一、操作数据库(以SQLite3为例)
SQLite3 可使用 sqlite3 模块与 Python 进行集成。它提供了一个与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。我们不需要单独安装该模块,因为 Python 2.5.x 以上版本默认自带了该模块。 为了使用 sqlite3 模块,首先必须创建一个表示数据库的连接对象,然后可以有选择地创建光标对象,这将帮助执行所有 的 SQL 语句。

二.自己设计大学排名-数据库实践
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed May 29 23:13:27 2019
@author: @foldline
"""
import requests
import csv
import os
from bs4 import BeautifulSoup
alluniv = []
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return "error"
def fillunivlist(soup):
data=soup.find_all('tr')
for tr in data:
ltd =tr.find_all('td')
if len(ltd)==0:
continue
singleuniv=[]
for td in ltd:
singleuniv.append(td.string)
alluniv.append(singleuniv)
def writercsv(save_road,num,title):
if os.path.isfile(save_road):
with open(save_road,'a',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
for i in range(num):
u=alluniv[i]
csv_write.writerow(u)
else:
with open('rank.csv','w',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
csv_write.writerow(title)
for i in range(num):
u=alluniv[i]
csv_write.writerow(u)
title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化"]
save_road="D:Anaconda
ank.csv"
def main(num):
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html"
html=getHTMLText(url)
soup=BeautifulSoup(html,"html.parser")
fillunivlist(soup)
writercsv(save_road,10,title)
main(10)
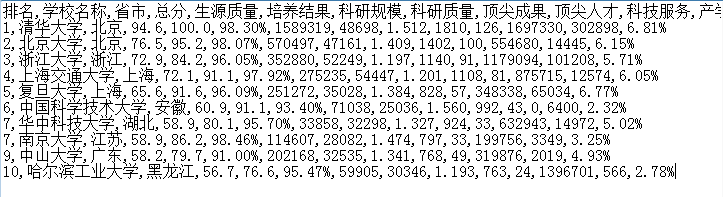
结果如下: