为什么要分析网站结构
在爬虫系统中,待抓取URL队列及队列中URL的排列顺序非常重要。这关系到能否遍历所有的目标页面,关系到抓取页面的先后问题。
树状结构
网站内容以树状结构组织,以一级、二级分类等一层层组织。
以豆瓣电影为例:https://www.douban.com/
1)一级
首先要从电影分类的目录页入口,获取所有电影分类的一级目录:https://movie.douban.com/
2)二级
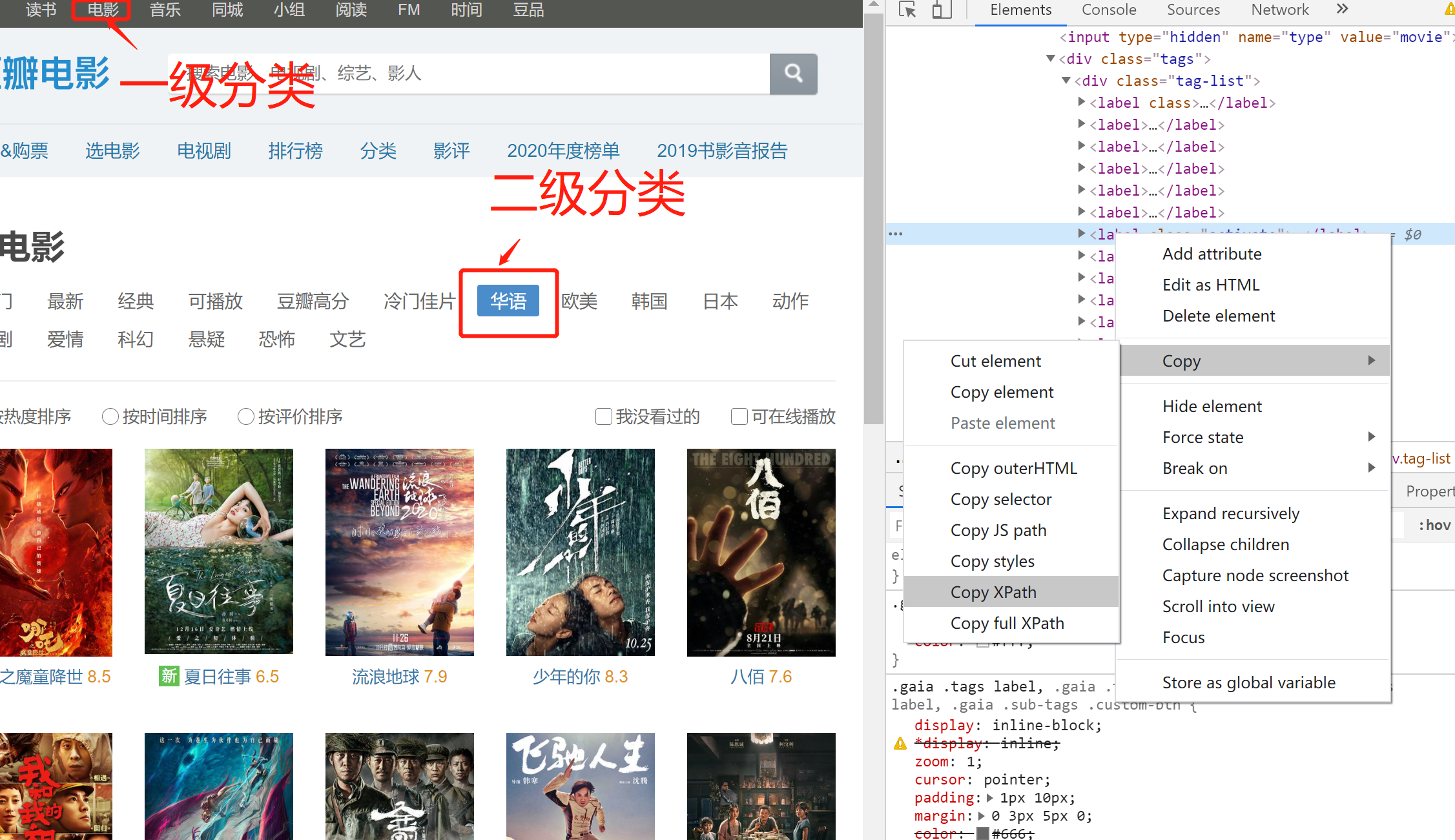
点击选电影之后,首先要找到电影的所有二级标签,按f12进入开发者模式,单击左上角箭头,再点选电影二级分类标签"华语",就可以在页面HTML中找到对应的链接如下图,右键Copy Xpath: //*[@id="content"]/div/div[1]/div/div[2]/div[1]/form/div[1]/div[1]/label[7], 通过这个可以获取与上下文有关的一组Xpath结点。
3)细分
点入二级目录,可以看到所有电影在二级目录下归类,url例如:
https://movie.douban.com/explore#!type=movie&tag=%E5%8D%8E%E8%AF%AD&sort=recommend&page_limit=20&page_start=0
https://movie.douban.com/explore#!type=movie&tag=%E5%8D%8E%E8%AF%AD&sort=recommend&page_limit=20&page_start=20
因此可以用循环去控制。