先在我的集群上安装python3:
[root@hadoop02 module]# yum install python3
再安装jupyter:
pip3 install jupyter -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
jupyter在windows上访问
[root@hadoop01 bin]# jupyter notebook --generate-config
Writing default config to: /root/.jupyter/jupyter_notebook_config.py
linux服务器连接jupyternotebook显示服务器拒绝访问。
vim /root/.jupyter/jupyter_notebook_config.py
修改jupyter_notebook_config.py文件:
c.NotebookApp.allow_credentials = True(默认为False)允许远程连接。
修改jupyter默认文件夹:
jupyter-notebook --generate-config
安装python3 的pyspark包
在安装一些包经常超时报错,解决方法:
pip3 install pyspark -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
(其中的Pyinstaller是你需要下载的库或包名,根据自己需求自行更改即可)
这时发现集群登录bin/pyspark报错Error initializing SparkContext
ERROR spark.SparkContext: Error initializing SparkContext. java.io.FileNotFoundException: File file:/tmp/spark-events does not exist
报错原因:spark日志的目录原因,解决参考:
https://blog.csdn.net/weixin_34049948/article/details/93035958
先在hdfs下创建log存放的目录:
hdfs dfs -ls /tmp
hdfs dfs -mkdir /tmp/spark_log
vim spark-defaults.conf
我没有命名空间,添加hdfs统一目录:
spark.eventLog.dir hdfs:// /tmp/spark_log
默认:#spark.eventLog.dir hdfs://hadoop02:8021/directory
vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs:// /tmp/spark_log"
默认export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10"
重新登录正常:
[root@hadoop02 spark]# bin/pyspark Python 2.7.5 (default, Apr 2 2020, 13:16:51) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux2 Type "help", "copyright", "credits" or "license" for more information. Warning: Ignoring non-spark config property: export=JAVA_HOME=/opt/module/jdk1.8.0_144 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 21/01/09 18:35:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 21/01/09 18:35:28 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_ version 2.1.1 /_/ Using Python version 2.7.5 (default, Apr 2 2020 13:16:51) SparkSession available as 'spark'.
但是jupyter的python3还是无法连接上spark,可以看到当前的pyspark还是依托python2,而因为我之前的操作jupyter其实是基于python3的。想到的解决办法是将spark依托的Python2升级为python3
将spark依托的Python2升级为python3
修改配置文件:/etc/profile
增加一行:
export PYSPARK_PYTHON=python3
刷新:. /etc/profile
这时再登录pyspark可以看到用的python版本变为python3:
[root@hadoop02 spark]# bin/pyspark Python 3.6.8 (default, Nov 16 2020, 16:55:22) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux Type "help", "copyright", "credits" or "license" for more information. Warning: Ignoring non-spark config property: export=JAVA_HOME=/opt/module/jdk1.8.0_144 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 21/01/09 23:23:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable ........................................................ 21/01/09 23:23:24 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_ version 2.1.1 /_/ Using Python version 3.6.8 (default, Nov 16 2020 16:55:22) SparkSession available as 'spark'.
还是不能跑spark
最终jupyter连上pyspark
猜测跑不通与环境变量的设置有关,参考的参数设置文章:
https://zhuanlan.zhihu.com/p/61564648
在/etc/profile新添加了标黄参数:
##SPARK_HOME export SPARK_HOME=/opt/module/spark export PATH=$PATH:$SPARK_HOME/bin export PATH=$PATH:$SPARK_HOME/sbin export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH export PYSPARK_PYTHON=python3
跟着博主的试验:
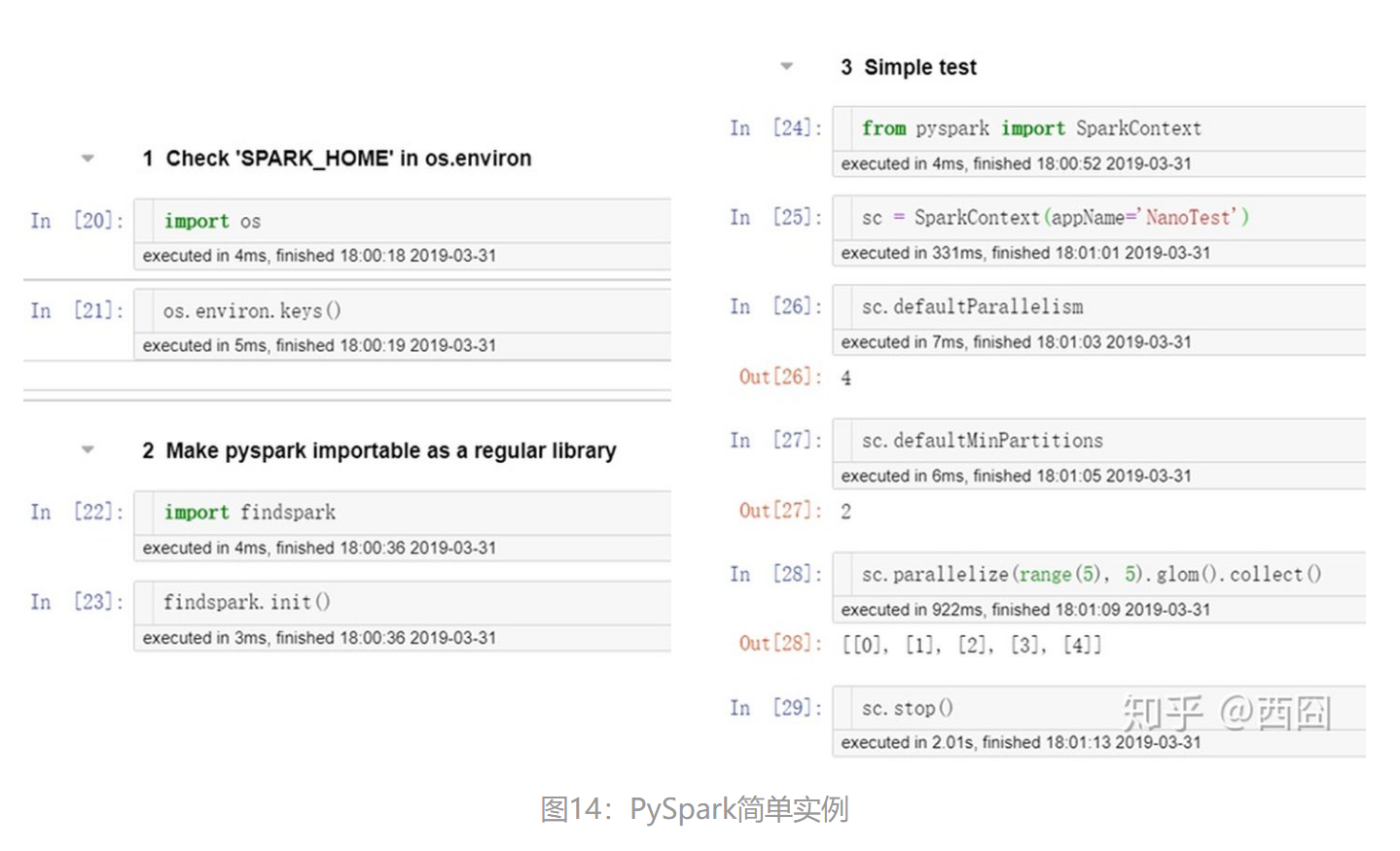
终于跑通:
要记住sc.stop()!!!
不能同时有两个运行的sc

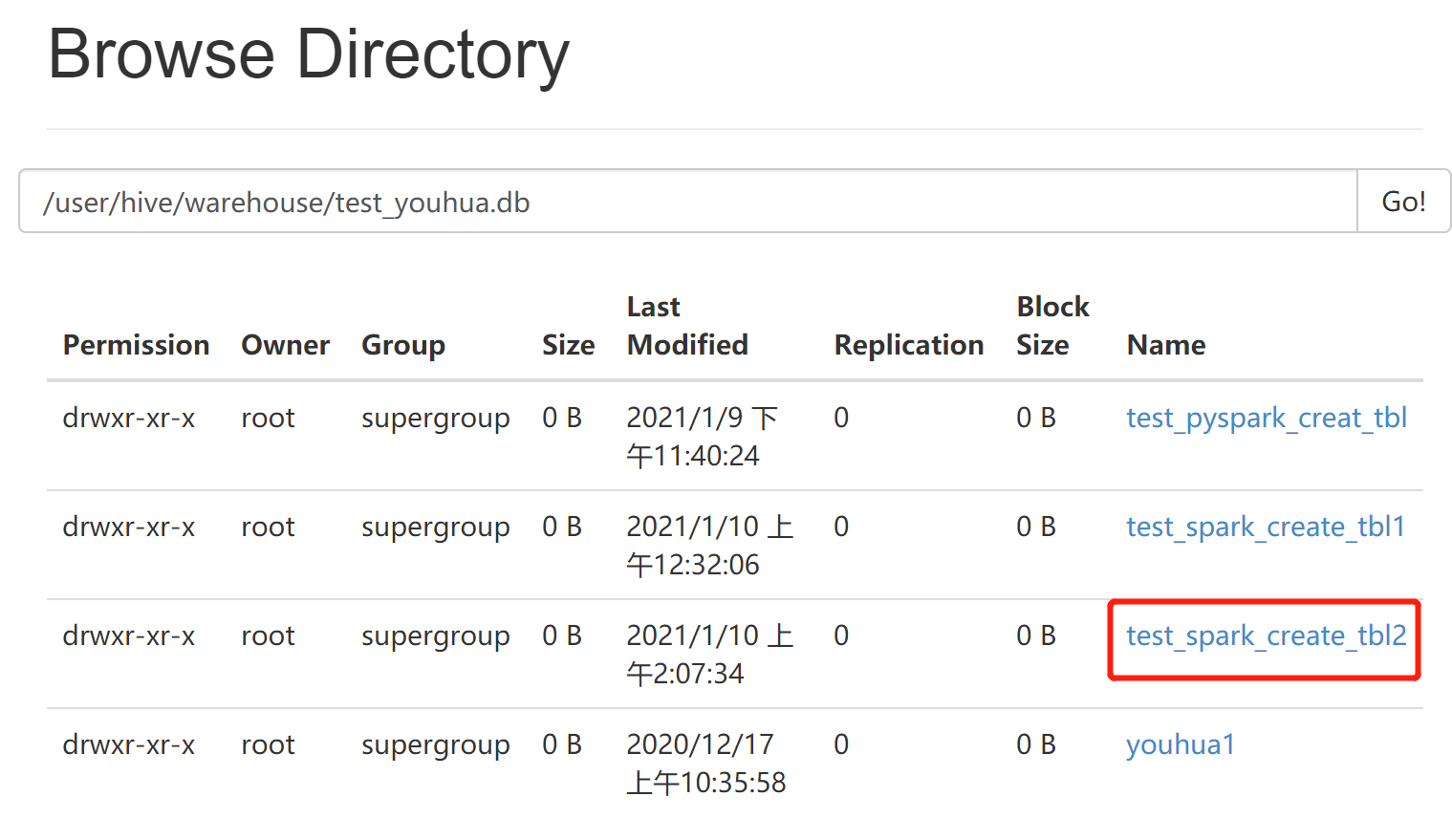
试验(3)中脚本,在jupyter中操作hive库表:
import pyspark from pyspark.sql import SparkSession from pyspark import SparkConf,SparkContext from pyspark.sql import HiveContext sc=SparkSession.builder.master("local") .appName('first_name1') .config('spark.executor.memory','2g') .config('spark.driver.memory','2g') .enableHiveSupport() .getOrCreate() hive_sql=HiveContext(sc) hive_sql.sql(''' create table test_youhua.test_spark_create_tbl2 like test_youhua.youhua1 ''') hive_sql.sql(''' insert overwrite table test_youhua.test_spark_create_tbl2 select * from test_youhua.youhua1 ''')
可以看到成功在hive库建表: