SELECT INTO 语句 复制表结构、数据
MySQL不支持`SELECT * INTO target_table FROM`语句进行复制(无论目标表存在与否)
-- 复制表结构及数据到新表 CREATE TABLE 新表 SELECT * FROM 旧表 -- Statement violates GTID consistency: CREATE TABLE … SELECT(阿里云服务器执行报错) -- create table 新表 like 旧表;insert into 新表 select * from 旧表 -- 只复制表结构到新表 CREATE TABLE 新表 LIKE 旧表 或 CREATE TABLE 新表 SELECT * FROM 旧表 WHERE 1=2 -- 复制旧表的数据到新表(表结构一致,目标表存在) INSERT INTO 新表 SELECT * FROM 旧表 -- 将旧表的创建命令列出。我们只需要将该命令拷贝出来,更改table的名字,就可以建立一个完全一样的表 show create table 旧表;
查看库中视图、函数、存储过程,表字段
查询一个表中的所有字段
SELECT GROUP_CONCAT(COLUMN_NAME) FROM information_schema.COLUMNS -- WHERE -- table_name = 'tablename' AND -- table_schema = 'dbname'
查询以tb(table)开头的表中哪些含有id字段。
SELECT TABLE_NAME,COLUMN_NAME FROM information_schema.COLUMNS WHERE COLUMN_NAME = 'id' AND TABLE_NAME LIKE 'tb%'
数据库表文档等,可将查询结果复制到excell,再粘贴到word(带有网格)
SELECT COLUMN_NAME, COLUMN_TYPE, COLUMN_COMMENT FROM information_schema.COLUMNS WHERE table_name = ?
查看库中视图、函数、存储过程等
-- 查询数据库中所有函数、存储过程等 常规信息 SELECT * FROM information_schema.Routines -- WHERE -- ROUTINE_NAME = 'batch_code' -- routine_type = 'FUNCTION' A00100010001-A00100020000 -- 查询某个 具体名称 的存储过程的信息,包括创建语句 SHOW CREATE PROCEDURE/FUNCTION 存储过程名/函数名; -- 查看存储过程/函数状态 SHOW PROCEDURE/FUNCTION STATUS -- LIKE 存储过程名/函数名; -- 查看触发器 SHOW TRIGGERS -- 查看视图 SELECT * from information_schema.VIEWS -- 表 SELECT * from information_schema.TABLES
group_concat()函数完整语法
group_concat([DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Separator '分隔符'])
concat()函数
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
concat_ws()函数
1、功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
2、语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
修改表ALTER TABLE
# 修改表名 ALTER TABLE zz_c RENAME TO z_test RENAME TABLE z_test TO zz_test -- 添加列 ALTER TABLE zz_test ADD COLUMN age1 int(3) DEFAULT NULL COMMENT "年龄" AFTER age -- 删除列 ALTER TABLE zz_test DROP COLUMN age1 -- 修改列定义 ALTER TABLE zz_test MODIFY COLUMN `name` VARCHAR(12) DEFAULT "无名氏" COMMENT "名字" AFTER id -- 修改列名称与定义 ALTER TABLE zz_test CHANGE COLUMN `name` c_name VARCHAR(8) DEFAULT "无名" COMMENT "名字1" AFTER age
sql语句执行顺序
(1)from
(3) join
(2) on
(4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by
https://www.cnblogs.com/yyjie/p/7788428.html
in exists
区别及应用场景
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
https://blog.csdn.net/wqc19920906/article/details/79800374
https://www.cnblogs.com/xuanhai/p/5810918.html
查找某字段是否包含子字符串
SELECT INSTR(str,substr) SELECT LOCATE(substr,str) SELECT POSITION(substr IN str)
如查找省市,表连接后contact地域省市县名称,where如上函数搜索或者模糊搜索
mysql函数:ifnull(); nullif(); isnull()
https://blog.csdn.net/xingyu0806/article/details/52080962
1、空值不占空间,NULL值占空间。当字段不为NULL时,也可以插入空值。
2、当使用 IS NOT NULL 或者 IS NULL 时,只能查出字段中没有不为NULL的或者为 NULL 的,不能查出空值。
3、判断NULL 用IS NULL 或者 is not null,SQL 语句函数中可以使用IFNULL()函数来进行处理,判断空字符用 =''或者<>''来进行处理。
4、在进行count()统计某列的记录数的时候,如果采用的NULL值,会别系统自动忽略掉,但是空值是会进行统计到其中的。
5、对于MySQL特殊的注意事项,对于timestamp数据类型,如果往这个数据类型插入的列插入NULL值,则出现的值是当前系统时间。插入空值,则会出现 '0000-00-00 00:00:00'
MySQL多表连接 & 删除
https://www.jianshu.com/p/3cfb4be3cd3c
https://blog.csdn.net/zalan01408980/article/details/80529931
https://www.jb51.net/article/150323.htm
COALESCE函数
select COALESCE(null, null, 0, 2) 返回0
作用 返回其参数中第一个非空表达式。
-- 判断一个字段是否为null SELECT null <=> null FROM DUAL SELECT null is null SELECT ISNULL(NULL) SELECT IFNULL(NULL, 0) SELECT COALESCE(null, 0) -- NULL处理为空值 SELECT IF(!(null <=> null), '', 'column_val') -- 等价于 SELECT IFNULL(null, 'column_val')
SQL获取某天最早最晚一秒
-- 获取某天最早最晚一秒的时间 SELECT str_to_date(DATE_FORMAT(NOW(),'%Y-%m-%d'),'%Y-%m-%d %H:%i:%s'); SELECT DATE_FORMAT(CURDATE(), '%Y-%m-%d %H:%i:%s') SELECT DATE_ADD(DATE_ADD(str_to_date(DATE_FORMAT(NOW(),'%Y-%m-%d'),'%Y-%m-%d %H:%i:%s'),INTERVAL 1 DAY),INTERVAL -1 SECOND)
mysql 中 <=> := @ @@含义
备侵删:https://www.liangzl.com/get-article-detail-6485.html
<=>
安全比较运算符,用来做 NULL 值的关系运算。
因为 mysql 的 NULL 值的特性,任何值和其比较的结果都是 NULL, 1 = NULL,1 <> NULL / 1 != NULL 得到的结果都是 NULL。
可以用 IS NULL 去判断,但用 <=> 更为简洁。
:=
:= 和 = 运算符在大部分场景下并无区别,但 := 更为全场景些。
= 只有在 set 和update时才是和 := 一样,赋值的作用,其它都是关系运算符 等于 的作用。
:= 不只在 set 和 update 时赋值的作用,在 select 也是赋值的作用。
SET @name = 'big_cat'; SELECT @name; # = 在 select 语句中成为了比较运算符 结果为 NULL (@name 为 NULL, 在 mysql 中 NULL 和任何值比较都为 NULL) # := 则为仍未赋值,@name_defined 被赋值为 big_cat 后再 select 就出来了 SELECT @name = 'big_cat', @name_defined := 'big_cat', @name_defined; +-------------------+----------------------------+---------------+ | @name = 'big_cat' | @name_defined := 'big_cat' | @name_defined | +-------------------+----------------------------+---------------+ | NULL | big_cat | big_cat | +-------------------+----------------------------+---------------+ 1 row in set (0.00 sec)
@ 用户变量
@用来标识用户变量
@@系统变量
系统变量又分为全局系统变量和会话系统变量
-- 查看当前数据库的自增长设置 SHOW VARIABLES LIKE 'auto_increment%'; -- 将自增长步长设置为1 SET @@auto_increment_increment=1; -- 将自增长开始值设置为1000 SET @@auto_increment_offset=1000; -- 查看自增初始值 SELECT @@auto_increment_offset;
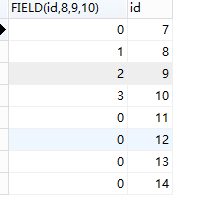
mysql排序函数FIELD()
MySQL可以通过field()函数自定义排序
格式:
FIELD(str,str1,str2,str3,...)
value与str1、str2、str3比较,返回1、2、3……,如遇到null或者不在列表中的数据则返回0
mysql 随机数、随机字符串
随机数保留小数2位
四舍五入:round(rand() * 100, 2)
格式化(四舍五入):format(x, 2)
截断(舍弃小数):truncate(x, 2)
类型转换函数:convert(expr, type) -- convert(x, decimal(10,2))
生成随机字符串。
这里如果是生成随机的小写字母+数字,可以用以下这个简便方法做。(利用md5函数进行实现)
在mysql中这样实现:select substring(md5(rand()),1,10);
以上函数实现,随机取得小写字母+数字的10位字符串。
存储过程procedure初始化1w条测试数据
DROP PROCEDURE IF EXISTS proc_initData; DELIMITER $ CREATE PROCEDURE proc_initData() BEGIN DECLARE i INT DEFAULT 1; WHILE i<=10000 DO INSERT INTO zz_test(id, name, age, score) VALUES(i + 20000, SUBSTR(MD5(RAND()), 1, 10), FLOOR(RAND() * 100), ROUND(RAND() * 100, 1)); SET i = i+1; END WHILE; END $ CALL proc_initData();
.mysql初始化编号类型。字符串加规律数字
delimiter @ DROP PROCEDURE if EXISTS batch_code @ create PROCEDURE batch_insert() BEGIN DECLARE code_suf int default 10001; DECLARE code_pre VARCHAR(20); set code_pre = 'CODE_TEST_00100'; WHILE code_suf <= 20000 DO INSERT INTO test(codes, create_time) value(CONCAT(code_pre, code_suf), NOW()); set code_suf = code_suf + 1; END WHILE; END @ delimiter ; CALL batch_insert();
-- 创建的时候把这个字段设置为当前时间,但以后修改时,不再刷新它 `create_time` TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' -- 创建的时候把这个字段设置为空或定值,以后修改时刷新它 `update_time` TIMESTAMP DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
一篇文章看懂mysql中varchar能存多少汉字、数字,以及varchar(100)和varchar(10)的区别
从官方文档中我们可以得知当varchar大于某些数值的时候,其会自动转换为text,大概规则如下:
- 大于varchar(255)变为 tinytext
- 大于varchar(500)变为 text
- 大于varchar(20000)变为 mediumtext
官方文档The BLOB and TEXT Types一节中查找到:LONG and LONG VARCHAR map to the MEDIUMTEXT data type. This is a compatibility feature.
列转行、行转列pivot
表数据有时间(秒级)、销售额,统计年销售额、每月销售额、根据月份排序。
mysql无pivot函数,模拟如下。
select MONTH(date) AS '月份', CASE MONTH(date) WHEN 1 THEN sum(sales) WHEN 2 THEN sum(sales) WHEN 3 THEN sum(sales) WHEN 4 THEN sum(sales) WHEN 5 THEN sum(sales) else 0 END as '月销售额' , YEAR(date) '年份', (SELECT sum(sales) FROM pivot WHERE YEAR(date) = 2020) AS '年销售额' FROM pivot WHERE YEAR(date) = 2020 GROUP BY MONTH(date)
统计各大洲人口
SELECT * FROM `population`; SELECT COLUMN_name FROM information_schema.COLUMNS WHERE TABLE_NAME = 'population'; -- 获取所有国家 中国,美国,加拿大,印度,德国,日本,法国,英国 SELECT GROUP_CONCAT(country), sum(1) from population; SELECT case country WHEN '中国' THEN '亚洲' WHEN '美国' THEN '美洲' WHEN '加拿大' THEN '美洲' WHEN '印度' THEN '亚洲' WHEN '日本' THEN '亚洲' WHEN '德国' THEN '欧洲' WHEN '法国' THEN '欧洲' WHEN '英国' THEN '欧洲' ELSE '' END AS dalu, SUM(population) sum_pop FROM `population` GROUP BY dalu -- case country WHEN '中国' THEN '亚洲' -- WHEN '美国' THEN '美洲' -- WHEN '加拿大' THEN '美洲' -- WHEN '印度' THEN '亚洲' -- WHEN '日本' THEN '亚洲' -- WHEN '德国' THEN '欧洲' -- WHEN '法国' THEN '欧洲' -- WHEN '英国' THEN '欧洲' -- ELSE '' END
mysql时区
-- 查询数据库版本 SELECT VERSION(); -- 查看数据库时区 show VARIABLES like '%time_zone%';
mysql8.0和之前版本的区别,首先驱动换了,不是com.mysql.jdbc.Driver,而是com.mysql.cj.jdbc.Driver,此外mysql8.0不需要建立ssl连接的,需要显示关闭。最后需要设置CST的时区问题。&zeroDateTimeBehavior:
java.sql.SQLException: Cannot convert value '0000-00-00 00:00:00' from column XX to TIMESTAMP
0000-00-00不能正确的转换为时间戳,convert to null(指定转换为null)
driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://xxx?useSSL=false&serverTimezone=Asia/Shanghai&zeroDateTimeBehavior=convertToNull
数据库系统时间区别
-- SYSDATE 执行完动态获取; NOW()执行前获取,两值相同。 SELECT NOW(), SLEEP(2), SYSDATE(), NOW()
待续