
需求:爬取的是基于文字的新闻数据(国内,国际,军事,航空)

先编写基于scrapycrawl
先创建工程
scrapy startproject 58Pro
cd 58Pro
新建一个爬虫--基于一个scrapy
scrapy genspider 58 www.xxx.com
先把基本功能测试完:再进行修改

selenium在scrapy中的应用
引入:
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,
是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出
的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行
请求发送,获取动态加载的数据值。
---
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,
是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,
引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载
的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了
动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
1.重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
2.重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用

3.重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
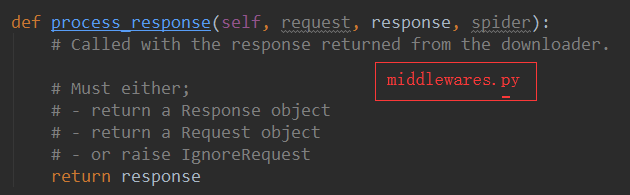
重写为:
4.在配置文件中开启下载中间件

-----
中间件中的重写
#拦截到响应对象(下载器传递给Spider的响应对象) #request:响应对象对应的请求对象 #response:拦截到的响应对象 #spider:爬虫文件中对应的爬虫类的实例 def process_response(self, request, response, spider): #响应对象中存储页面数据的篡改 if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']: spider.bro.get(url=request.url) js = 'window.scrollTo(0,document.body.scrollHeight)' spider.bro.execute_script(js) time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间 #页面数据就是包含了动态加载出来的新闻数据对应的页面数据 page_text = spider.bro.page_source #篡改响应对象 return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request) else: return response
--------
基于scrapy-redis的第二种形式的分布式爬虫:
1. 基于RedisSpider实现的分布式爬虫(网易新闻) a) 代码修改(爬虫类): i. 导包:from scrapy_redis.spiders import RedisSpider ii. 将爬虫类的父类修改成RedisSpider iii. 将起始url列表注释,添加一个redis_key(调度器队列的名称)的属性
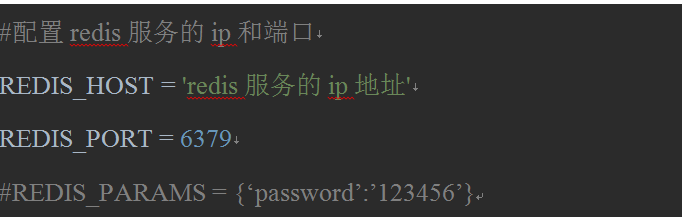
b) redis数据库配置文件的配置redisxxx.conf: i. #bind 127.0.0.1 ii. protected-mode no c) 对项目中settings进行配置:
iii可以被共享的管道



2.UA池:
a) 在中间价类中进行导包:

b) 封装一个基于UserAgentMiddleware的类,且重写该类的process_requests方法
- 代理池:注意请求url的协议后到底是http·还是https
- selenium如何被应用到scrapy
a) 在爬虫文件中导入webdriver类
b) 在爬虫文件的爬虫类的构造方法中进行了浏览器实例化的操作
c) 在爬虫类的closed方法中进行浏览器关闭的操作
d) 在下载中间件的process_response方法中编写执行浏览器自动化的操作


user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ]
proxy = {}
UA池和代理池在scrapy中的应用
一.下载中间件
一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件。 - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系列处理。比如设置请求的 User-Agent,设置代理等 (2)在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理。比如进行gzip解压等。
我们主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent ,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
二.UA池:User-Agent池
- 作用:尽可能多的将scrapy工程中的请求伪装成不同类型的浏览器身份。 - 操作流程: 1.在下载中间件中拦截请求 2.将拦截到的请求的请求头信息中的UA进行篡改伪装 3.在配置文件中开启下载中间件
--
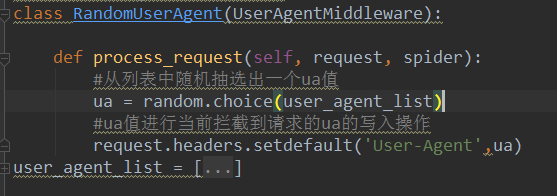
#UA池代码的编写(单独给UA池封装一个下载中间件的一个类) #1,导包UserAgentMiddlware类 class RandomUserAgent(UserAgentMiddleware): def process_request(self, request, spider): #从列表中随机抽选出一个ua值 ua = random.choice(user_agent_list) #ua值进行当前拦截到请求的ua的写入操作 request.headers.setdefault('User-Agent',ua)
==================================================================================
在settings.py进行配置

三.代理池
- 作用:尽可能多的将scrapy工程中的请求的IP设置成不同的。 - 操作流程: 1.在下载中间件中拦截请求 2.将拦截到的请求的IP修改成某一代理IP 3.在配置文件中开启下载中间件
-----
#批量对拦截到的请求进行ip更换 class Proxy(object): def process_request(self, request, spider): #对拦截到请求的url进行判断(协议头到底是http还是https) #request.url返回值:http://www.xxx.com h = request.url.split(':')[0] #请求的协议头 if h == 'https': ip = random.choice(PROXY_https) request.meta['proxy'] = 'https://'+ip else: ip = random.choice(PROXY_http) request.meta['proxy'] = 'http://' + ip PROXY_http = [ '190.90.45.2:37333', '221.180.214.70:80', '103.27.24.114:80', '219.141.153.44:80', '112.253.22.161:80', ] PROXY_https = [ '59.127.168.43:3128', '95.189.112.214:35508', '91.235.186.91:37757', '213.80.165.26:31532', '121.33.220.158:808', ]
在settings.py

完整代码:
wangyi.py
# -*- coding: utf-8 -*- import scrapy from wangyiPro.items import WangyiproItem from selenium import webdriver from scrapy_redis.spiders import RedisSpider from wangyiPro import settings class WangyiSpider(RedisSpider): name = 'wangyi' #allowed_domains = ['www.news.163.com'] #start_urls = ['https://news.163.com'] redis_key = 'wangyi' def __init__(self): # 实例化一个浏览器对象(实例化一次) self.bro = webdriver.Chrome(executable_path=settings.chrome_path) def close(self, spider): print('爬虫结束') self.bro.quit() def parse(self, response): lis = response.xpath('//div[@class="ns_area list"]/ul/li') li_list = [] indexs = [3,4,6,7] for index in indexs: li_list.append(lis[index]) # 获取四个板块中的链接和文字标题 for li in li_list: url = li.xpath('./a/@href').extract_first() title = li.xpath('./a/text()').extract_first() print(url+':'+title) # 对每一个板块对应的url发起请求,获取页面数据(标题,缩略图,关键字,发布时间,url) yield scrapy.Request(url=url, callback=self.parseSecond, meta={'title': title}) def parseSecond(self,response): # 获取页面数据(标题,缩略图,关键字,发布时间,url) # //div是定位所有div 加属性就是定位到所有符合条件的div div_list = response.xpath("//div[@class='data_row news_article clearfix']") # 因为是动态加载数据,所以没有生效使用selenium获得动态加载 # print(len(div_list))===》0 print(len(div_list)) for div in div_list: # .表示当前目录 head = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first() print(head) url = div.xpath('.//div[@class="news_title"]/h3/a/@href').extract_first() imgUrl = div.xpath('./a/img/@src').extract_first() tag = div.xpath('.//div[@class="news_tag"]//text()').extract print('tag',tag) tags = [] for t in tag: t = t.strip(' ') tags.append(t) tag = "".join(tags) # 获取meta传递过来的数据值title title = response.meta['title'] # 实例化item对象,将解析到的数据值存储到item对象中 item = WangyiproItem() item['head'] = head item['url'] = url item['imgUrl'] = imgUrl item['tag'] = tag item['title'] = title # 对url发起请求,获取对应页面中存储的新闻内容数据 print(head + ":" + url + ":" + imgUrl + ":" + tag) yield scrapy.Request(url=url, callback=self.getContent, meta={'item': item}) def getContent(self,response): item = response.meta['item'] # xpath()得到的是list content_list = response.xpath('//div[@class="post_text"]/p/text()').extarct content = ''.join(content_list) item['item'] = content yield item
管道 pipelines.py
class WangyiproPipeline(object): def process_item(self, item, spider): print(item['title'] + ':' + item['content']) return item
items.py
import scrapy class WangyiproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() head = scrapy.Field() url = scrapy.Field() imgUrl = scrapy.Field() tag = scrapy.Field() title = scrapy.Field() content = scrapy.Field()
执行流程:
1、打开redis服务器
2、执行爬虫文件


3、打开redis客户端
向调度器队列仍一个起始url
redis_key = 'wangyi'
lpush wangyi https://news.163.com
redis服务器配置处理问题(windows版本)
解压:

在配置文件中修改:

protected-mode no #bind 127.0.0.1
启动服务器的形式
重新启动redis服务,要想配置文件起效,启动的时候,必须指定配置文件
windows下启动redis服务器
redis-server redis.windows.conf

-------------------------------------------------

在从机中打开redis客户端
可以直接点击

如果要增加redis的访问密码,修改配置文件/etc/redis.conf
requirepass passwrd
增加了密码后,启动客户端的命令变为:redis-cli -a passwrd
测试是否能远程登陆
cmd中的命令
d:
cd 文件夹
使用 windows 的命令窗口进入 redis 安装目录,用命令进行远程连接 redis:
redis-cli -h 192.168.1.112 -p 6379

从机测试成功
可以确信 redis 配置完成
数据存储 scrpay-redis 默认情况下会将爬取到的目标数据写入 redis 利用 Python 丰富的数据库接口支持可以通过 Pipeline 把 Item 中的数据存放在任意一种常见的数据库中
Scrapy 是一个优秀的爬虫框架。性能上,它快速强大,多线程并发与事件驱动的设计能将爬取效率提高几个数量级;功能上,它又极易扩展,支持插件,无需改动核心代码。但如果要运用在在大型爬虫项目中,不支持分布式设计是它的一个大硬伤。幸运的是,scrapy-redis 组件解决了这个问题,并给 Scrapy 带来了更多的可能性。 作者:无口会咬人 链接:https://www.jianshu.com/p/cd4054bbc757 來源:简书 简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
多态从机测试分布式:‘’
