布尔运算
#&并且
> (1>2)&(4>3)
[1] FALSE
> #|或者
> (1>2)|(4>3)
[1] TRUE
> #xor异或 是否只有一个为真
> xor(1>2,3>4)
[1] FALSE
> xor(1>2,3<4)
[1] TRUE
> #!非运算 是否为假
> !(2>1)
[1] FALSE
> !FALSE
[1] TRUE
> #any,所有的条件中是否至少有一个为真
> any(c(T,F,F,F,F))
[1] TRUE
> #all,所有的条件是否同时为真
> all(c(T,T,T,T,F))
[1] FALSE
>
> #将pm信息为黑桃3的点数修改为500
两个条件:pm==3,hs==黑桃
> pkp$ds[pkp$pm=="3" & pkp$hs=="黑桃"]<-500
> pkp
pkp$pm=="3" & pkp$hs=="黑桃"

练习题

pkp<-data.frame(pm=rep(c("A",2:10,"J","Q","K"),times=4), hs=rep(c("红桃","黑桃","梅花","方块"),each=13), ds=rep(1:13,times=4), stringsAsFactors = F) #pkp$pm=="A" # 第一题:取出扑克牌中四个A(4行3列) pkp[pkp$pm=="A",]
# 第二题: pkp$pm=="A"

sum(pkp$pm=="A")

# 第三题:
pkp$hs=="红桃"
pkp[pkp$hs=="红桃",]
# 思考题:
pkp$pm=="Q"&pkp$hs=="黑桃"
pkp[pkp$pm=="Q"&pkp$hs=="黑桃",]

练习:把黑桃和方块里边的J和Q的点数修改为10
p_1<-pkp$hs %in% c("黑桃","方块")
p_2<-pkp$pm %in% c("J","Q")
pkp$ds[p_1&p_2]<-10
缺失值
缺失值的发生:丢失、破坏或者测量并没有发生。
NA:R中用NA代表不可用(not available)。
默认机制:通常,在R运算或者R函数中,NA会原封不动地保留和传送。
设置参数na.rm=T:将NA移除,然后进行计算。
is.na:通过逻辑测试定位缺失值的位置。
> #缺失值
> is.na(c(3,5,NA))
[1] FALSE FALSE TRUE
> x<-c(3,5,NA)
> x[!is.na(x)]
[1] 3 5
> x[is.na(x)]
[1] NA
> is.na(x)
x<-c(3,5,NA)
> x==NA [1] NA NA NA > #识别一个向量里边缺失值的个数 > sum(is.na(x)) [1] 1 > #移除缺失值 > sum(x,na.rm = T) [1] 8 > #查看数据的统计摘要 > summary(x) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 3.0 3.5 4.0 4.0 4.5 5.0 1 >