作为 inference 部分的小结,我们这里对 machine learning 里面常见的三个 model 的 inference 问题进行整理,当然很幸运的是他们都存在 tractable 的算法是的我们避免了烦人的 approximate inference。
HMM
常意所说的 HMM 是对离散状态、离散观测情形下的一种 generative model,它包括
- 状态的先验分布
(在下面的推导中我们可以将其藏在转移概率中)
- 转移状态
,这是对
的分布
- 发射概率
,这是对
的分布
这个模型的潜台词是
- Markovian property:
- time-invariance:
 = Pr (s_t mid s_{t - 1})")
")
因此联合分布的概率为
 = Pr(s_0)prod_{i = 1}^t Pr (s_i mid s_{i - 1}) Pr (o_i mid s_i),")
其中  = 1")
message passing 需要建立一个 cluster graph,当然实际也是一个 clique tree,这个图上的顶点包括 




= Pr (s_i mid s_{i - 1}) Pr (o_i mid s_i), i = 1, ldots, t")
 = sum_{o_1} psi_1 (s_1, s_0, o_1), quad delta_{i o i + 1} (s_i) = sum_{o_i} sum_{s_{i-1}} delta_{i - 1 o i} (s_{i - 1}) psi_i (s_i, s_{i - 1}, o_i)")
其中 
 = sum_{s_t} sum_{o_t} phi_t (s_t, s_{t - 1}, o_t) , quad delta_{i o i-1} (s_{i - 1}) = sum_{s_i} sum_{o_i} delta_{i+1 o i} (s_i) psi_i (s_i, s_{i - 1}, o_i)")
其中 
 = sum_{o_1} psi_1 (s_1, s_0, o_1) = sum_{o_1} Pr (s_1mid s_0) Pr (o_1 mid s_1) = Pr (s_1) = pi_{s_1}")
我们可以继续代入后面的消息里面,
 = sum_{s_i} sum_{o_i} delta_{i - 1 o i} (s_i) psi_i (s_i, s_{i - 1}, o_i)= sum_{o_{i - 1}} sum_{o_i} Pr (s_{i - 1}) Pr (s_imid s_{i - 1}) Pr (o_i mid s_i) = Pr(s_i)")
如果观测是给定的,即 
")
 = sum_{s_t} sum_{o_t} phi_t (s_t, s_{t - 1}, o_t) = sum_{s_t} sum_{o_t} Pr (s_t mid s_{t - 1}) Pr (o_t mid s_t) equiv 1")
代入后面的消息有
 = sum_{s_i} sum_{o_i} delta_{i+1 o i} (s_i) psi_i (s_i, s_{i - 1}, o_i) = sum_{s_i} delta_{i+1 o i} Pr (s_i mid s_{i - 1}) equiv 1")
都是常数。如果 是已知的,这将获得
")
对于 MAP 类型的 query,我们需要使用 max-product 算法,此时的前向消息为(")
 = max_{o_1} psi_1 (s_1, s_0, o_1) = pi_{s_1} e_{s_1}")
且
 = max_{o_i} max_{s_{i-1}} delta_{i - 1 o i} (s_{i - 1}) psi_i (s_i, s_{i - 1}, o_i) = e_{s_i} max_k delta_{i-1 o i} (k) au(k, s_i)")
后向消息为
 = max_{s_t} max_{o_t} phi_t (s_t, s_{t - 1}, o_t) = max_k au(s_{t - 1}, k) e_k")
且
 = max_{s_i} max_{o_i} delta_{i+1 o i} (s_i) psi_i (s_i, s_{i - 1}, o_i) = max_k delta_{i+1 o i} (k) au (s_{i - 1}, k) e_k")
对 belief update 来说,belief 是 

而对应的 belief update 为
 = delta_{i o i + 1} (s_i) delta_{i + 1 o i} (s_i) = Pr (s_i)")
类似可以导出 MAP 类型下的形式。这样,对于 filtering 来说  propto Pr (s_i, o_{0, ldots, i})")
 = sum_{s_i} Pr (s_{i + 1}, s_i mid o_{0, ldots, i}) = sum_{s_i} Pr (s_{i + 1} mid s_i) Pr (s_i mid o_{0, ldots, i}) = sum_k au (k, s_{i + 1}) Pr (s_i mid o_{0, ldots, i})")
是归一化后的值。smoothing 需要求 ")
")
LDS
LDS 和 HMM 具有类似的图结构,但是对应的状态和观测均为连续分布,因而常使用 Gaussian 建模。
=Pr (s_0) prod_{i = 1}^{t - 1} Pr (s_i mid s_{i - 1}) Pr(o_i mid s_i)")
其中,
sim N(cdot midmu_0, Gamma_0), quad Pr(s_i mid s_{i - 1}) sim N (cdot mid A s_{i - 1}, Gamma), quad Pr (o_i mid s_i) sim N (cdot mid C s_i, Sigma)")
另一种描述这种关系的形式是使用 additive noise,
, quad s_i = A s_{i - 1} + epsilon_i, epsilon_i sim N (cdot mid 0, Gamma), quad o_i = C s_i + xi_i, xi_i sim N (cdot mid 0, Sigma).")
使用的 clique tree 与前面一致,前向消息为
 = iint N (s_0 mid mu_0, Gamma_0) N (s_1 mid As_0, Gamma) Pr (o_1 mid C s_1, Sigma) \, mathrm{d} s_0 mathrm{d} o_0 = N(s_1 mid A mu_0, AGamma_0A^ op + Gamma) = Pr (s_1)")
且
 = iint delta_{i-1 o i} (s_{i - 1}) N (s_i mid As_{i - 1}, Gamma) Pr (o_i mid C s_i, Sigma) \, mathrm{d} s_{i - 1} mathrm{d} o_i = N(s_i mid A mu_{i - 1}, AGamma_{i - 1}A^ op + Gamma) = Pr (s_i),")
其中 

 = max_{s_0} N (s_0 mid mu_0, Gamma_0) N (s_1 mid A s_0, Gamma) N (o_1 mid Cs_1, Sigma)")
关于 
^{-1} s_0 - 2 (mu_0^ op Gamma_0^{-1} + s_1^ op Gamma^{-1} A)s_0")
其解为
^{-1} (Gamma_0^{-1} mu_0 + A^ op Gamma^{-1} s_1)")
这是 


beliefs 为
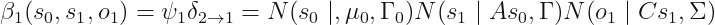
且
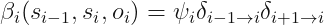
类似有对应 belief。
对 filtering 问题,给定 
")
 propto int Pr (s_0) Pr (s_1mid s_0) Pr(o_1 mid s_1) \, mathrm{d} s_0 = N (s_1 mid Amu_0, AGamma_0 A^ op + Gamma) N (o_1 mid Cs_1, Sigma) propto N (s_1 mid xi_1, Lambda_1)")
其中,
^{-1}, quad xi_1= Lambda_1 (Gamma_1^{-1} mu_1 + C^ op Sigma^{-1} o_1)")
且
 proptoint Pr (s_{i - 1} mid o_{1, ldots, i - 1}) Pr (s_imid s_{i - 1} Pr(o_i mid s_i)\,mathrm{d} s_{i - 1} = N (s_i mid Axi_{i - 1}, ALambda_{i - 1} A^ op + Gamma) N (o_i mid Cs_i, Sigma propto N (s_i mid xi_i, Lambda_i),")
其中
^{-1}, quad xi_i = Lambda_i (Lambda_{i - 1}^{-1} xi_{i - 1} + C^ op Sigma^{-1} o_i).")
令 

对 prediction 问题,给定 ")
 = int Pr (s_{i + 1} mid s_i) Pr (s_i mid o_{1, ldots, i})\, mathrm{d} s_i = int N (s_{i + 1} mid A s_i, Gamma) N (s_i mid xi_i, Lambda_i) \,mathrm{d} s_i = N (s_{i + 1} mid A xi_i, ALambda_iA^ op + Gamma).")
MEMM
我们直接对 ")
")
 = prod_{i = 1}^t Pr_{s_{i - 1}} (s_imid o_i).")
这里的假定有,
- Markovian 性:
,
- ME 假定:
 = Pr_{s_{i - 1}} (s_i mid o_i) = p_{s_{i - 1}} (s_i mid o_i)")
我们使用与 HMM 一致的 cluster graph,前向消息为
 = p_{s_0} (s_1 mid o_1), quad delta_{i o i+1} (s_i) = sum_{s_{i-1}} delta_{i-1 o i} (s_{i - 1}) psi_i = sum_{s_{i - 1}} delta_{i-1 o i} (s_{i - 1}) p_{s_{i-1}} (s_i mid o_i).")
后向消息为
 = sum_{s_t} p_{s_{t - 1}} (s_t mid o_t), quad delta_{i o i-1} (s_{i - 1}) = sum_{s_i} delta_{i + 1 o i} (s_i) p_{s_{i - 1}} (s_i mid o_i).")
max-product message passing 仅仅需要将求和换成 max。belief propagation 中 belief 为

且 belief update 为
其 filtering、prediction 和 smoothing 算法与 HMM 完全一样。
CRF
其假设为
- Markovian 性,与 MEMM 类似;
- invariant factor:对每个 transition,我们引入一个 log-linear 表示,
,其中
是所谓的 feature;
类似前面可以定义消息、belief 等。如果需要计算 log-likelihood,我们需要求 partition function 的函数值,这需要使用前向消息
 = sum_{o_{1, ldots, t}} prod_{i = 1}^t expleft( sum_j lambda_j f_j (s_i, o_i, s_{i - 1})
ight),")
就能避免指数求和项,而计算梯度的时候,
 - langle f_j (s_i, o_i, s_{i - 1})
angle,")
其中后者需要 ")
——————
And Sarah saw the son of Hagar the Egyptian, which she had born to Abraham, mocking.