------------恢复内容开始------------

获取数据的方式:
企业生产的用户数据
数据管理咨询公司
政府/机构提供的公开数据
第三方数据平台购买数据
爬虫爬取数据
requests模块
resp.text返回的是Unicode型的数据。
resp.content返回的是bytes型也就是二进制的数据。
也就是说,如果你想取文本,可以通过r.text。
如果想取图片,文件,则可以通过r.content。
import requests # 1.指定url url = 'https://www.sogou.com/' # 不带参数 # 2.发起一个get请求,get方法会返回 请求成功后的响应对象 response = requests.get(url=url) # 3.获取响应中的数据值:text可以获取响应对象中的字符串形式的页面数据 page_data = response.text #print(page_data) # 持久化操作 with open('./sogou.html','w',encoding='utf-8')as f: f.write(page_data)
get请求 # 将参数封装到字典中 params = {'query':'周杰伦','ie':'utf8'}
# 自定义请求头信息 # 此处用的百度的UA headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
# 拿到响应对象 response = requests.get(url=url,params=params,headers=headers) post请求 # 封装post请求的参数 data = { 'source':'movie', 'redir':'https://movie.douban.com/', 'form_email':'你的豆瓣邮箱', 'form_password':'你的登录密码', 'login':'登录', } response = requests.post(url=url,data=data,headers=headers)
发送cookies:需要登陆验证的网站需要带上cookies
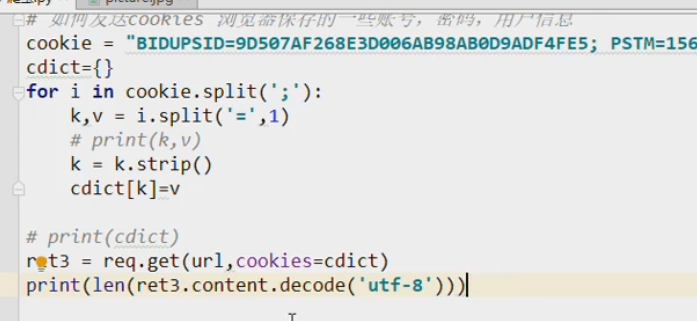
代理ip
import requests # https://www.dogedoge.com/results?q=ip url = 'https://www.dogedoge.com/results?' params = {'q':'ip'} headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 将代理ip封装到字典中
proxy = {
'http':'117.88.176.110:3000'
}
# 更换网络ip,发起请求之前 response = requests.get( url=url,proxies=proxy,headers=headers,params=params) with open('./daili2.html','w',encoding='utf-8')as f: f.write(response.text)
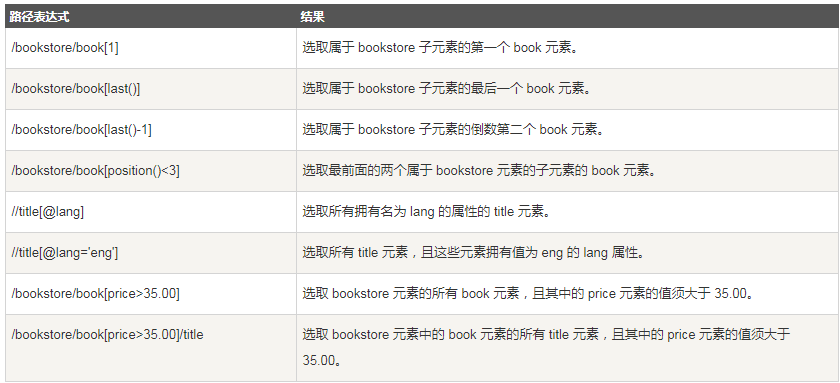
xpath里如何定义包含一个或多个class属性
xpath解析
# 打印文本值 px3 = html.xpath('/html/head/title/text()')# 在路径表达式中使用text()方法 print(px3[0]) px4 = html.xpath('/html/head/title') # 返回的是元素节点 print(px4[0].text)# 用元素节点的text属性打印 px5 = html.xpath('/html/body/div/p')#p元素组成的列表 for p in px5: print(p.text)
爬取数据存入数据库
(1)单行存储
(2)批量存储
#建立连接 conn = MySQLdb.connect(host='127.0.0.1',user='root',passwd='1qaz#EDC',db='test_db') cur = conn.cursor() #对数据进行操作 li = [('tanzhenx','shaoguan'),('huangmengdie','shaoguan')] #定义一个列表,列表中含多个元组,等会批量插入每个元组中的数据 cur.executemany('insert into user (name,address) values(%s,%s)',li) #批量插入数据 conn.commit() #提交请求,否则数据是不会写入数据库里 #关闭数据库连接 cur.close() conn.close()
动态爬取数据
------------恢复内容结束------------