JSX实现条件渲染
渲染一个列表。但是需要满足:列表为空数组时,显示空文案“Sorry,the list is empty”。同时列表数据可能通过网络获取,存在列表没有初始值为 null 的情况。
最简单的方式:三目运算
const list = ({list}) => {
const isNull = !list
const isEmpty = !isNull && !list.length
return (
<div>
{
isNull
? null
: (
isEmpty
? <p>Sorry, the list is empty </p>
: <div>
{
list.map(item => <ListItem item={item} />)
}
</div>
)
}
</div>
)
}
但是我们多加了几个状态:加上出现错误时,正在加载时的逻辑,三目运算符嵌套地狱就出现了,破解这种地狱的方法有两种:
抽离出render function:
const getListContent = (isLoading, list, error) => { console.log(list) console.log(isLoading) console.log(error) // ... return ... } const list = ({isLoading, list, error}) => { return ( <div> { getListContent(isLoading, list, error) } </div> ) }
IIFE:
const list = ({isLoading, list, error}) => {
return (
<div>
{
(() => {
console.log(list)
console.log(isLoading)
console.log(error)
if (error) {
return <span>Something is wrong!</span>
}
if (!error && isLoading) {
return <span>Loading...</span>
}
if (!error && !isLoading && !list.length) {
return <p>Sorry, the list is empty </p>
}
if (!error && !isLoading && list.length > 0) {
return <div>
{
list.map(item => <ListItem item={item} />)
}
</div>
}
})()
}
</div>
)
}
“为什么不能直接在 JSX 中使用 if…else,只能借用函数逻辑实现呢”?实际上,我们都知道 JSX 会被编译为 React.createElement。直白来说,React.createElement 的底层逻辑是无法运行 JavaScript 代码的,而它只能渲染一个结果。因此 JSX 中除了 JS 表达式,不能直接写 JavaScript 语法。准确来讲,JSX 只是函数调用和表达式的语法糖。
虽然 JSX 只是函数调用和表达式的语法糖,但是 JSX 仍然具有强大而灵活的能力。React 组件复用最流行的方式都是在 JSX 能力基础之上的,比如 HoC,比如 render prop 模式:
class WindowWidth extends React.Component { constructor() { super() this.state = { 0 } } componentDidMount() { this.setState( { window.innerWidth }, window.addEventListener('resize', ({target}) => { this.setState({ target.innerWidth }) }) ) } render() { return this.props.children(this.state.width) } } <WindowWidth> { width => (width > 800 ? <div>show</div> : null) } <WindowWidth>
还可以让 JSX 具有 Vue template 的能力:
render() { const visible = true return ( <div> <div v-if={visible}> content </div> </div> ) } render() { const list = [1, 2, 3, 4] return ( <div> <div v-for={item in list}> {item} </div> </div> ) }
this.setState
this.setSate 这个 API,官方描述为:
setState() does not always immediately update the component. It may batch or defer the update until later. This makes reading this.state right after calling setState() a potential pitfall.
既然用词是 may,那么说明 this.setState 一定不全是异步执行,也不全是同步执行的。所谓的“延迟更新”并不是针对所有情况。
实际上, React 控制的事件处理过程,setState 不会同步更新 this.state。而在 React 控制之外的情况, setState 会同步更新 this.state。
控制内外怎么进行定义呢?
onClick() { this.setState({ count: this.state.count + 1 }) } componentDidMount() { document.querySelectorAll('#btn-raw') .addEventListener('click', this.onClick) } render() { return ( <React.Fragment> <button id="btn-raw"> click out React </button> <button onClick={this.onClick}> click in React </button> </React.Fragment> ) }
在这个case当中,id 为 btn-raw 的 button 上绑定的事件,是在 componentDidMount 方法中通过 addEventListener 完成的,这是脱离于 React 事件之外的,因此它是同步更新的。反之,代码中第二个 button 所绑定的事件处理函数对应的 setState 是异步更新的。
异步化
官方提供了这种处理异步更新的方法。其中之一就是 setState 接受第二个参数,作为状态更新后的回调。这会带来的回调地狱问题显而易见。
常见的处理方式是利用生命周期方法,在 componentDidUpdate 中进行相关操作。第一次 setState 进行完后,在其触发的 componentDidUpdate 中进行第二次 setState,依此类推。
但是这样存在的问题也很明显:逻辑过于分散。生命周期方法中有很多很难维护的“莫名其妙操作”,出现“面向生命周期编程”的情况。
解决回调地狱最直接的方案就是将 setState Promise 化:
const setStatePromise = (me, state) => { new Promise(resolve => { me.setState(state, () => { resolve() }) }) }
这只是 patch 做法,也可以修改React 源码:
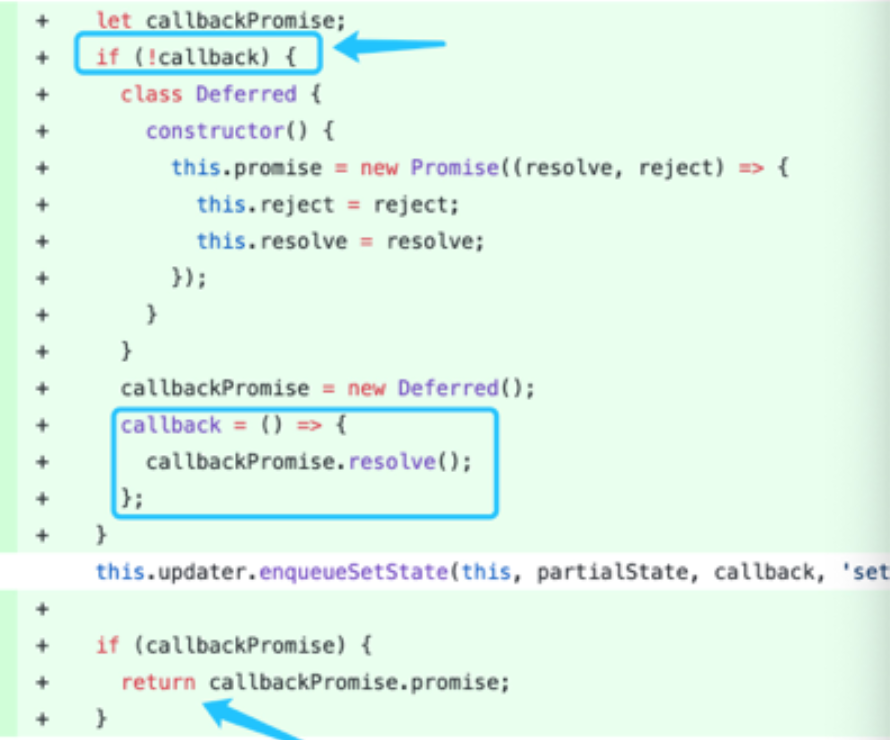
原生事件 VS React 合成事件
React中的事件有以下几个特性:
- React 中的事件机制并不是原生的那一套,事件没有绑定在原生 DOM 上 ,大多数事件绑定在 document 上(除了少数不会冒泡到 document 的事件,如 video 等)
- 同时,触发的事件也是对原生事件的包装,并不是原生 event
- 出于性能因素考虑,合成事件(syntheticEvent)是被池化的。这意味着合成事件对象将会被重用,在调用事件回调之后所有属性将会被废弃。这样做可以大大节省内存,而不会频繁的创建和销毁事件对象。
这样的事件系统设计,无疑性能更加友好,但同时也带来了几个潜在现象。
异步访问事件对象
//我们不能以异步的方式访问合成事件对象: function handleClick(e) { console.log(e) setTimeout(() => { console.log(e) }, 0) } //undefined
React 也贴心的为我们准备了持久化合成事件的方法
function handleClick(e) { console.log(e) e.persist() setTimeout(() => { console.log(e) }, 0) }
如何阻止冒泡
在 React 中,直接使用 e.stopPropagation 不能阻止原生事件冒泡,因为事件早已经冒泡到了 document 上,React 此时才能够处理事件句柄。
componentDidMount() { document.addEventListener('click', () => { console.log('document click') }) } handleClick = e => { console.log('div click') e.stopPropagation() } render() { return ( <div onClick={this.handleClick}> click </div> ) } //div click //document click
但是 React 的合成事件还给使用原生事件留了一个口子,通过合成事件上的 nativeEvent 属性,我们还是可以访问原生事件。原生事件上的 stopImmediatePropagation 方法:除了能做到像 stopPropagation 一样阻止事件向父级冒泡之外,也能阻止当前元素剩余的、同类型事件的执行(第一个 click 触发时,调用 e.stopImmediatePropagtion 阻止当前元素第二个 click 事件的触发)。因此这一段代码:
componentDidMount() { document.addEventListener('click', () => { console.log('document click') }) } handleClick = e => { console.log('div click') e.nativeEvent.stopImmediatePropagation() } render() { return ( <div onClick={this.handleClick}> click </div> ) } //div click
Element diff
react的diff算法,可以参看这篇文章https://www.jianshu.com/p/3ba0822018cf,讲得已经是非常的详细了。
React 三个假设在对比 element 时,存在短板,于是需要开发者给每一个 element 通过提供 key ,这样 react 可以准确地发现新旧集合中的节点中相同节点,对于相同节点无需进行节点删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置。
更新策略
对于以下的情况:
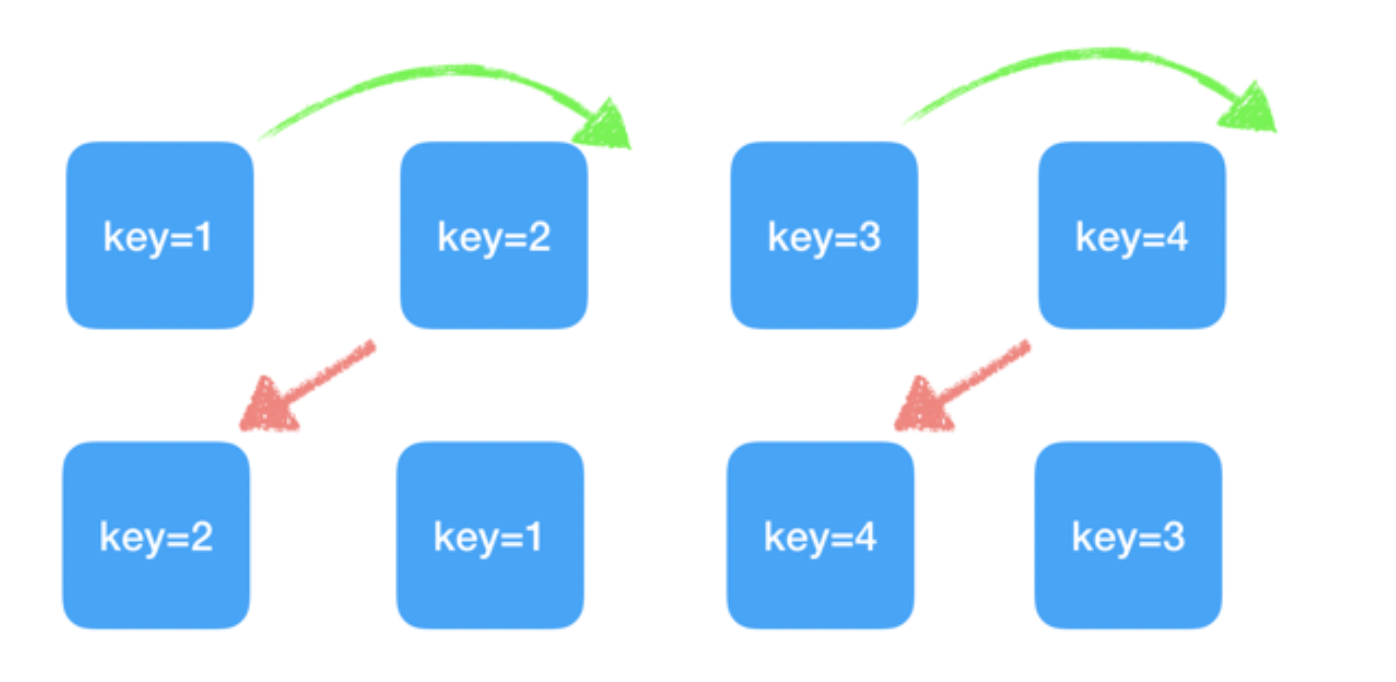
组件 1234,变为 2143,此时 React 给出的 diff 结果为 2,4 不做任何操作;1,3 进行移动操作即可。
也就是元素在旧集合中的位置,相比新集合中的位置更靠后的话,那么它就不需要移动。当然这种 diff 听上去就并非完美无缺的。
但是这样的移动策略在这种情况下代价就变得非常大:
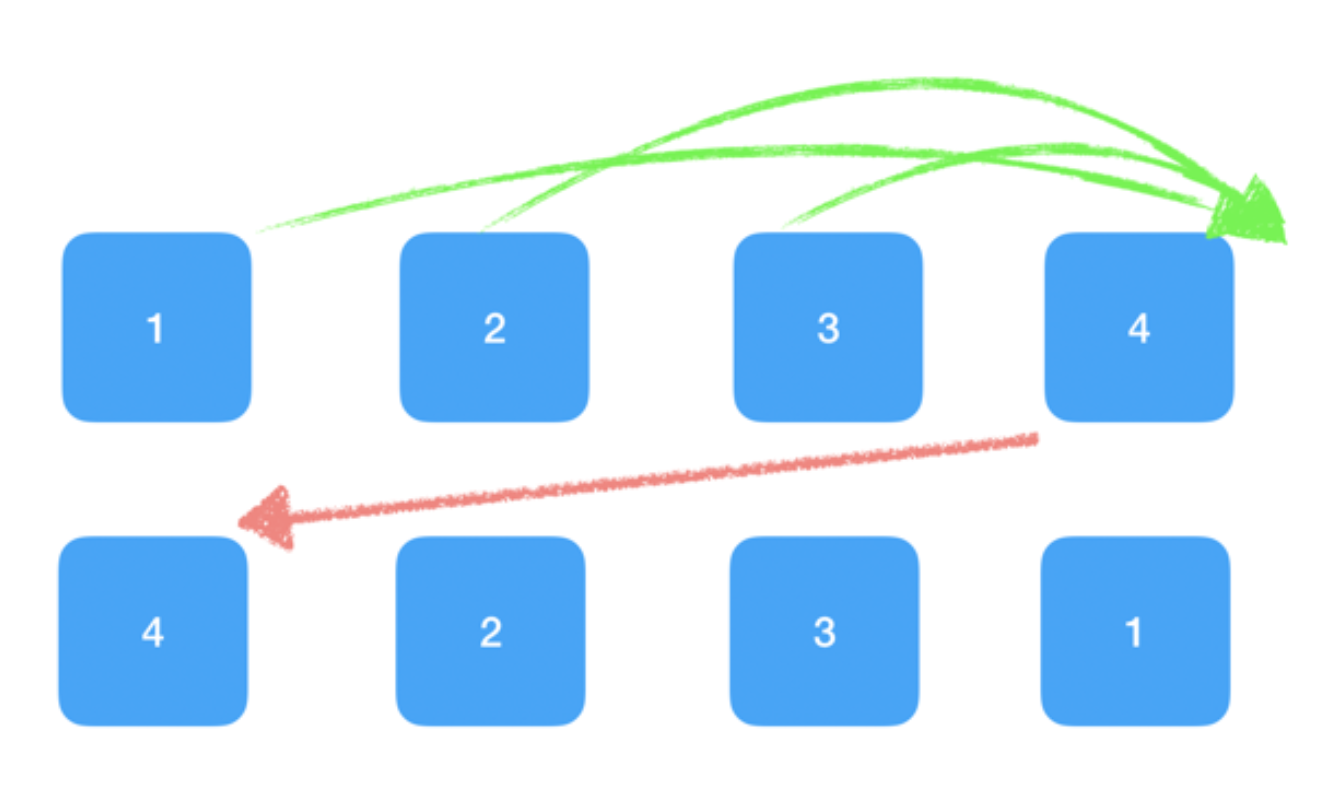
针对这种情况,官方建议:
“在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作。”
key值作用
有一个问题是加了 key 一定要比没加 key 的性能更高吗?
<div id="1">1</div> <div id="2">2</div> <div id="3">3</div> <div id="4">4</div>
对于这种情况,当它变为 [2,1,4,5]:删除了 3,增加了 5,按照之前的算法,我们把 1 放到 2 后面,删除 3,再新增 5。整个操作移动了一次 dom 节点,删除和新增一共 2 处节点。
由于 dom 节点的移动操作开销是比较昂贵的,其实对于这种简单的 node text 更改情况,我们不需要再进行类似的 element diff 过程,只需要更改 dom.textContent 即可。
const startTime = performance.now() $('#1').textContent = 2 $('#2').textContent = 1 $('#3').textContent = 4 $('#4').textContent = 5 console.log('time consumed:' performance.now() - startTime)
这么看,也许没有 key 的情况下要比有 key 的性能更好。