参考:spark连接外部Hive应用
如果想连接外部已经部署好的Hive,需要通过以下几个步骤。
1) 将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。
2) 打开spark shell,注意带上访问Hive元数据库的JDBC客户端(找到连接hive元mysql数据库的驱动)
$ bin/spark-shell --jars mysql-connector-java-5.1.27-bin.jar
这里用的是pyspark
[root@hadoop02 spark]# bin/pyspark --jars /opt/module/hive/lib/mysql-connector-java-5.1.27-bin.jar
测试命令行操作
操作完成后可以成功打开:[root@hadoop02 spark]# bin/pyspark --jars /opt/module/hive/lib/mysql-connector-java-5.1.27-bin.jar
Python 2.7.5 (default, Apr 2 2020, 13:16:51) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux2 Type "help", "copyright", "credits" or "license" for more information. Warning: Ignoring non-spark config property: export=JAVA_HOME=/opt/module/jdk1.8.0_144 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 21/01/09 22:23:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/01/09 22:23:31 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_ version 2.1.1 /_/ Using Python version 2.7.5 (default, Apr 2 2020 13:16:51) SparkSession available as 'spark'.
## ## 测试spark建表 >>> from pyspark.sql import HiveContext,SparkSession >>> hive_sql=HiveContext(spark) >>> hive_sql.sql(''' create table test_youhua.test_pyspark_creat_tbl like test_youhua.youhua1 ''') 21/01/09 22:26:48 WARN metastore.HiveMetaStore: Location: hdfs://hadoop02:9000/user/hive/warehouse/test_youhua.db/test_pyspark_creat_tbl specified for non-external table:test_pyspark_creat_tbl DataFrame[]
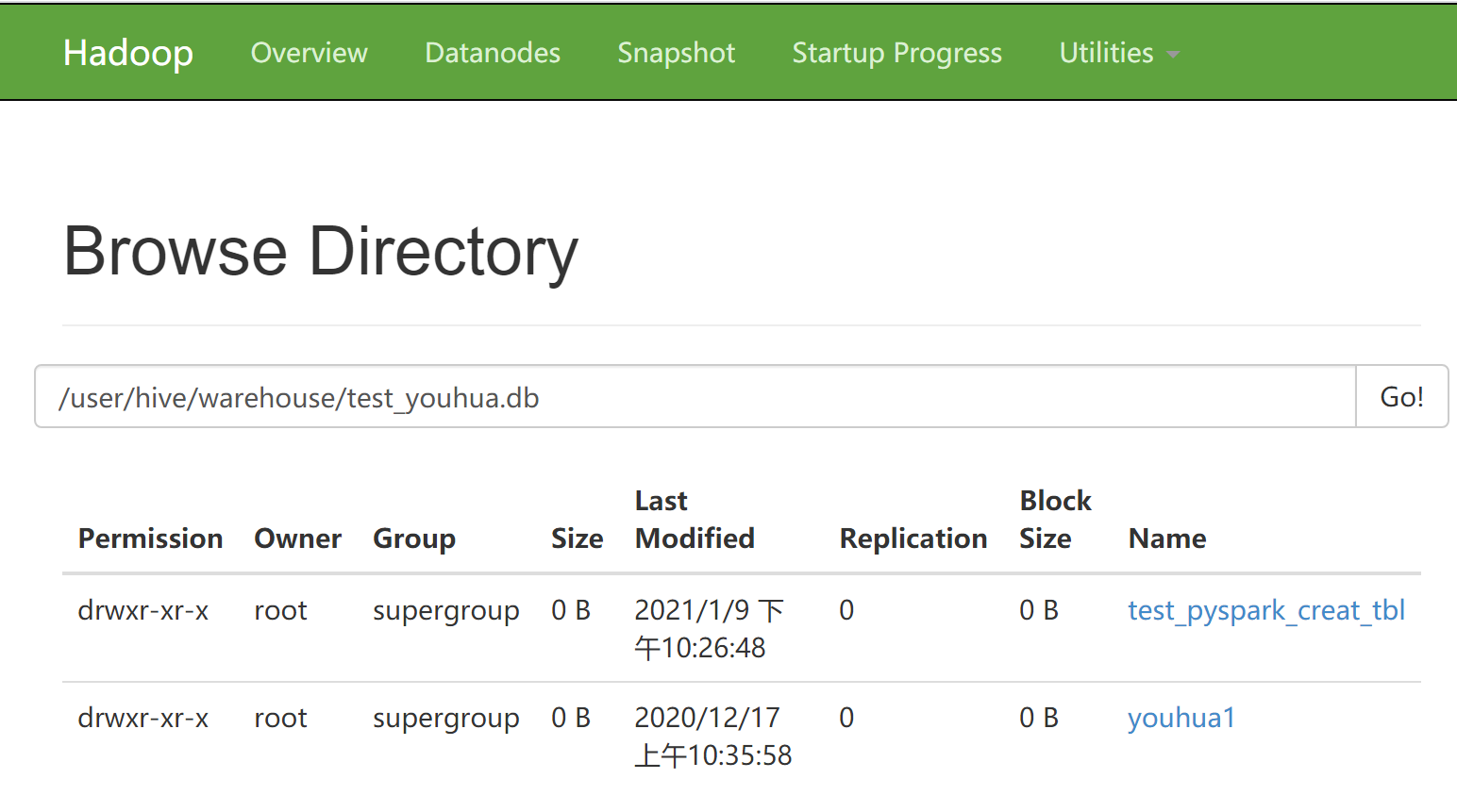
这时去hive库查可以看到已经通过spark操作生成了表 test_youhua.test_pyspark_creat_tbl
[root@hadoop02 hive]# bin/hive ls: 无法访问/opt/module/spark/lib/spark-assembly-*.jar: 没有那个文件或目录 Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties hive> show databases; OK default test_youhua Time taken: 0.903 seconds, Fetched: 2 row(s) hive> use test_youhua; OK Time taken: 0.038 seconds hive> show tables; OK test_pyspark_creat_tbl youhua1 Time taken: 0.028 seconds, Fetched: 2 row(s)
如果不想每次都手动添加驱动地址这么麻烦,可以在spark-defaults.conf里配置:
spark.executor.extraClassPath /opt/module/hive/lib/mysql-connector-java-5.1.27-bin.jar spark.driver.extraClassPath /opt/module/hive/lib/mysql-connector-java-5.1.27-bin.jar
测试提交操作
先写好
[root@hadoop02 spark]# vim input/test_pyspark_hive.py
import pyspark from pyspark.sql import SparkSession from pyspark import SparkConf,SparkContext from pyspark.sql import HiveContext sc=SparkSession.builder.master("local") .appName('first_name') .config('spark.executor.memory','2g') .config('spark.driver.memory','2g') .enableHiveSupport() .getOrCreate() hive_sql=HiveContext(sc) hive_sql.sql(''' create table test_youhua.test_spark_create_tbl1 like test_youhua.youhua1 ''') hive_sql.sql(''' insert overwrite table test_youhua.test_spark_create_tbl1 select * from test_youhua.youhua1 ''')
再提交
[root@hadoop02 spark]# spark-submit input/test_pyspark_hive.py
可以看到操作成功:
