如何发起post请求?
代理和cookie:
cookie:豆瓣网个人登录,获取该用户个人主页这个二级页面的页面数据。
如何发起post请求?
一定要对start_requests方法进行重写。
1. Request()方法中给method属性赋值成post
2. FormRequest()进行post请求的发送
简单测试:
在爬虫文件中
import scrapy class PostdemoSpider(scrapy.Spider): name = 'postDemo' #allowed_domains = ['www.baidu.com'] start_urls = ['https://fanyi.baidu.com/sug'] def start_requests(self): print('start_request') data ={'kw':'dog'} for url in self.start_urls: yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) def parse(self, response): print(response.text)
在settings配置
然后执行:

cookie:豆瓣网个人登录,获取该用户个人主页这个二级页面的页面数据。
先创建一个工程doubanPro

cd 到创建的目录下

----------
创建爬虫文件
1. 在命令行下 cd 进入工程所在文件夹
2.scrapy genspider 爬虫文件的名称 起始url

爬虫文件 douban.py
import scrapy class DoubanSpider(scrapy.Spider): name = 'douban' # allowed_domains = ['www.douban.com'] start_urls = ['https://accounts.douban.com/login'] # 重写start_requests方法 def start_requests(self): for url in self.start_urls: # 排除验证码的情况 将请求参数封装到字典 data = { 'source': 'movie', 'redir': 'https://movie.douban.com /', 'form_email': '836342406@qq.com', 'form_password': 'douban836342406,.', 'login': '登录' } yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) # 针对个人主页数据进行解析操作 def parseBySecondPage(self,response): fp = open('second.html','w',encoding='utf-8') fp.write(response.text) def parse(self, response): # 登录成功后的页面进行存储 fp = open('main.html','w',encoding='utf-8') fp.write(response.text) # 获取当前用户的个人主页 url = 'https://www.douban.com/people/188197188/' yield scrapy.Request(url=url,callback=self.parseBySecondPage)
执行

代理操作-代理ip的更换
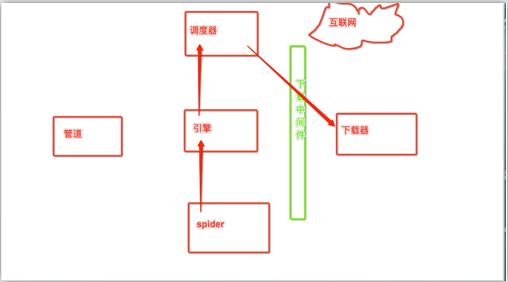
下载中间件作用:拦截请求,可以将请求的ip进行更换。 流程: 1. 下载中间件类的自制定 a) object b) 重写process_request(self,request,spider)的方法 2. 配置文件中进行下载中间价的开启
新建一个proxyPro的工程
建立proxyDemo.py爬虫文件
1、下载中间件类的自定义
proxyDemo.py
import scrapy class ProxydemoSpider(scrapy.Spider): name = 'proxyDemo' #allowed_domains = ['www.baidu.com'] start_urls = ['https://www.baidu.com/s?wd=ip'] def parse(self, response): fp = open('proxy.html','w',encoding='utf-8') fp.write(response.text)
middlewares.py
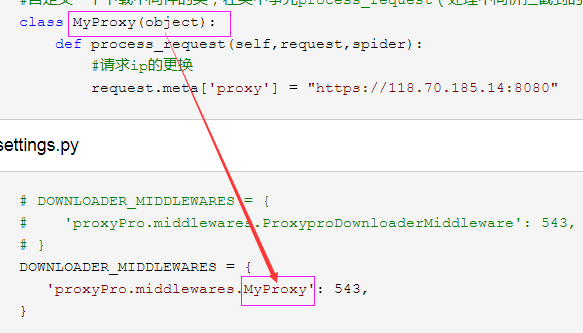
from scrapy import signals #自定义一个下载中间件的类,在类中事先process_request(处理中间价拦截到的请求)方法 class MyProxy(object): def process_request(self,request,spider): #请求ip的更换 request.meta['proxy'] = "https://118.70.185.14:8080"
代理ip------------>"https://118.70.185.14:8080"

settings.py
# DOWNLOADER_MIDDLEWARES = { # 'proxyPro.middlewares.ProxyproDownloaderMiddleware': 543, # } DOWNLOADER_MIDDLEWARES = { 'proxyPro.middlewares.MyProxy': 543, }