一、基础操作
1、根据数据信息,创建数据框
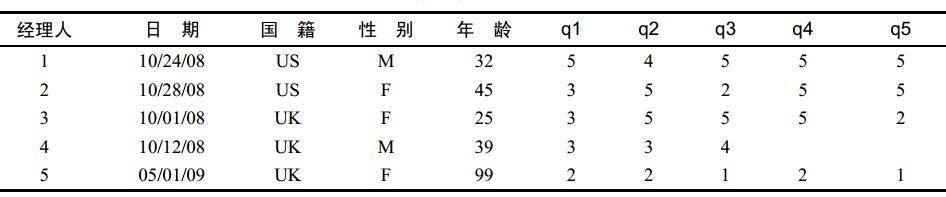
> manager <- c(1,2,3,4,5)
> date <- c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
> country <- c("US","US","UK","UK","UK")
> age <- c(32,45,25,39,99)
> gender <- c("M","F","F","M","F")
> q1 <- c(5,3,3,3,2)
> q2 <- c(4,5,5,3,2)
> q3 <- c(5,2,5,4,1)
> q4 <- c(5,5,5,NA,2)
> q5 <- c(5,5,2,NA,1)
> leadership <- data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors=FALSE)
2、添加列计算某几列的和或平均数
> mydatatest <- data.frame(x1,x2) > mydatatest$sumx <- mydatatest$x1 + mydatatest$x2 > mydatatest$meanx <- (mydatatest$x1+mydatatest$x2)/2
3、变量的重编码
其作用如同sql语句一样,选中特定的数据进行修改,修改值或者类型等
语法:variable[condition] <- expression
> leadership$age[leadership$age == 99] <- NA
4、变量的重命名
> fix(leadership)
或
> library(reshape) > leadership <- rename(leadership,c(manager="managerID",date="testDate"))
或
names(leadership)[3] <- "myCountry"
5、分析中排出缺失值
xx <- c(1,2,NA,3) zz <- sum(xx,na.rm=TRUE)
删除不完整的记录
> newdata <- na.omit(leadership) > newdata managerID testDate myCountry gender age q1 q2 q3 q4 q5 agecat 1 1 10/24/08 US M 32 5 4 5 5 5 Young 2 2 10/28/08 US F 45 3 5 2 5 5 Young 3 3 10/1/08 UK F 25 3 5 5 5 2 Young
6、数据排序
> newdata <- leadership[order(leadership$age),]
age为升序,-age为降序