一、数据结构
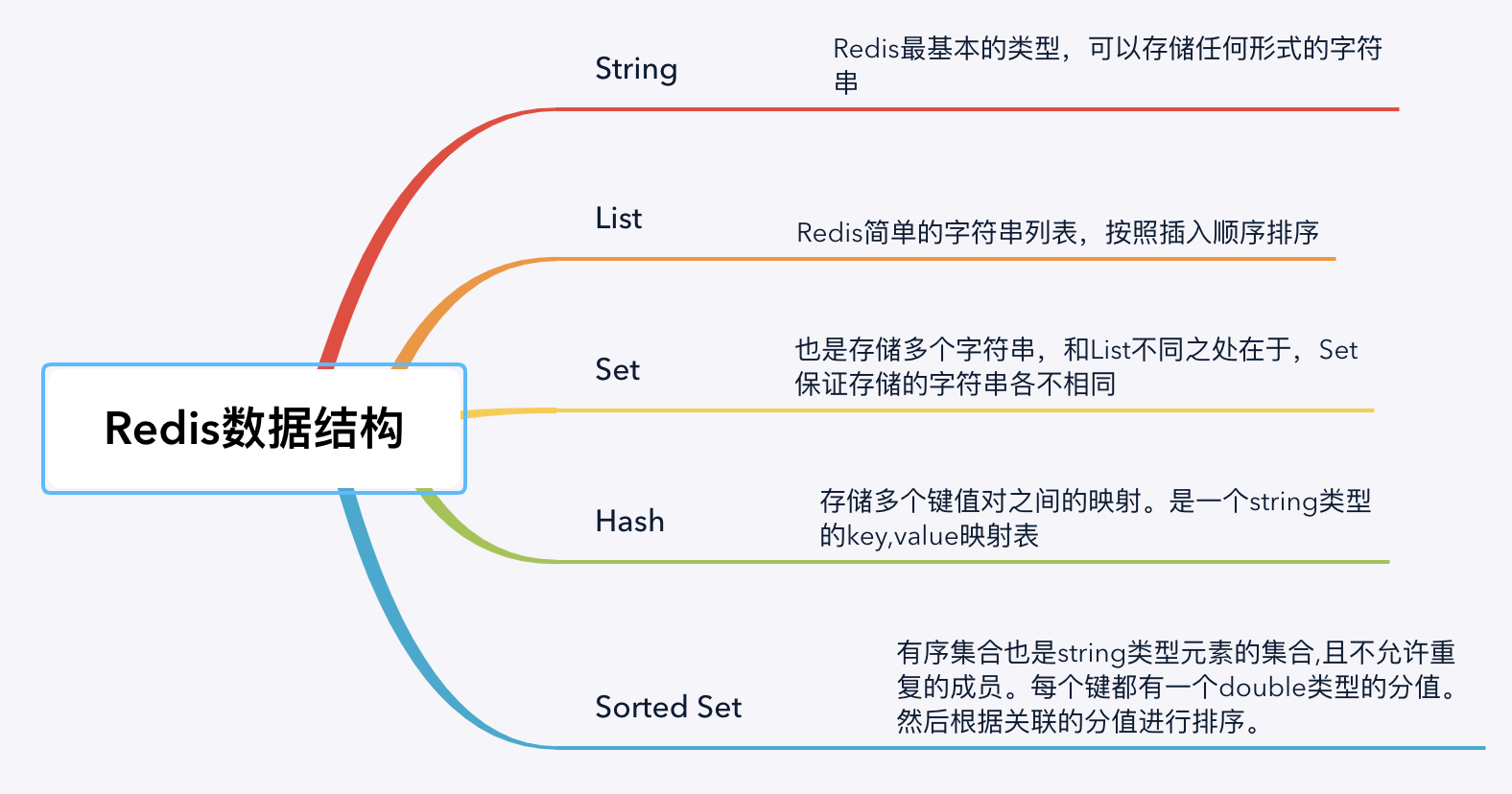
string
Redis字符串是可修改字符串,在内存中以字节数组形式存在。
下面是string在源码中的定义,SDS(Simple Dynamic String)
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位,不理睬它
byte[] content; // 数组内容
}
Redis规定字符串的长度不超过512M。
Redis字符串的两种存储方式:
- 长度特别短,使用emb形式存储
- 长度超过44,使用raw形式存储
扩容策略
字符串长度小于1M之前,扩容采用加倍策略,保留100%的冗余空间。(从源码中可以看到是现有的数组长度len+设定的容量大小capacity)
字符串长度超过1M后,每次扩容只多分配1M大小的冗余空间。
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); // 原字符串长度
// 按需调整空间,如果 capacity 不够容纳追加的内容,就会重新分配字节数组并复制原字符串的内容到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 内存不足
memcpy(s+curlen, t, len); // 追加目标字符串的内容到字节数组中
sdssetlen(s, curlen+len); // 设置追加后的长度值
s[curlen+len] = '�'; // 让字符串以� 结尾,便于调试打印,还可以直接使用 glibc 的字符串函数进行操作
return s;
}
list
Redis的列表常用来做异步队列使用。
右边进,左边出是队列。
rpush books python java golang
lpop books
右边进,右边出是栈。
rpush books python java golang
rpop books
hash
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。
hset books java "think in java"
hgetall books
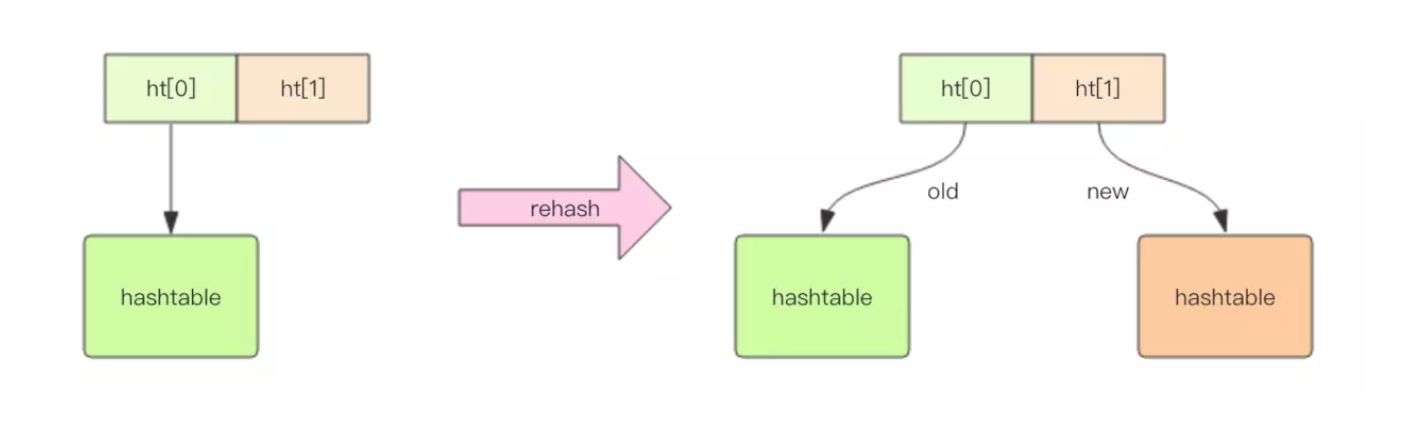
Redis相比于Java的HashMap不同的是,采取了渐进式rehash,为的是不堵塞服务。
什么是渐进式rehash?
创建新的hashtable,同时保留旧的hashtable,并且通过定时任务将旧的hashtable中的key-value转移到新的hashtable,查询时,会同时查询新旧hashtable,等到完全转移完成,再将旧的删除掉。
这里思考一个问题?Java中的rehash,要怎么处理?不是渐进式的,那如何保证在rehash时进行查询,获取到正确的值?
set
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
set 结构可以用来存储活动中奖的用户 ID,因为有去重功能,可以保证同一个用户不会中奖两次
zset
底层实现?
zset类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫做「跳跃列表」的数据结构。
一个操作需要进行读变量,写变量两个步骤,多个相同的操作同时进行就会出现并发问题。因为读取和写入两个变量不是原子操作。
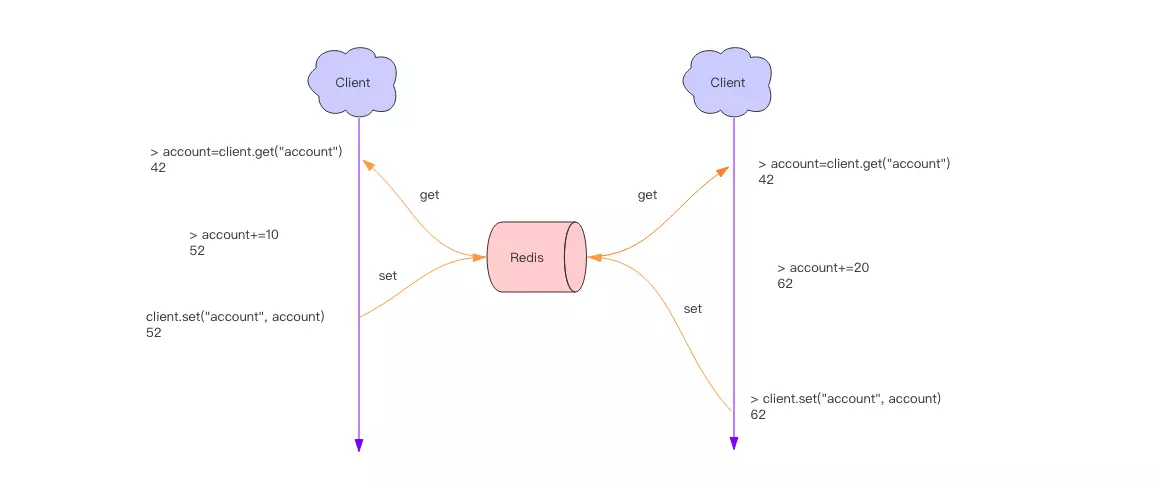
二、分布式锁
分布式锁本质上要实现的目标就是在 Redis 里面占一个“茅坑”,当别的进程也要来占时,发现已经有人蹲在那里了,就只好放弃或者稍后再试。
占坑一般是使用 setnx(set if not exists) 指令,只允许被一个客户端占坑。先来先占, 用完了,再调用 del 指令释放茅坑。
加锁
setnx lock:a true
释放锁
del lock:a
为了避免加锁后,中间操作出现异常,最后没有释放锁的问题,需要给锁设置一个超时时间。
setnx lock:a true
expire lock:a 5
出现另一个问题,上面的操作也有可能失败,例如设置过期时间失败。
为了解决上述的问题,Redis2.8增加了set指令的扩展参数,
set lock:a true ex 5 nx
要确保分布式锁可用,需至少要满足下面四个条件:
- 互斥性:只能一个客户端持有锁
- 不会发生死锁
- 具有容错性
- 解铃还须系铃人
超时问题
如果执行代码的时间太长,超出了锁的超时限制,就会由其他线程获得锁。会导致代码不能严格被执行。为了避免这个情况,进行加锁的执行代码尽量不要选择执行时间过长的。
可重入性
可重入性指的是线程在持有锁的情况下,再次请求加锁。
问题,为何要设计可重入这一个特性?
搞清楚几个概念:可重入锁、公平锁、非公平锁。
可重入锁:
线程1执行 synchronized A()方法,A()方法调用synchronized B()方法,当线程1获取到A方法对应的对象锁之后,再去调用B方法,就不需要重新申请锁。
公平锁:
多个线程等待锁,当锁释放后,等待该锁时间最久的(或者说最先申请锁的),应该获得锁。
非公平锁:
多个线程等待锁,不按照等待锁的时间或申请锁的先后顺序,来获得锁。
三、持久化
- 为什么要持久化
- 如何持久化
为什么要持久化?
因为Redis数据存在内存,若服务器宕机或重启,数据会全部丢失,需要有一种机制保证数据不会因为故障丢失。
Redis是单线程的,而持久化就是说Redis需要将线程用到保存数据到磁盘,并且还要服务客户端的请求,持久化的IO会严重影响性能。
那么Redis是如何解决的?
这里Redis使用了操作系统的 写时复制(Copy On Write)。也就是从原先处理客户端请求的进程中,fork出一个子进程,来进行持久化。
如何持久化?
- 快照
- AOF日志
Copy On Write
(1)fork()函数
父进程执行fork()后,会产生一个子进程。当fork()被调用的时候,会返回两个值。
为什么返回两个值?
因为是两个线程,返回给父线程,子线程的ID;返回给子线程,0。
(2)exec()函数
exec的作用是,替换当前进程的内存空间的映像,从而执行不同的任务。
也就是说,当子进程执行exec后,就不再是父进程的副本了,因为有了独立的内存空间。
四、管道
管道的本质是,将客户端与服务端的交互,由写—— 读 —— 写 —— 读,变为 写—— 写—— 读——读,是由客户端提供的技术。
两个连续的写操作和两个连续的读操作总共只会花费一次网络来回,就好比连续的 write 操作合并了,连续的 read 操作也合并了一样。
五、位图
使用bit来存储数据,例如一周的签到,可以使用 7个位来表示,签到了的用1标记,未签到的用0标记。
设置与获取
设置
127.0.0.1:6379> setbit week 1 1
(integer) 0
127.0.0.1:6379> setbit week 2 0
(integer) 0
127.0.0.1:6379> setbit week 3 0
(integer) 0
127.0.0.1:6379> setbit week 4 0
(integer) 0
获取
127.0.0.1:6379> getbit week 4
(integer) 0
统计
bitcount name start end,其中的start和end的单位是byte,也就是8个bit。
例如bitcount s 0 0统计的是第一个字符,也就是第一个8位的存在的1的个数
127.0.0.1:6379> bitcount week 0 0
(integer) 1
六、通信协议与简单Jedis-Client的实现
RESP协议概述
Redis客户端和Redis服务端使用RESP协议进行通信。
这个协议的特点:
- Simple to implement.实现简单
- Fast to parse.快速解析
- Human readable.可读性强
当我写一个socket程序,去拦截Jedis客户端发送的请求,程序如下:
public class JedisSocket {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(6379);
Socket socket = serverSocket.accept();
byte[] bytes = new byte[2048];
socket.getInputStream().read(bytes);
System.out.println(new String(bytes));
} catch (IOException e) {
e.printStackTrace();
}
}
}
得到如下结果:
*3
$3
SET
$4
name
$3
fon
$后面表示的是字符串长度。set的长度是3,name是4,fon是3,*号后面的数字,代表共有3组数据。这就是RESP的内容。
Jedis的使用
引入依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.0.1</version>
</dependency>
一个简单的Jedis程序
public class JedisTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.set("name","coffejoy");
String str = jedis.get("name");
System.out.println(str);
//关闭连接
jedis.close();
}
}
使用Jedis连接池
interface CallWithJedis {
void call(Jedis jedis);
}
class RedisPool {
private JedisPool pool;
public RedisPool() {
this.pool = new JedisPool("bei1", 6379);
}
public void execute(CallWithJedis caller) {
Jedis jedis = pool.getResource();
try {
caller.call(jedis);
} catch (JedisConnectionException e) {
caller.call(jedis); // 重试一次
} finally {
jedis.close();
}
}
}
class Holder<T> {
private T value;
public Holder() {
}
public Holder(T value) {
this.value = value;
}
public void value(T value) {
this.value = value;
}
public T value() {
return value;
}
}
public class JedisPoolTest {
public static void main(String[] args) {
RedisPool redis = new RedisPool();
Holder<Long> countHolder = new Holder<>();
redis.execute(jedis -> {
String name = jedis.get("name");
System.out.println(name);
});
System.out.println(countHolder.value());
}
}
实现一个Jedis客户端程序
public class FonJedis {
//客户端set方法
private static String set(Socket socket, String key, String value) throws IOException {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("*3").append("
");
stringBuffer.append("$3").append("
");
stringBuffer.append("set").append("
");
stringBuffer.append("$").append(key.getBytes().length).append("
");
stringBuffer.append(key).append("
");
stringBuffer.append("$").append(value.getBytes().length).append("
");
stringBuffer.append(value).append("
");
socket.getOutputStream().write(stringBuffer.toString().getBytes());
byte[] response = new byte[2048];
socket.getInputStream().read(response);
return new String(response);
}
//客户端get方法
public static String get(Socket socket, String key) throws IOException {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("*2").append("
");
stringBuffer.append("$3").append("
");
stringBuffer.append("get").append("
");
stringBuffer.append("$").append(key.getBytes().length).append("
");
stringBuffer.append(key).append("
");
socket.getOutputStream().write(stringBuffer.toString().getBytes());
byte[] response = new byte[2048];
socket.getInputStream().read(response);
return new String(response);
}
public static void main(String[] args) {
try {
Socket socket = new Socket("bei1", 6379);
FonJedis.set(socket, "name", "coffejoy");
String value = FonJedis.get(socket, "name");
System.out.println(value);
} catch (IOException e) {
e.printStackTrace();
}
}
}
七、主从同步
CAP原理
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的,这意味着必然会有网络断开的风险,这个网络断开的场景的专业词汇叫着「网络分区」。
在网络分区发生时,两个分布式节点之间无法进行通信,我们对一个节点进行的修改操作将无法同步到另外一个节点,所以数据的「一致性」将无法满足,因为两个分布式节点的数据不再保持一致。除非我们牺牲「可用性」,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的功能,直到网络状况完全恢复正常再继续对外提供服务。
CAP 原理就是——网络分区发生时,一致性和可用性两难全。
最终一致
Redis主从节点是通过异步的方式来同步数据的,所以是不满足一致性的。即使在主从两个节点产生分区,依然满足可用性,因为查询和修改都是在主节点进行。Redis保证最终一致性,就是从节点的数据会努力与主节点的数据保持一致。
增量同步与快照同步
增量同步
主节点将修改性指令放到buffer中,然后异步传输给从节点,从节点一遍执行指令,另一边需要告诉主节点执行到哪里。
快照同步
是一种比较耗资源的操作。主节点将当前数据存储到磁盘文件中,然后发送给从节点,从节点读取快照文件中的数据,读取完成后,执行增量同步。
八、常见问题及解决方案