1、查找最晚入职员工的所有信息
CREATE TABLE `employees` ( `emp_no` int(11) NOT NULL, `birth_date` date NOT NULL, `first_name` varchar(14) NOT NULL, `last_name` varchar(16) NOT NULL, `gender` char(1) NOT NULL, `hire_date` date NOT NULL, 只有年月日 PRIMARY KEY (`emp_no`));
所以同一入职的或许有很多人,order by files asc limit 1 是错误的
最晚入职的时间是最大的
select * from employees where hire_date = (select max(hire_date) from employees );
--------------------------------------------------------------------
mysql的日期类型分析
create table student(
id int,
name char(6),
born_year year,
birth_date date,
class_time time,
reg_time datetime
);
insert into student values
(1,'egon',now(),now(),now(),now());
insert into student values
(2,'alex',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12");
2、查找入职员工时间排名倒数第三的员工所有信息
CREATE TABLE `employees` ( `emp_no` int(11) NOT NULL, `birth_date` date NOT NULL, `first_name` varchar(14) NOT NULL, `last_name` varchar(16) NOT NULL, `gender` char(1) NOT NULL, `hire_date` date NOT NULL, PRIMARY KEY (`emp_no`));
select * from employees where hire_date = (select hire_date from employees order by hire_date desc limit 2,1 ); 注意limit 后面的 (n,m) n指索引 m是步长
3、对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列 CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL, `salary` int(11) NOT NULL, `from_date` date NOT NULL, `to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`from_date`));
能通过是因为dense_rank系统默认两人成绩相同,按学号小的靠前放,排名都相同
下面这种也可以:


用到并列函数:
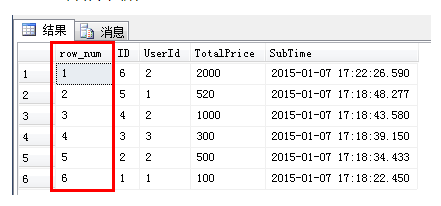
1、row_number的用途的非常广泛,排序最好用他,一般可以用来实现web程序的分页,他会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
row_nomber() over(order by)
select ROW_NUMBER() OVER(order by [SubTime] desc) as row_num,* from [Order]
2、rank
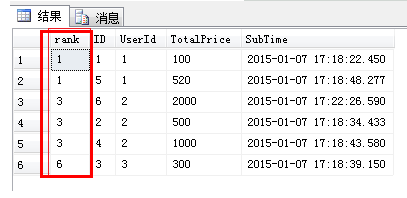
如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一
select RANK() OVER(order by [UserId]) as rank,* from [Order]
3、dense_rank
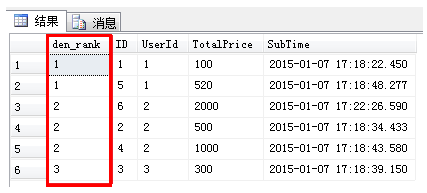
rank()是跳跃排序,有两个第一名时接下来就是第3名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名
select DENSE_RANK() OVER(order by [UserId]) as den_rank,* from [Order]
4、汇总各个部门当前员工的title类型的分配数目,结果给出部门编号dept_no、dept_name、其当前员工所有的title以及该类型title对应的数目count
CREATE TABLE `departments` ( `dept_no` char(4) NOT NULL, `dept_name` varchar(40) NOT NULL, PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` ( `emp_no` int(11) NOT NULL, `dept_no` char(4) NOT NULL, `from_date` date NOT NULL, `to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE IF NOT EXISTS `titles` ( `emp_no` int(11) NOT NULL, `title` varchar(50) NOT NULL, `from_date` date NOT NULL, `to_date` date DEFAULT NULL);
select d.dept_no,d.dept_name,t.title, count(t.emp_no)'count' from
departments d ,dept_emp de,titles t where
d.dept_no=de.dept_no and de.emp_no=t.emp_no
and de.to_date='9999-01-01' and t.to_date='9999-01-01'
group by d.dept_no, title; 同时以两个字段进行分组
主要是要对dept_no和title进行分组
5、from后面接两个相同的表s1,s2
给出每个员工每年薪水涨幅超过5000的员工编号emp_no、薪水变更开始日期from_date以及薪水涨幅值salary_growth,并按照salary_growth逆序排列。 提示:在sqlite中获取datetime时间对应的年份函数为strftime('%Y', to_date) CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL, `salary` int(11) NOT NULL, `from_date` date NOT NULL, `to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`from_date`));
select s1.emp_no,s1.from_date,(s1.salary-s2.salary) salary_growth from
salaries s1,salaries s2
where
s1.emp_no=s2.emp_no
and
strftime('%Y',s1.to_date) - strftime('%Y',s2.to_date) = 1
and s1.salary-s2.salary>5000 order by salary_growth desc;